《hello-algo》数组与链表 —— 小记随笔
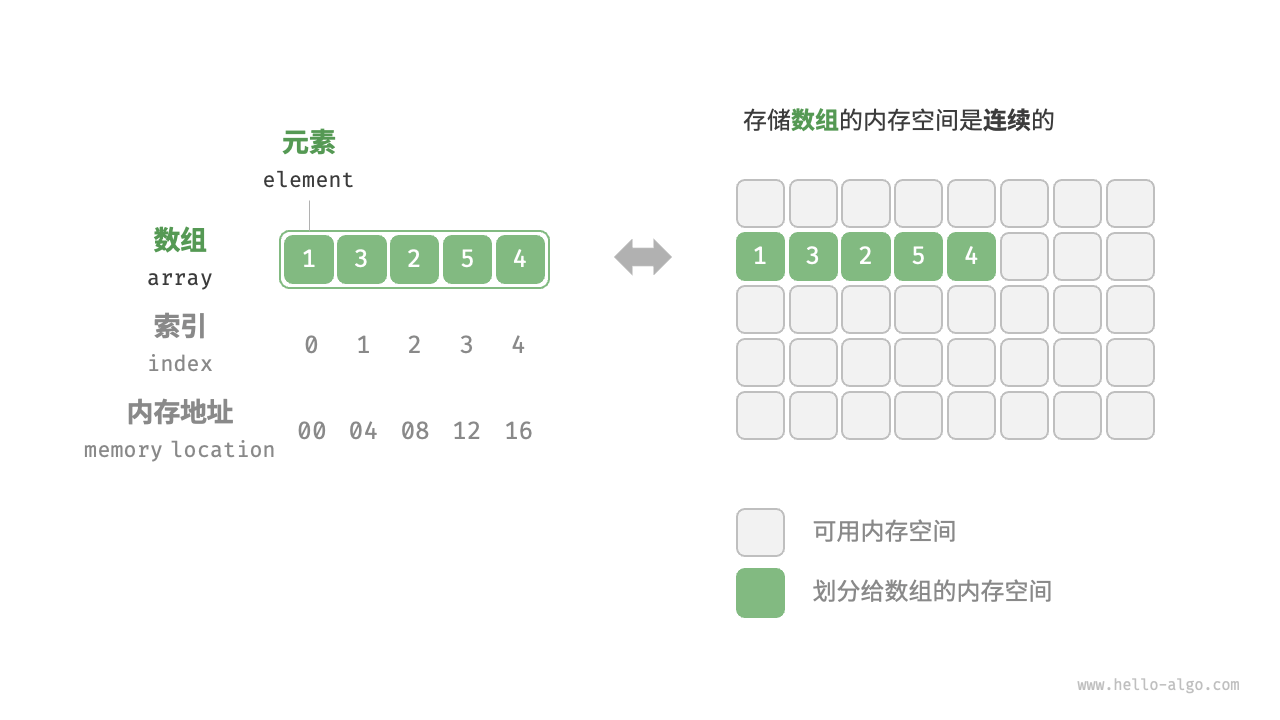
数组
「数组 array」是一种线性数据结构,其将相同类型的元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的「索引 index」
数组常用操作
初始化、访问、插入、删除、遍历、查找、扩容
总的来看,数组的插入与删除操作有以下缺点。
时间复杂度高:数组的插入和删除的平均时间复杂度均为 (O(n)) ,其中 (n) 为数组长度。
- 丢失元素:由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失。
- 内存浪费:我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做会造成部分内存空间浪费。
扩容数组
在复杂的系统环境中,程序难以保证数组之后的内存空间是可用的,从而无法安全地扩展数组容量。因此在大多数编程语言中,数组的长度是不可变的。如果我们希望扩容数组,则需重新建立一个更大的数组,然后把原数组元素依次复制到新数组。这是一个 (O(n)) 的操作,在数组很大的情况下非常耗时。代码如下所示:
/* 扩展数组长度 */
func extend(nums []int, enlarge int) []int {
// 初始化一个扩展长度后的数组
res := make([]int, len(nums)+enlarge)
// 将原数组中的所有元素复制到新数组
for i, num := range nums {
res[i] = num
}
// 返回扩展后的新数组
return res
}
数组的优点与局限性
数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
- 空间效率高:数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问:数组允许在 (O(1)) 时间内访问任何元素。
- 缓存局部性:当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下局限性。
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变:数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费:如果数组分配的大小超过实际所需,那么多余的空间就被浪费了。
数组典型应用
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
- 随机访问:如果我们想随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现随机抽样。
- 排序和搜索:数组是排序和搜索算法最常用的数据结构。快速排序、归并排序、二分查找等都主要在数组上进行。
- 查找表:当需要快速查找一个元素或其对应关系时,可以使用数组作为查找表。假如我们想实现字符到 ASCII 码的映射,则可以将字符的 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
- 机器学习:神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
- 数据结构实现:数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。
链表
内存空间是所有程序的公共资源,在一个复杂的系统运行环境下,空闲的内存空间可能散落在内存各处。我们知道,存储数组的内存空间必须是连续的,而当数组非常大时,内存可能无法提供如此大的连续空间。此时链表的灵活性优势就体现出来了。
「链表 linked list」是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。
链表的设计使得各个节点可以分散存储在内存各处,它们的内存地址无须连续。
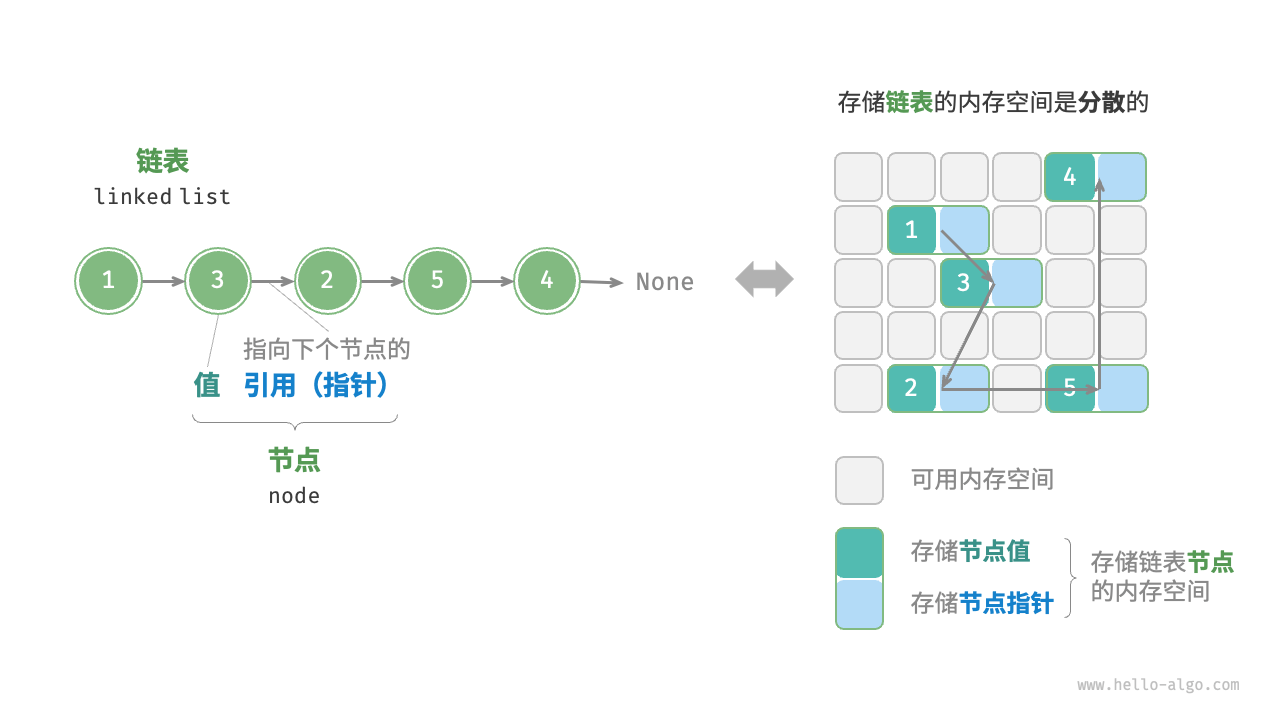
链表节点 ListNode 除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链表比数组占用更多的内存空间。
/* 链表节点结构体 */
type ListNode struct {
Val int // 节点值
Next *ListNode // 指向下一节点的指针
}
// NewListNode 构造函数,创建一个新的链表
func NewListNode(val int) *ListNode {
return &ListNode{
Val: val,
Next: nil,
}
}
链表常用操作
初始化链表
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
n0 := NewListNode(1)
n1 := NewListNode(3)
n2 := NewListNode(2)
n3 := NewListNode(5)
n4 := NewListNode(4)
// 构建节点之间的引用
n0.Next = n1
n1.Next = n2
n2.Next = n3
n3.Next = n4
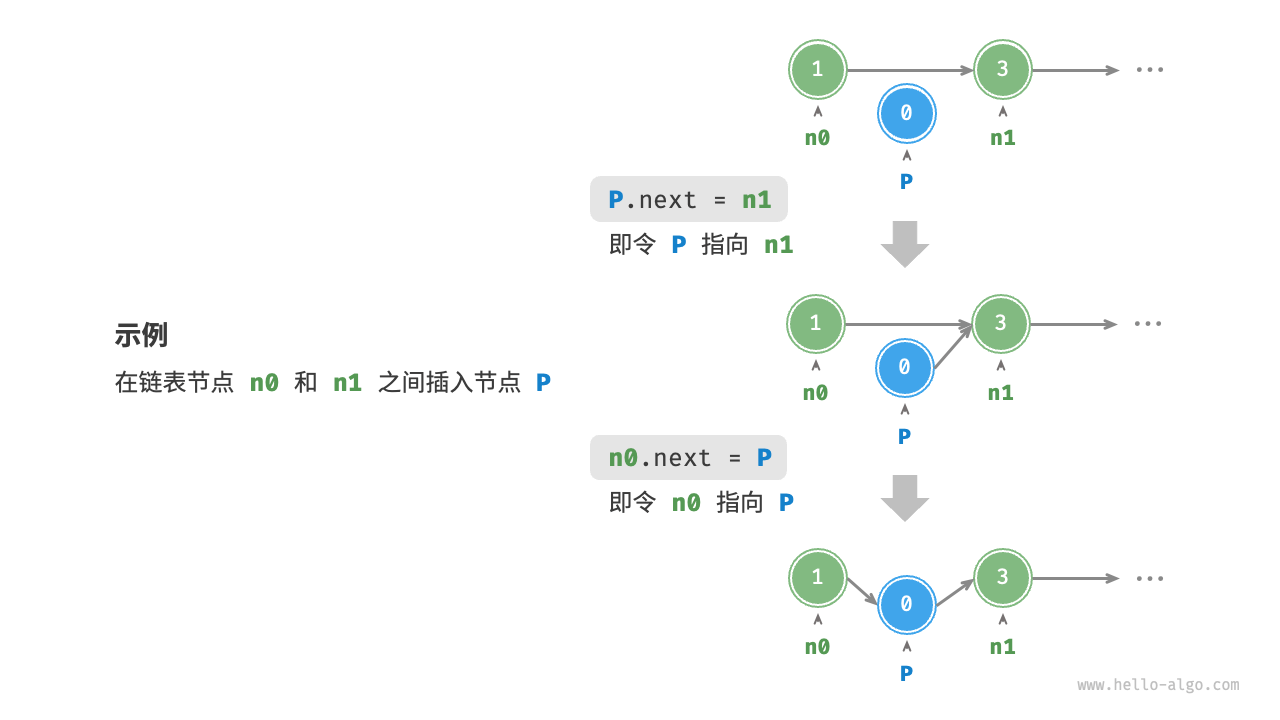
插入节点
/* 在链表的节点 n0 之后插入节点 P */
func insertNode(n0 *ListNode, P *ListNode) {
n1 := n0.Next
P.Next = n1
n0.Next = P
}
删除节点

/* 删除链表的节点 n0 之后的首个节点 */
func removeItem(n0 *ListNode) {
if n0.Next == nil {
return
}
// n0 -> P -> n1
P := n0.Next
n1 := P.Next
n0.Next = n1
}
访问节点
在链表中访问节点的效率较低。如上一节所述,我们可以在 (O(1)) 时间下访问数组中的任意元素。链表则不然,程序需要从头节点出发,逐个向后遍历,直至找到目标节点。也就是说,访问链表的第 (i) 个节点需要循环 (i - 1) 轮,时间复杂度为 (O(n)) 。
/* 访问链表中索引为 index 的节点 */
func access(head *ListNode, index int) *ListNode {
for i := 0; i < index; i++ {
if head == nil {
return nil
}
head = head.Next
}
return head
}
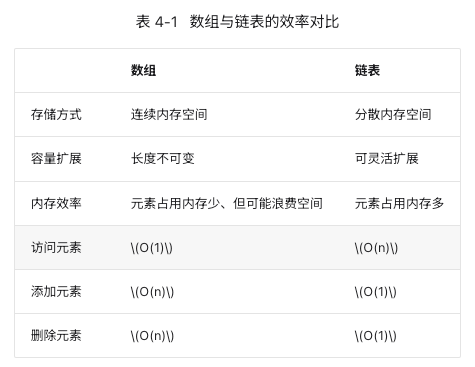
数组 vs. 链表
常见链表类型
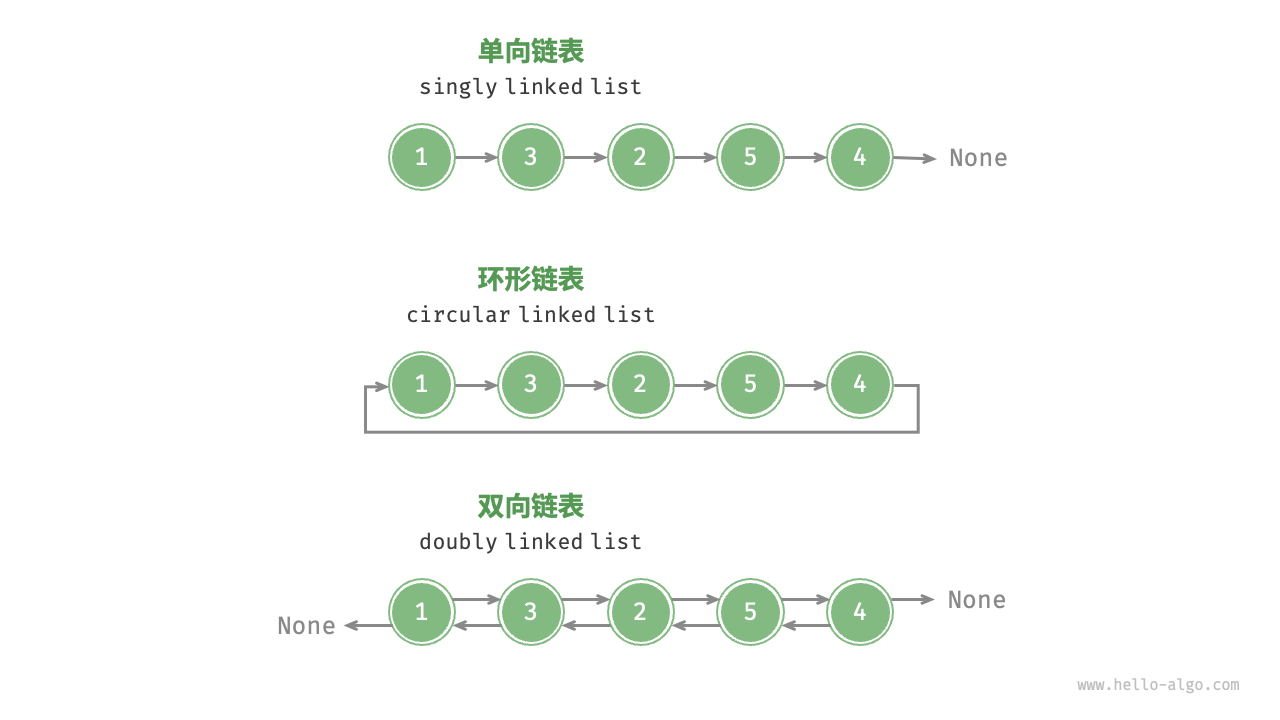
- 单向链表:即前面介绍的普通链表。单向链表的节点包含值和指向下一节点的引用两项数据。我们将首个节点称为头节点,将最后一个节点称为尾节点,尾节点指向空 None 。
- 环形链表:如果我们令单向链表的尾节点指向头节点(首尾相接),则得到一个环形链表。在环形链表中,任意节点都可以视作头节点。
- 双向链表:与单向链表相比,双向链表记录了两个方向的引用。双向链表的节点定义同时包含指向后继节点(下一个节点)和前驱节点(上一个节点)的引用(指针)。相较于单向链表,双向链表更具灵活性,可以朝两个方向遍历链表,但相应地也需要占用更多的内存空间。
链表典型应用
单向链表通常用于实现栈、队列、哈希表和图等数据结构。
- 栈与队列:当插入和删除操作都在链表的一端进行时,它表现出先进后出的特性,对应栈;当插入操作在链表的一端进行,删除操作在链表的另一端进行,它表现出先进先出的特性,对应队列。
- 哈希表:链式地址是解决哈希冲突的主流方案之一,在该方案中,所有冲突的元素都会被放到一个链表中。
- 图:邻接表是表示图的一种常用方式,其中图的每个顶点都与一个链表相关联,链表中的每个元素都代表与该顶点相连的其他顶点。
双向链表常用于需要快速查找前一个和后一个元素的场景。
- 高级数据结构:比如在红黑树、B 树中,我们需要访问节点的父节点,这可以通过在节点中保存一个指向父节点的引用来实现,类似于双向链表。
- 浏览器历史:在网页浏览器中,当用户点击前进或后退按钮时,浏览器需要知道用户访问过的前一个和后一个网页。双向链表的特性使得这种操作变得简单。
- LRU 算法:在缓存淘汰(LRU)算法中,我们需要快速找到最近最少使用的数据,以及支持快速添加和删除节点。这时候使用双向链表就非常合适。
环形链表常用于需要周期性操作的场景,比如操作系统的资源调度。
- 时间片轮转调度算法:在操作系统中,时间片轮转调度算法是一种常见的 CPU 调度算法,它需要对一组进程进行循环。每个进程被赋予一个时间片,当时间片用完时,CPU 将切换到下一个进程。这种循环操作可以通过环形链表来实现。
- 数据缓冲区:在某些数据缓冲区的实现中,也可能会使用环形链表。比如在音频、视频播放器中,数据流可能会被分成多个缓冲块并放入一个环形链表,以便实现无缝播放。
列表
「列表 list」是一个抽象的数据结构概念,它表示元素的有序集合,支持元素访问、修改、添加、删除和遍历等操作,无须使用者考虑容量限制的问题。列表可以基于链表或数组实现。
- 链表天然可以看作一个列表,其支持元素增删查改操作,并且可以灵活动态扩容。
- 数组也支持元素增删查改,但由于其长度不可变,因此只能看作一个具有长度限制的列表。
当使用数组实现列表时,长度不可变的性质会导致列表的实用性降低。这是因为我们通常无法事先确定需要存储多少数据,从而难以选择合适的列表长度。若长度过小,则很可能无法满足使用需求;若长度过大,则会造成内存空间浪费。
为解决此问题,我们可以使用「动态数组 dynamic array」来实现列表。它继承了数组的各项优点,并且可以在程序运行过程中进行动态扩容。
实际上,许多编程语言中的标准库提供的列表是基于动态数组实现的,例如 Python 中的 list 、Java 中的 ArrayList 、C++ 中的 vector 和 C# 中的 List 等。在接下来的讨论中,我们将把“列表”和“动态数组”视为等同的概念。
列表常用操作
初始化列表
/* 初始化列表 */
// 无初始值
nums1 := []int{}
// 有初始值
nums := []int{1, 3, 2, 5, 4}
访问列表
/* 访问元素 */
num := nums[1] // 访问索引 1 处的元素
/* 更新元素 */
nums[1] = 0 // 将索引 1 处的元素更新为 0
插入与删除元素
相较于数组,列表可以自由地添加与删除元素。在列表尾部添加元素的时间复杂度为 (O(1)) ,但插入和删除元素的效率仍与数组相同,时间复杂度为 (O(n)) 。
/* 清空列表 */
nums = nil
/* 在尾部添加元素 */
nums = append(nums, 1)
nums = append(nums, 3)
nums = append(nums, 2)
nums = append(nums, 5)
nums = append(nums, 4)
/* 在中间插入元素 */
nums = append(nums[:3], append([]int{6}, nums[3:]...)...) // 在索引 3 处插入数字 6
/* 删除元素 */
nums = append(nums[:3], nums[4:]...) // 删除索引 3 处的元素
遍历列表
/* 通过索引遍历列表 */
count := 0
for i := 0; i < len(nums); i++ {
count += nums[i]
}
/* 直接遍历列表元素 */
count = 0
for _, num := range nums {
count += num
}
拼接列表
/* 拼接两个列表 */
nums1 := []int{6, 8, 7, 10, 9}
nums = append(nums, nums1...) // 将列表 nums1 拼接到 nums 之后
排序列表
/* 排序列表 */
sort.Ints(nums) // 排序后,列表元素从小到大排列
列表实现
为了加深对列表工作原理的理解,我们尝试实现一个简易版列表,包括以下三个重点设计。
- 初始容量:选取一个合理的数组初始容量。在本示例中,我们选择 10 作为初始容量。
- 数量记录:声明一个变量 size ,用于记录列表当前元素数量,并随着元素插入和删除实时更新。根据此变量,我们可以定位列表尾部,以及判断是否需要扩容。
- 扩容机制:若插入元素时列表容量已满,则需要进行扩容。先根据扩容倍数创建一个更大的数组,再将当前数组的所有元素依次移动至新数组。在本示例中,我们规定每次将数组扩容至之前的 2 倍。
/* 列表类 */
type myList struct {
arrCapacity int
arr []int
arrSize int
extendRatio int
}
/* 构造函数 */
func newMyList() *myList {
return &myList{
arrCapacity: 10, // 列表容量
arr: make([]int, 10), // 数组(存储列表元素)
arrSize: 0, // 列表长度(当前元素数量)
extendRatio: 2, // 每次列表扩容的倍数
}
}
/* 获取列表长度(当前元素数量) */
func (l *myList) size() int {
return l.arrSize
}
/* 获取列表容量 */
func (l *myList) capacity() int {
return l.arrCapacity
}
/* 访问元素 */
func (l *myList) get(index int) int {
// 索引如果越界,则抛出异常,下同
if index < 0 || index >= l.arrSize {
panic("索引越界")
}
return l.arr[index]
}
/* 更新元素 */
func (l *myList) set(num, index int) {
if index < 0 || index >= l.arrSize {
panic("索引越界")
}
l.arr[index] = num
}
/* 在尾部添加元素 */
func (l *myList) add(num int) {
// 元素数量超出容量时,触发扩容机制
if l.arrSize == l.arrCapacity {
l.extendCapacity()
}
l.arr[l.arrSize] = num
// 更新元素数量
l.arrSize++
}
/* 在中间插入元素 */
func (l *myList) insert(num, index int) {
if index < 0 || index >= l.arrSize {
panic("索引越界")
}
// 元素数量超出容量时,触发扩容机制
if l.arrSize == l.arrCapacity {
l.extendCapacity()
}
// 将索引 index 以及之后的元素都向后移动一位
for j := l.arrSize - 1; j >= index; j-- {
l.arr[j+1] = l.arr[j]
}
l.arr[index] = num
// 更新元素数量
l.arrSize++
}
/* 删除元素 */
func (l *myList) remove(index int) int {
if index < 0 || index >= l.arrSize {
panic("索引越界")
}
num := l.arr[index]
// 将索引 index 之后的元素都向前移动一位
for j := index; j < l.arrSize-1; j++ {
l.arr[j] = l.arr[j+1]
}
// 更新元素数量
l.arrSize--
// 返回被删除的元素
return num
}
/* 列表扩容 */
func (l *myList) extendCapacity() {
// 新建一个长度为原数组 extendRatio 倍的新数组,并将原数组复制到新数组
l.arr = append(l.arr, make([]int, l.arrCapacity*(l.extendRatio-1))...)
// 更新列表容量
l.arrCapacity = len(l.arr)
}
/* 返回有效长度的列表 */
func (l *myList) toArray() []int {
// 仅转换有效长度范围内的列表元素
return l.arr[:l.arrSize]
}
内存与缓存
物理结构在很大程度上决定了程序对内存和缓存的使用效率,进而影响算法程序的整体性能。
计算机存储设备

- 硬盘难以被内存取代。首先,内存中的数据在断电后会丢失,因此它不适合长期存储数据;其次,内存的成本是硬盘的几十倍,这使得它难以在消费者市场普及。
- 缓存的大容量和高速度难以兼得。随着 L1、L2、L3 缓存的容量逐步增大,其物理尺寸会变大,与 CPU 核心之间的物理距离会变远,从而导致数据传输时间增加,元素访问延迟变高。在当前技术下,多层级的缓存结构是容量、速度和成本之间的最佳平衡点。

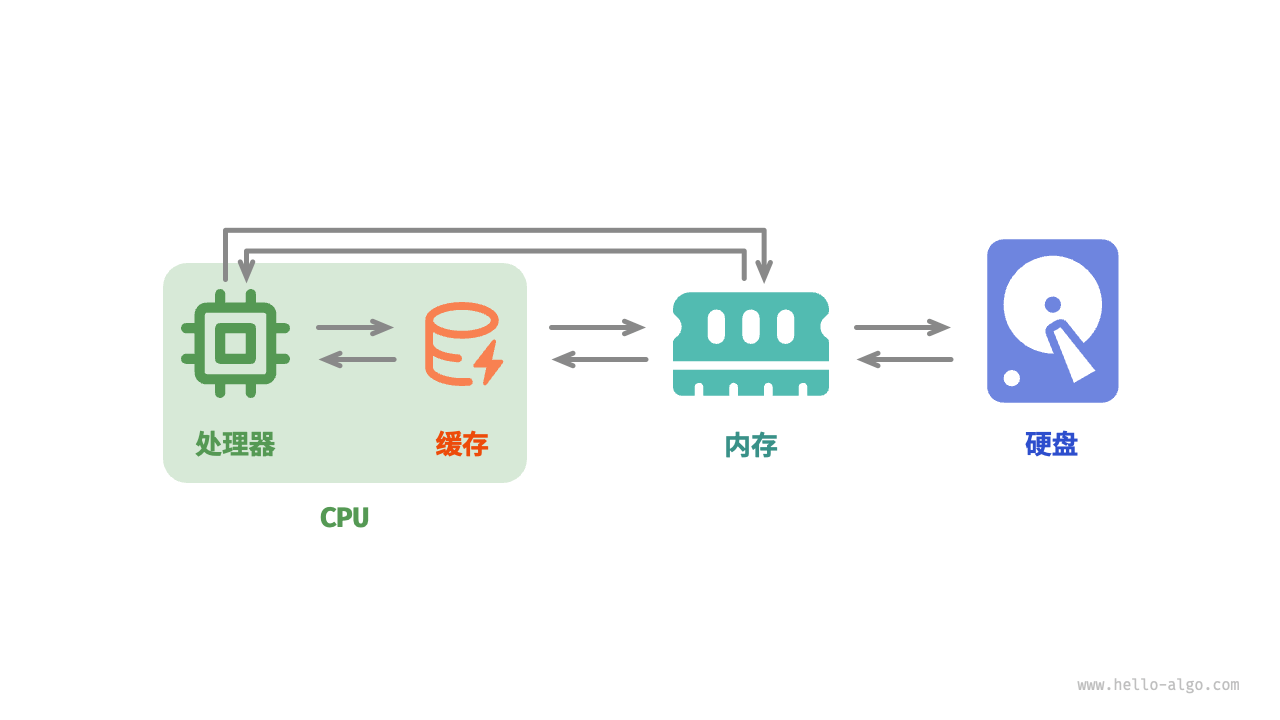
总的来说,硬盘用于长期存储大量数据,内存用于临时存储程序运行中正在处理的数据,而缓存则用于存储经常访问的数据和指令,以提高程序运行效率。三者共同协作,确保计算机系统高效运行。
在程序运行时,数据会从硬盘中被读取到内存中,供 CPU 计算使用。缓存可以看作 CPU 的一部分,它通过智能地从内存加载数据,给 CPU 提供高速的数据读取,从而显著提升程序的执行效率,减少对较慢的内存的依赖。
数据结构的内存效率
在内存空间利用方面,数组和链表各自具有优势和局限性。
一方面,内存是有限的,且同一块内存不能被多个程序共享,因此我们希望数据结构能够尽可能高效地利用空间。数组的元素紧密排列,不需要额外的空间来存储链表节点间的引用(指针),因此空间效率更高。然而,数组需要一次性分配足够的连续内存空间,这可能导致内存浪费,数组扩容也需要额外的时间和空间成本。相比之下,链表以“节点”为单位进行动态内存分配和回收,提供了更大的灵活性。
另一方面,在程序运行时,随着反复申请与释放内存,空闲内存的碎片化程度会越来越高,从而导致内存的利用效率降低。数组由于其连续的存储方式,相对不容易导致内存碎片化。相反,链表的元素是分散存储的,在频繁的插入与删除操作中,更容易导致内存碎片化。
数据结构的缓存效率
缓存虽然在空间容量上远小于内存,但它比内存快得多,在程序执行速度上起着至关重要的作用。由于缓存的容量有限,只能存储一小部分频繁访问的数据,因此当 CPU 尝试访问的数据不在缓存中时,就会发生「缓存未命中 cache miss」,此时 CPU 不得不从速度较慢的内存中加载所需数据。
显然,“缓存未命中”越少,CPU 读写数据的效率就越高,程序性能也就越好。我们将 CPU 从缓存中成功获取数据的比例称为「缓存命中率 cache hit rate」,这个指标通常用来衡量缓存效率。
为了尽可能达到更高的效率,缓存会采取以下数据加载机制。
- 缓存行:缓存不是单个字节地存储与加载数据,而是以缓存行为单位。相比于单个字节的传输,缓存行的传输形式更加高效。
- 预取机制:处理器会尝试预测数据访问模式(例如顺序访问、固定步长跳跃访问等),并根据特定模式将数据加载至缓存之中,从而提升命中率。
- 空间局部性:如果一个数据被访问,那么它附近的数据可能近期也会被访问。因此,缓存在加载某一数据时,也会加载其附近的数据,以提高命中率。
- 时间局部性:如果一个数据被访问,那么它在不久的将来很可能再次被访问。缓存利用这一原理,通过保留最近访问过的数据来提高命中率。
实际上,数组和链表对缓存的利用效率是不同的,主要体现在以下几个方面。
- 占用空间:链表元素比数组元素占用空间更多,导致缓存中容纳的有效数据量更少。
- 缓存行:链表数据分散在内存各处,而缓存是“按行加载”的,因此加载到无效数据的比例更高。
- 预取机制:数组比链表的数据访问模式更具“可预测性”,即系统更容易猜出即将被加载的数据。
- 空间局部性:数组被存储在集中的内存空间中,因此被加载数据附近的数据更有可能即将被访问。
总体而言,数组具有更高的缓存命中率,因此它在操作效率上通常优于链表。这使得在解决算法问题时,基于数组实现的数据结构往往更受欢迎。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号