《hello-algo》数据结构 —— 小记随笔
数据结构分类
逻辑结构:线性与非线性
逻辑结构揭示了数据元素之间的逻辑关系。
- 线性数据结构:数组、链表、栈、队列、哈希表。
- 非线性数据结构:树、堆、图、哈希表。
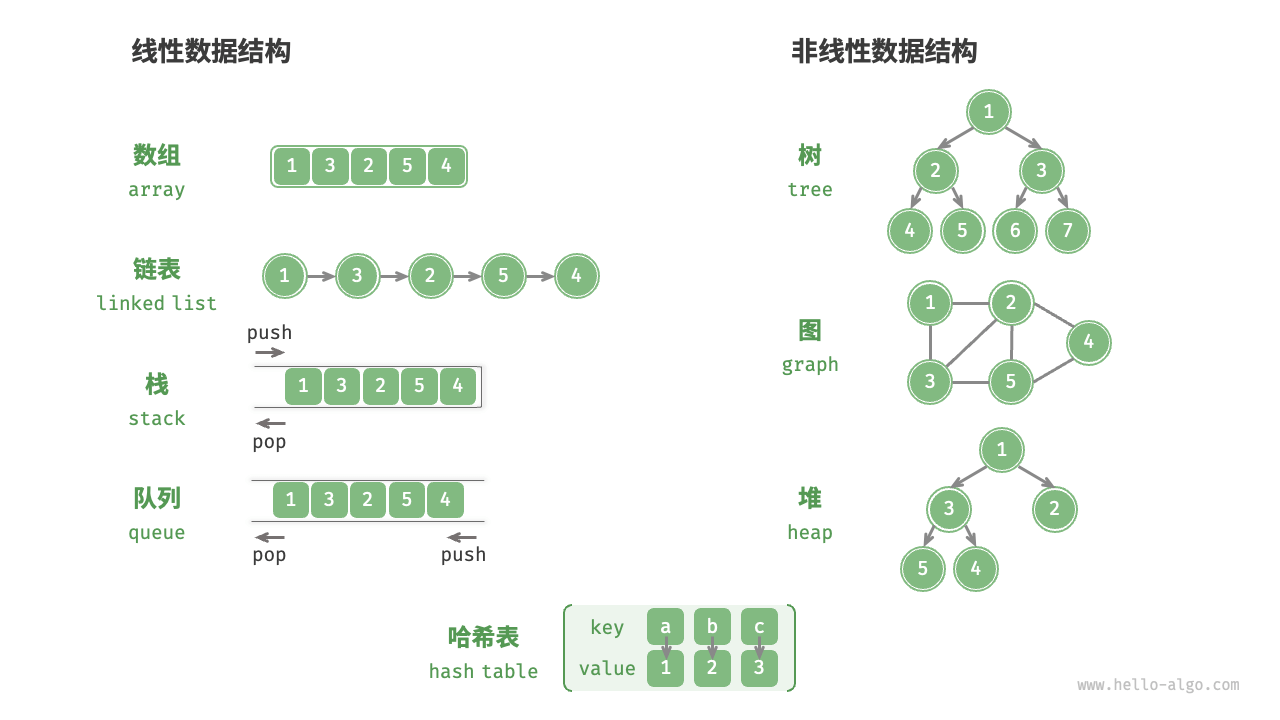
非线性数据结构可以进一步划分为树形结构和网状结构。
- 线性结构:数组、链表、队列、栈、哈希表,元素之间是一对一的顺序关系。
- 树形结构:树、堆、哈希表,元素之间是一对多的关系。
- 网状结构:图,元素之间是多对多的关系。
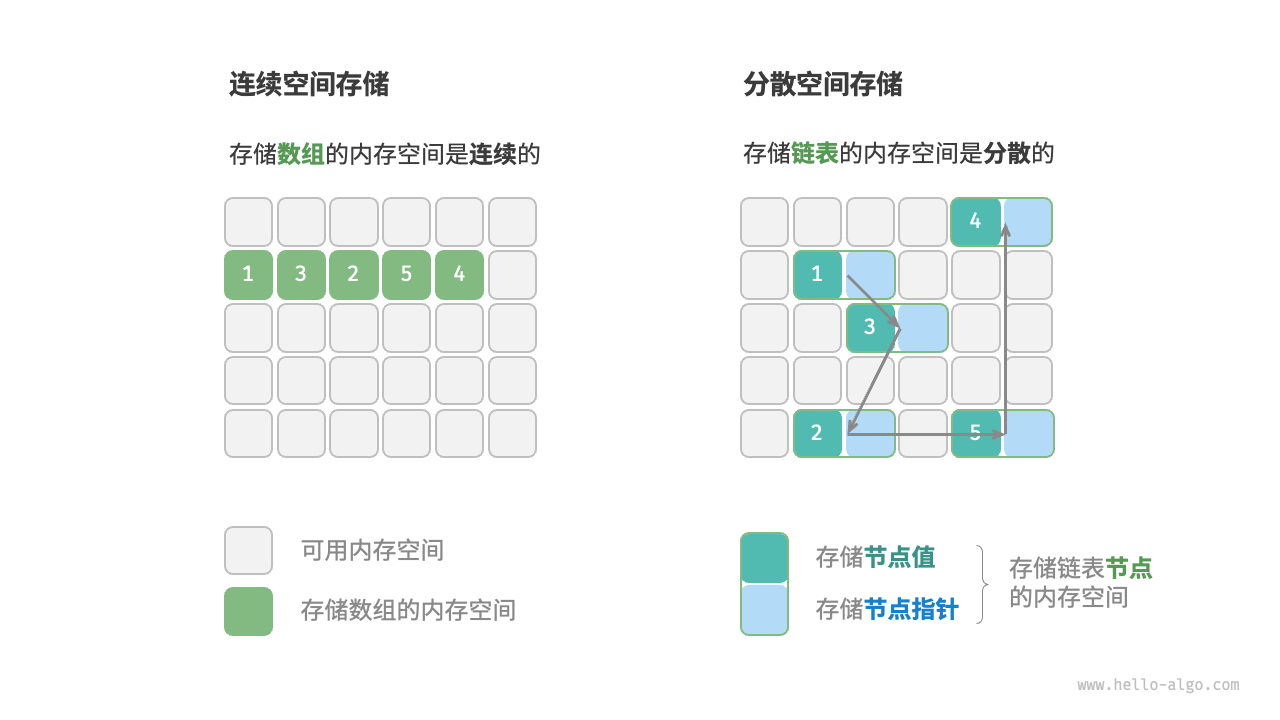
物理结构:连续与分散
内存是所有程序的共享资源,当某块内存被某个程序占用时,则无法被其他程序同时使用了。因此在数据结构与算法的设计中,内存资源是一个重要的考虑因素。比如,算法所占用的内存峰值不应超过系统剩余空闲内存;如果缺少连续大块的内存空间,那么所选用的数据结构必须能够存储在分散的内存空间内。
物理结构反映了数据在计算机内存中的存储方式,可分为连续空间存储(数组)和分散空间存储(链表)。物理结构从底层决定了数据的访问、更新、增删等操作方法,两种物理结构在时间效率和空间效率方面呈现出互补的特点。
基本数据类型
基本数据类型是 CPU 可以直接进行运算的类型,在算法中直接被使用,主要包括以下几种。
- 整数类型 byte、short、int、long 。
- 浮点数类型 float、double ,用于表示小数。
- 字符类型 char ,用于表示各种语言的字母、标点符号甚至表情符号等。
- 布尔类型 bool ,用于表示“是”与“否”判断。
基本数据类型以二进制的形式存储在计算机中。一个二进制位即为1比特。在绝大多数现代操作系统中,1字节(byte)由8比特(bit)组成。
那么,基本数据类型与数据结构之间有什么联系呢?我们知道,数据结构是在计算机中组织与存储数据的方式。这句话的主语是“结构”而非“数据”。
如果想表示“一排数字”,我们自然会想到使用数组。这是因为数组的线性结构可以表示数字的相邻关系和顺序关系,但至于存储的内容是整数 int、小数 float 还是字符 char ,则与“数据结构”无关。
换句话说,基本数据类型提供了数据的“内容类型”,而数据结构提供了数据的“组织方式”。
数字编码
原码、反码和补码
在上一节的表格中我们发现,所有整数类型能够表示的负数都比正数多一个,例如 byte 的取值范围是 [-128, 127]。这个现象比较反直觉,它的内在原因涉及原码、反码、补码的相关知识。
首先需要指出,数字是以“补码”的形式存储在计算机中的。在分析这样做的原因之前,首先给出三者的定义。
- 原码:我们将数字的二进制表示的最高位视为符号位,其中0表示正数,1表示负数,其余位表示数字的值。
- 反码:正数的反码与其原码相同,负数的反码是对其原码除符号位外的所有位取反。
- 补码:正数的补码与其原码相同,负数的补码是在其反码的基础上加1。
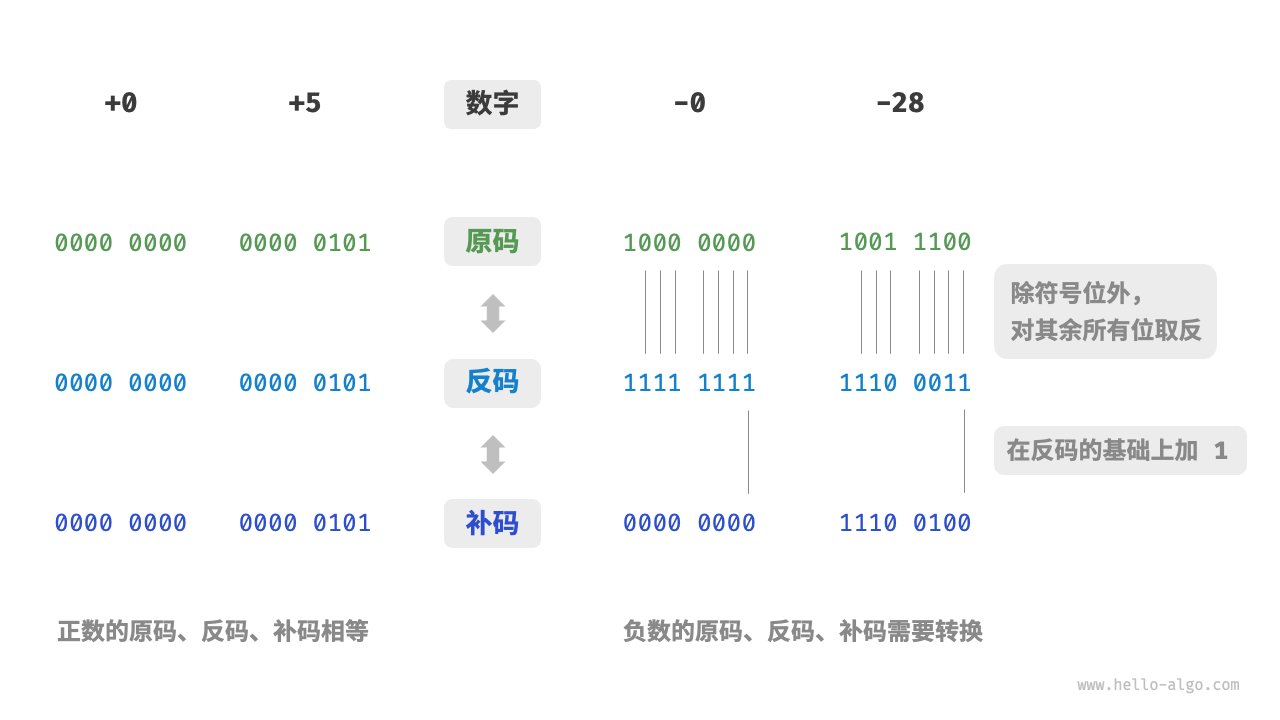
原码虽然直观,但是无法直接进行用于二进制运算
反码可以进行二进制运算,但是由于有+0 -0 的区别,所以需要加更多的逻辑处理问题,容易导致出错+效率下降。
补码解决+0/-0的问题,但是对于特殊的补码10000000是一个例外,它并没有对应的原码。根据转换方法,我们得到该补码的原码为 00000000。这显然是矛盾的,因为该原码表示数字 0,它的补码应该是自身。计算机规定这个特殊的补码 10000000 代表 -128。实际上,(-1)+(-127)在补码下的计算结果就是 -128。
上述所有计算都是加法运算。这暗示着一个重要事实:计算机内部的硬件电路主要是基于加法运算设计的。这是因为加法运算相对于其他运算(比如乘法、除法和减法)来说,硬件实现起来更简单,更容易进行并行化处理,运算速度更快。
这并不意味着计算机只能做加法。通过将加法与一些基本逻辑运算结合,计算机能够实现各种其他的数学运算。例如,计算减法 a-b 可以转换为计算加法 a+(-b);计算乘法和除法可以转换为计算多次加法或减法。
浮点数编码


字符编码
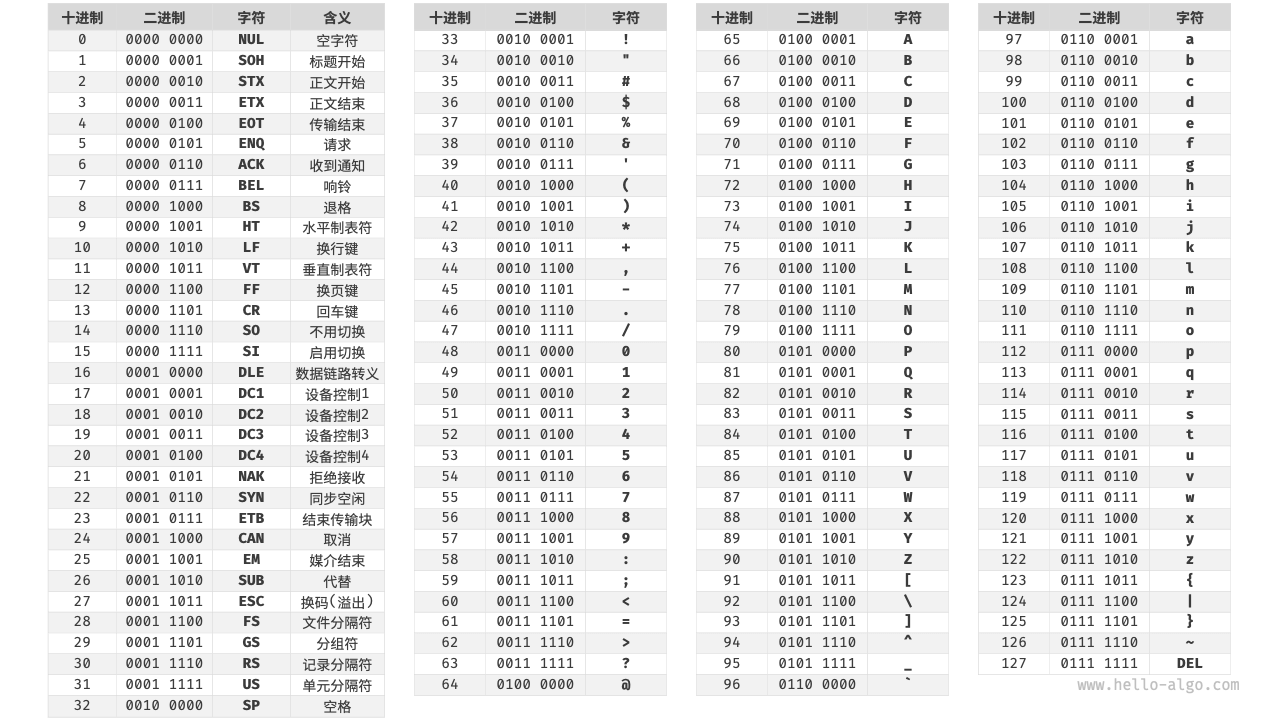
ASCII 字符集
它使用 7 位二进制数(一个字节的低 7 位)表示一个字符,最多能够表示 128 个不同的字符。如图 3-6 所示,ASCII 码包括英文字母的大小写、数字 0 ~ 9、一些标点符号,以及一些控制字符(如换行符和制表符)。
GBK 字符集
中国国家标准总局于 1980 年发布了「GB2312」字符集,其收录了 6763 个汉字,基本满足了汉字的计算机处理需要。
然而,GB2312 无法处理部分罕见字和繁体字。「GBK」字符集是在 GB2312 的基础上扩展得到的,它共收录了 21886 个汉字。在 GBK 的编码方案中,ASCII 字符使用一个字节表示,汉字使用两个字节表示。
Unicode 字符集
那个时代的研究人员就在想:如果推出一个足够完整的字符集,将世界范围内的所有语言和符号都收录其中,不就可以解决跨语言环境和乱码问题了吗?在这种想法的驱动下,一个大而全的字符集 Unicode 应运而生。
「Unicode」的中文名称为“统一码”,理论上能容纳 100 多万个字符。它致力于将全球范围内的字符纳入统一的字符集之中,提供一种通用的字符集来处理和显示各种语言文字,减少因为编码标准不同而产生的乱码问题。
自 1991 年发布以来,Unicode 不断扩充新的语言与字符。截至 2022 年 9 月,Unicode 已经包含 149186 个字符,包括各种语言的字符、符号甚至表情符号等。在庞大的 Unicode 字符集中,常用的字符占用 2 字节,有些生僻的字符占用 3 字节甚至 4 字节。
Unicode 是一种通用字符集,本质上是给每个字符分配一个编号(称为“码点”),但它并没有规定在计算机中如何存储这些字符码点。我们不禁会问:当多种长度的 Unicode 码点同时出现在一个文本中时,系统如何解析字符?例如给定一个长度为 2 字节的编码,系统如何确认它是一个 2 字节的字符还是两个 1 字节的字符?
对于以上问题,一种直接的解决方案是将所有字符存储为等长的编码。如图 3-7 所示,“Hello”中的每个字符占用 1 字节,“算法”中的每个字符占用 2 字节。我们可以通过高位填 0 将“Hello 算法”中的所有字符都编码为 2 字节长度。这样系统就可以每隔 2 字节解析一个字符,恢复这个短语的内容了。
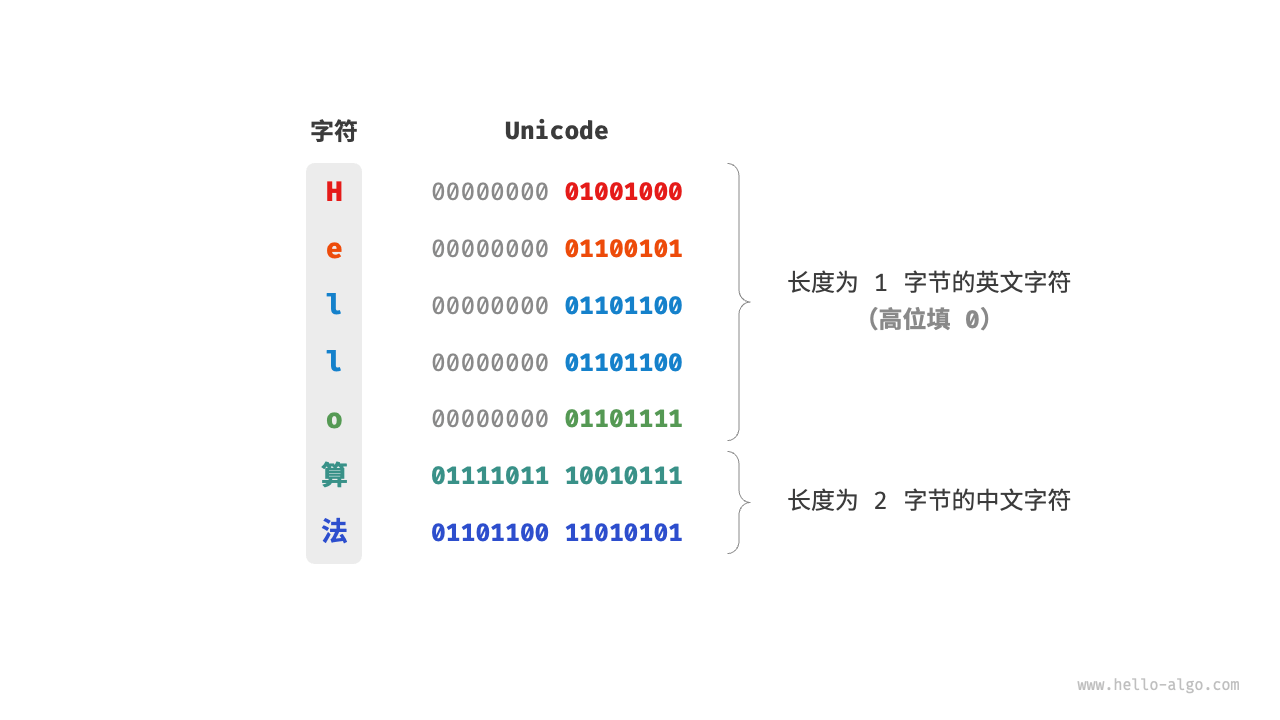
然而 ASCII 码已经向我们证明,编码英文只需 1 字节。若采用上述方案,英文文本占用空间的大小将会是 ASCII 编码下的两倍,非常浪费内存空间。因此,我们需要一种更加高效的 Unicode 编码方法。
UTF-8 编码
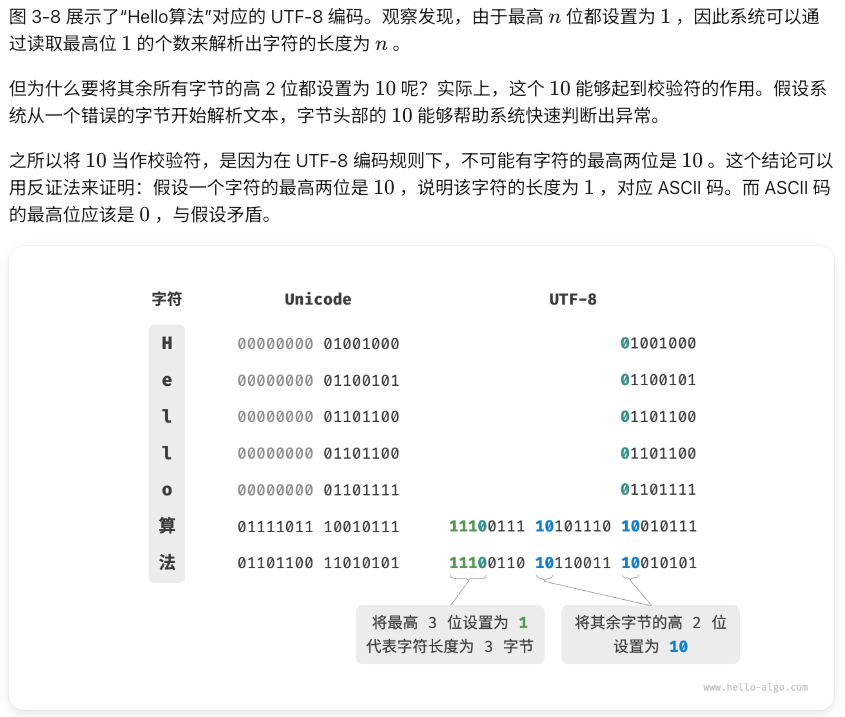
目前,UTF-8 已成为国际上使用最广泛的 Unicode 编码方法。它是一种可变长度的编码,使用 1 到 4 字节来表示一个字符,根据字符的复杂性而变。ASCII 字符只需 1 字节,拉丁字母和希腊字母需要 2 字节,常用的中文字符需要 3 字节,其他的一些生僻字符需要 4 字节。
- 对于长度为 1 字节的字符,将最高位设置为 0,其余 7 位设置为 Unicode 码点。值得注意的是,ASCII 字符在 Unicode 字符集中占据了前 128 个码点。也就是说,UTF-8 编码可以向下兼容 ASCII 码。这意味着我们可以使用 UTF-8 来解析年代久远的 ASCII 码文本。
- 对于长度为 n 字节的字符(其中 n > 1 ),将首个字节的高 n 位都设置为 1,第 n+1 位设置为 0;从第二个字节开始,将每个字节的高 2 位都设置为 10;其余所有位用于填充字符的 Unicode 码点。
- UTF-16 编码:使用 2 或 4 字节来表示一个字符。所有的 ASCII 字符和常用的非英文字符,都用 2 字节表示;少数字符需要用到 4 字节表示。对于 2 字节的字符,UTF-16 编码与 Unicode 码点相等。
- UTF-32 编码:每个字符都使用 4 字节。这意味着 UTF-32 比 UTF-8 和 UTF-16 更占用空间,特别是对于 ASCII 字符占比较高的文本。
从存储空间占用的角度看,使用 UTF-8 表示英文字符非常高效,因为它仅需 1 字节;使用 UTF-16 编码某些非英文字符(例如中文)会更加高效,因为它仅需 2 字节,而 UTF-8 可能需要 3 字节。
从兼容性的角度看,UTF-8 的通用性最佳,许多工具和库优先支持 UTF-8 。
编程语言的字符编码
对于以往的大多数编程语言,程序运行中的字符串都采用 UTF-16 或 UTF-32 这类等长编码。在等长编码下,我们可以将字符串看作数组来处理,这种做法具有以下优点。
- 随机访问:UTF-16 编码的字符串可以很容易地进行随机访问。UTF-8 是一种变长编码,要想找到第 i 个字符,我们需要从字符串的开始处遍历到第 i 个字符,这需要 O(n)的时间。
- 字符计数:与随机访问类似,计算 UTF-16 编码的字符串的长度也是 O(1)的操作。但是,计算 UTF-8 编码的字符串的长度需要遍历整个字符串。
- 字符串操作:在 UTF-16 编码的字符串上,很多字符串操作(如分割、连接、插入、删除等)更容易进行。在 UTF-8 编码的字符串上,进行这些操作通常需要额外的计算,以确保不会产生无效的 UTF-8 编码。

本文作者:Blue Mountain
本文链接:https://www.cnblogs.com/BlueMountain-HaggenDazs/p/17980435
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具