<<Redis 核心技术与实战>> 小记随笔 —— String 类型的一些不足之处
缺陷场景
在存储的 value 值较小且数量特别多的场景下,使用 String 类型进行存储会浪费大量的空间在维护元数据上,导致内存利用率下降。
原因分析
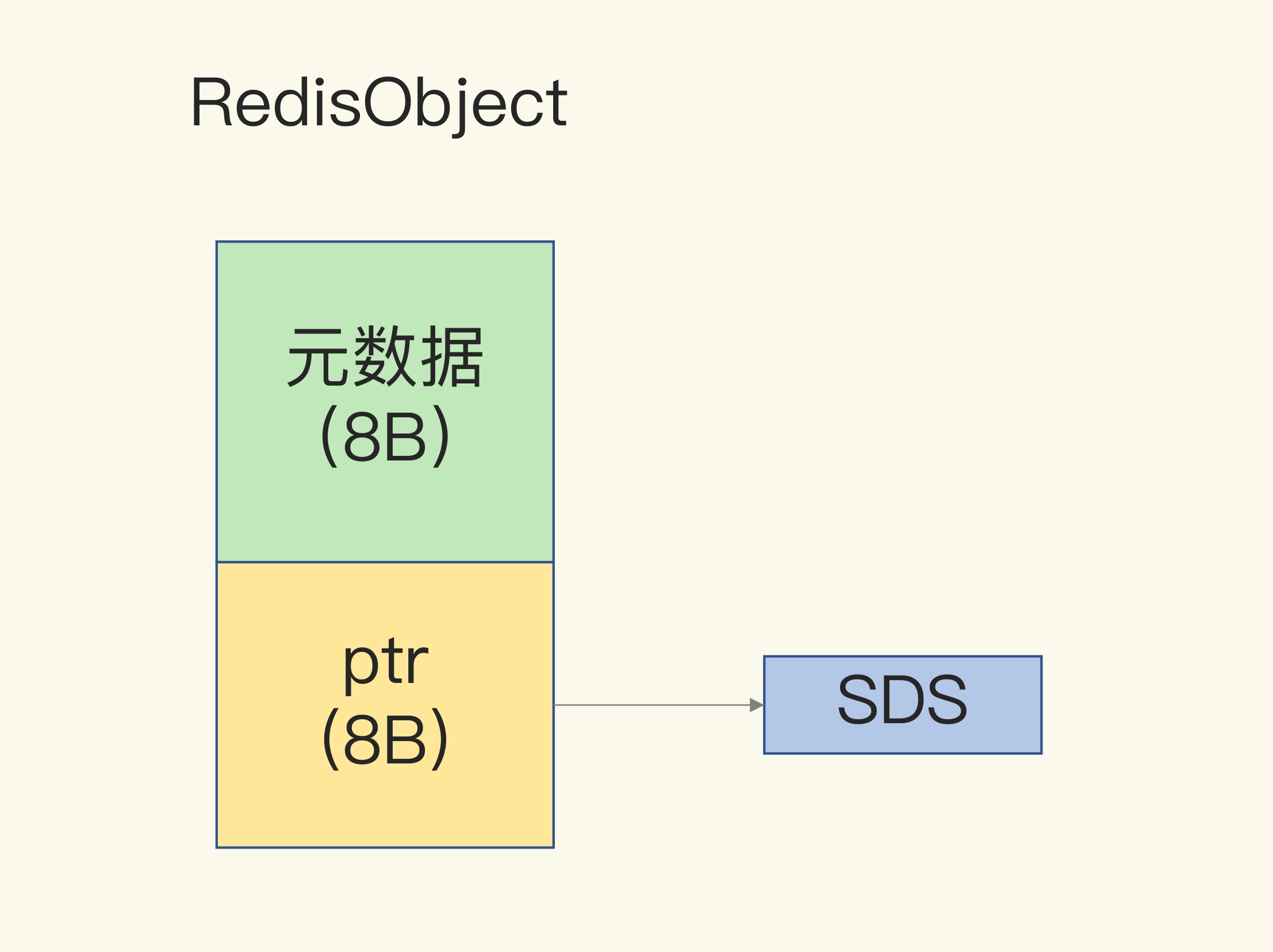
- Redis 在 vaule 设计上为了支持众多数据类型,会使用 RedisObject 来记录元数据以及指向数据位置的指针,大小为 16 字节。
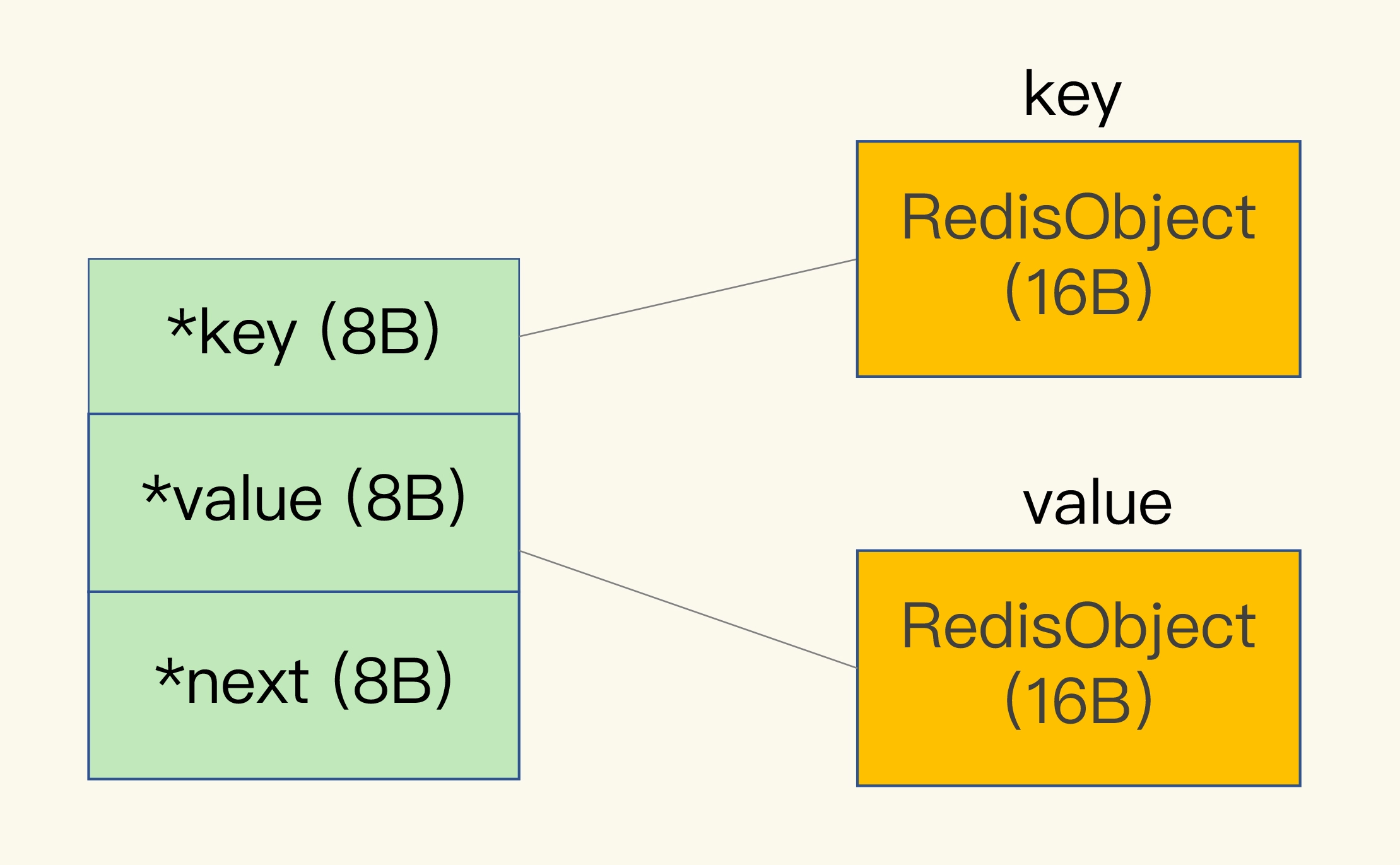
- Redis 会使用一个全局哈希表保存所有键值对,哈希表的每一项是一个 dictEntry 的结构体,用来指向一个键值对。dictEntry 结构中有三个 8 字节的指针,分别指向 key、value 以及下一个 dictEntry,三个指针共 24 字节,但是 Redis 是用了 jemalloc 分配内存,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。所以是32字节大小。
解决方案
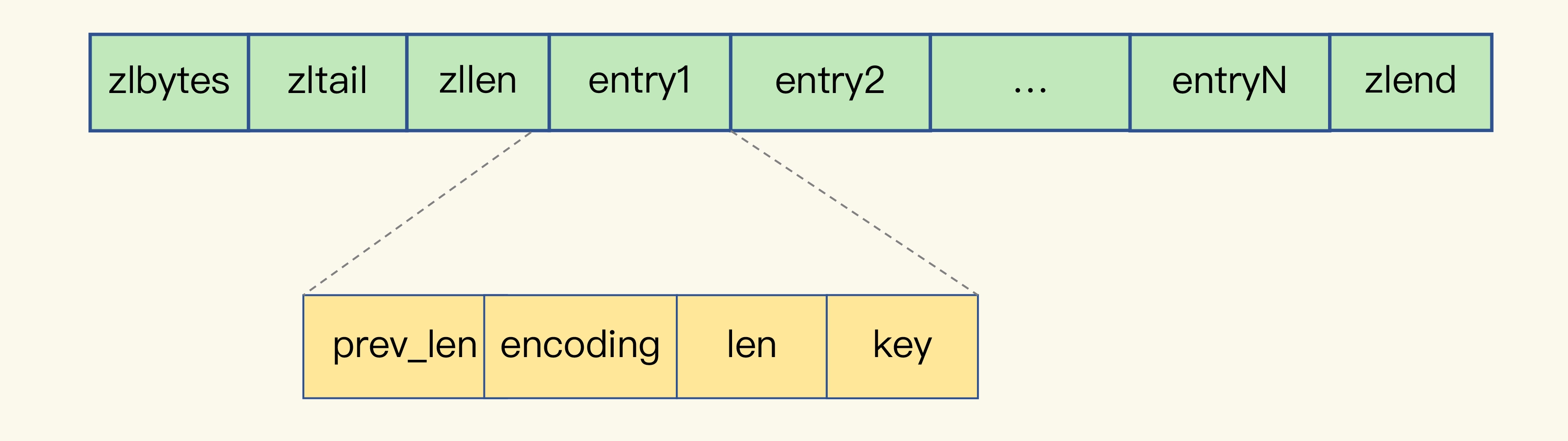
Redis 基于压缩列表实现了 List、Hash 和 Sorted Set 这样的集合类型,这样做的最大好处就是节省了 dictEntry 的开销。当你用 String 类型时,一个键值对就有一个 dictEntry,要用 32 字节空间。但采用集合类型时,一个 key 就对应一个集合的数据,能保存的数据多了很多,但也只用了一个 dictEntry,这样就节省了内存。
Redis Hash 类型底层实现结构采用决策参数
Redis Hash 类型的两种底层实现结构,分别是压缩列表和哈希表。那么,Hash 类型底层结构什么时候使用压缩列表,什么时候使用哈希表呢?其实,Hash 类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。这两个阈值分别对应以下两个配置项:
- hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
- hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
如果我们往 Hash 集合中写入的元素个数超过了 hash-max-ziplist-entries,或者写入的单个元素大小超过了 hash-max-ziplist-value,Redis 就会自动把 Hash 类型的实现结构由压缩列表转为哈希表。一旦从压缩列表转为了哈希表,Hash 类型就会一直用哈希表进行保存,而不会再转回压缩列表了。在节省内存空间方面,哈希表就没有压缩列表那么高效了。
常见的编码方案
在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。这里说的二级编码,就是把一个单值的数据拆分成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value,这样一来,我们就可以把单值数据保存到 Hash 集合中了。以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。
PS:需要把 hash-max-ziplist-entries 设置为 1000。
本文作者:Blue Mountain
本文链接:https://www.cnblogs.com/BlueMountain-HaggenDazs/p/17024469.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步