入坑-DM导论-第一章绪论笔记
//本学习笔记只是记录,并未有深入思考。
1.什么是数据挖掘?
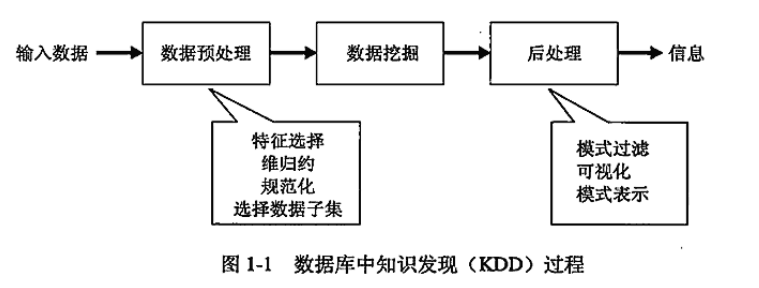
数据挖掘是数据库中发现必不可少的一部分。
数据预处理主要包括(可能是最耗时的步骤):
1.融合来自多个数据源的数据
2.清洗数据以消除噪声和重复的观测值
3.选择与当前数据挖掘任务相关的记录和特征。
2.数据挖掘要解决的问题
1.可伸缩性:面对海量数据,算法必须是可伸缩的。例如:当药不能处理的数据放入内存的时候,需要非内存算法;使用抽样技术或者开发并行和分布算法也可提高伸缩性。
2.高维性:具有成百上千的属性的数据集也很常见,比如基因特征;并且由于维度的增加,算法计算复杂度将会迅速升高。
3.异种数据和复杂数据:即非传统的数据类型:如包含半结构化的文本和超链接的Web页面,
4.数据所有权与分布:数据在地理上分属于多个站点和机构,需要开发分布式数据挖掘技术,
5.非传统分析:传统的统计方法基于假设-检验模式,但目前的数据分析需要的假设量太大,那么需要自动地产生假设和评估。
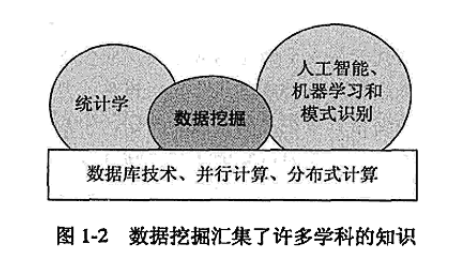
图中给出了数据挖掘和其他学科的关系。
1.3数据挖掘任务
预测任务:根据其他属性的值,预测特定属性的值。
描述任务:导出数据中潜在能够描述关系的模式(相关、趋势、聚类、轨迹和异常),这通常是探查性的,需要进行验证和解释。
根据数据类型可以分为:
分类:对离散型数据
回归:对连续型数据
2.分析方式概括
预测任务:比如对鸢尾花进行分类。
关联分析:用于发现数据中强关联的特征;比如找出功能相关的基因组,发现购物者同时购买的商品等。
聚类分析:发现紧密相关的观测值组群,对顾客进行分组。
异常检测:识别特征显著不同于其他特征的观测值;检测欺诈软件、网络攻击等;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号