limit offset慢查询学习[已迁移]
转自:https://cloud.tencent.com/developer/article/1962276
1.用法
1. select* from article LIMIT 1,3 2.select * from article LIMIT 3 OFFSET 1
均表示略过第一条,取第2,3,4条数据。
2.慢查询原因
在offset很大时,会非常慢。它是先一直一条一条读取到10100条,然后再根据offset的设置,舍弃前10000条记录,返回后面的100条记录。
原因:MySQL的数据存储并不是一个数组,可以直接根据下标获取第X位。即使给你搜索的字段加了索引,也只是使用该字段的值去建立一个新的N叉排序树(索引二叉树),来方便快速找到数据位置。所以并不能在O(1)时间知道第N个数在什么位置,而是O(N)需要从头开始遍历叶子结点链表,通过遍历计数来获取第N个数。
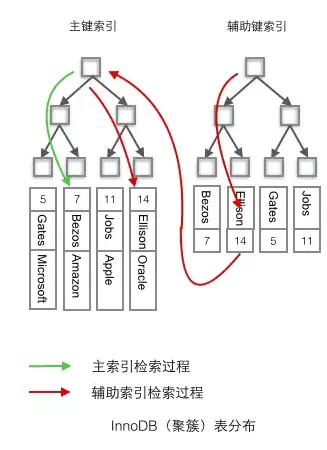
如果查找的where字段不是主键,而是自己创建的辅助索引,那么就会先根据辅助索引的叶子结点(存储主键索引,包含主键id)再去遍历主键索引B+数来获取到行的值。
为什么要查这些无效数据?

//没太看懂是为什么,过于深奥,以后有机会再了解。
3.解决办法
3.1 利用主键id缩小范围
select * from table where id > 10000 limit 100;
- 直接查主键二叉树并获取其节点上的数据;
- 用大于的条件,从而利用好N叉排序树的特性,快速查找到数据的起始节点,然后获取其后的100条记录数据即可。这和offset找第100001条节点的实现机制有本质区别。(在20W的数据量级下,经过测试查询性能可以提升43倍。)
3.2 子查询
适用于必须要查询辅助索引N叉树的场景。
如果用非主键的索引去遍历,会导致两次对二叉树的查询操作:先查索引二叉树找到节点的主键,再查主键索引二叉树取具体数据。
select * from table where update_time < CURDATE() limit 100 offset 10000; //上述慢查询可替换为 select * from table where id in (select id from table where update_time < CURDATE()) limit 100 offset 10000;
子查询是根据辅助索引去查的,而主查询只根据了主键去查。在子查询中并不会真正去访问主键索引二叉树获取数据,因为只查询主键id,直接在辅助索引的叶子结点上就可以拿到,所以免去了10000次无效查询。在子查询获取到id后,再用IN查询去在主键索引二叉树上遍历数据。(这种做法虽然也要查询10000条无用的数据,但由于是直接使用主键索引,所以比直接查询limit offset的做法会快两倍左右。//所以才快2倍,看起来效率也不怎么高。)
还有解法3,利用join,没太仔细看,以后用到的时候再了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号