
香农熵学习+例子[转载]
转自:https://www.cnblogs.com/wyuzl/p/7699818.html
1.在决策树算法中,就是根据信息论的方法找到最合适的特征来划分数据集。在这里,我们首先要计算所有类别的所有可能值的香农熵,根据香农熵来我们按照取最大信息增益(information gain)的方法划分我们的数据集。
2.香农熵计算公式
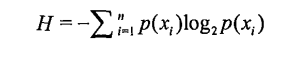
3.使用的数据集

4.测试代码
# 代码功能:计算香农熵 from math import log #我们要用到对数函数,所以我们需要引入math模块中定义好的log函数(对数函数) def createDataSet(): dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] # 我们定义了一个list来表示我们的数据集,这里的数据对应的是上表中的数据 labels = ['no surfacing','flippers'] return dataSet, labels def calcShannonEnt(dataSet):#传入数据集 # 在这里dataSet是一个链表形式的的数据集 countDataSet = len(dataSet) # 我们计算出这个数据集中的数据个数,在这里我们的值是5个数据集 labelCounts={} # 构建字典,用键值对的关系我们表示出 我们数据集中的类别还有对应的关系 for featVec in dataSet: #通过for循环,我们每次取出一个数据集,如featVec=[1,1,'yes'] currentLabel=featVec[-1] # 取出最后一列 也就是类别的那一类,比如说‘yes’或者是‘no’ if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 labelCounts[currentLabel] += 1#统计这个类别出现了多少次。 print(labelCounts) # 最后得到的结果是 {'yes': 2, 'no': 3} shannonEnt = 0.0 # 计算香农熵, 根据公式 for key in labelCounts: prob = float(labelCounts[key])/countDataSet shannonEnt -= prob * log(prob,2) return shannonEnt data,labels=createDataSet(); se=calcShannonEnt(data); print(se); print(labels);
运行结果:
{'yes': 2, 'no': 3}
0.9709505944546686
['no surfacing', 'flippers']
5.将dataset改变
dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no'], [0,1,'maybe']] # 我们定义了一个list来表示我们的数据集,这里的数据对应的是上表中的数据
多加入了最后一种,运行结果:
{'yes': 2, 'no': 3, 'maybe': 1}
1.4591479170272448
['no surfacing', 'flippers']
很明显,香农熵是增加的,因为它的含义就是所包含的信息量。
//学习了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号