
redis hash学习
转自:http://c.biancheng.net/redis/hashes.html
1.介绍
- Redis hash(哈希散列)是由字符类型的 field(字段)和 value 组成的哈希映射表结构(也称散列表),它非常类似于表格结构。在 hash 类型中,field 与 value 一一对应,且不允许重复。
- Redis hash 特别适合于存储对象。一个 filed/value 可以看做是表格中一条数据记录;而一个 key 可以对应多条数据。
2.常用命令
#设置单个字段 127.0.0.1:6379> HSET user:10 user:1 20201001 (integer) 1 #同时设置多个字段 127.0.0.1:6379> HMSET user:10 user:2 20201002 user:3 20201004 user:4 20201018 OK #查询单个字段 127.0.0.1:6379> HGET user:10 user:2 "20201002" #查询所有字段 127.0.0.1:6379> HGETALL user:10 1) "user:1" 2) "20201001" 3) "user:2" 4) "20201002" 5) "user:3" 6) "20201004" 7) "user:4" 8) "20201018" 127.0.0.1:6379> HKEYS user:10 1) "user:1" 2) "user:2" 3) "user:3" 4) "user:4" #返回字段个数 127.0.0.1:6379> HLEN user:10 (integer) 4 #返回所有字段值 127.0.0.1:6379> HVALS user:10 1) "20201001" 2) "20201002" 3) "20201004" 4) "20201018" #迭代hash的key键 HSCAN key cursor # 迭代哈希表中的所有键值对,cursor 表示游标,默认为 0。 127.0.0.1:6379> HSCAN user:10 0 1) "0" 2) 1) "user:1" 2) "20201001" 3) "user:2" 4) "20201002" 5) "user:3" 6) "20201004" 7) "user:4" 8) "20201018" #判断字段是否存在,存在返回1,不存在返回0 127.0.0.1:6379> HEXISTS user:10 user:4 (integer) 1 127.0.0.1:6379> HEXISTS user:10 user:5 (integer) 0
3.存储结构
https://juejin.cn/post/6904207789510361095
3.1 ziplist
两种情况都满足时,Hash会使用 ziplist 进行存储:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节。对应配置:server.hash_max_ziplist_value。
- 哈希对象保存的键值对数量小于 512 个。对应配置:server.hash_max_ziplist_entries。
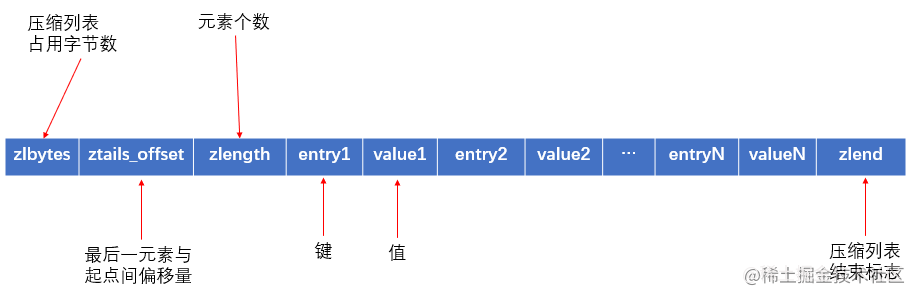
这种情况下查找元素的时间复杂度为O(n),并不适合存储大量键值对。如果不满足上述两个条件,则自动转换为hashtable类型。
> hset aaa k1 v1 (integer) 1 > debug object aaa Value at:0x7f9e25e279d0 refcount:1 encoding:ziplist serializedlength:20 lru:85125 lru_seconds_idle:8
3.2 hashtable
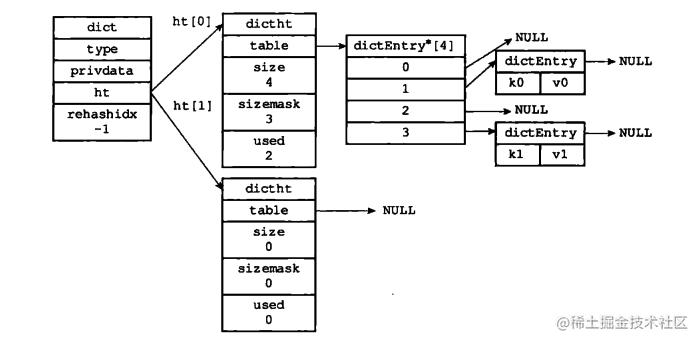
dictht类型:
- table:指向哈希表的指针
- size:哈希表数组的大小
- sizemask:用于计算哈希值的掩码
- used:已经存储的(K,V)个数
字典类型的中其实包含两个哈希表,一个是用于存储(K,V)的哈希表ht[0],而另外一个ht[1]用于后续的扩容。
渐进式rehash扩容,移动一部分到新哈希表中,查找时先查旧再查新。
3.3 顺序问题
https://www.cnblogs.com/txtp/p/16743010.html
默认情况下,Redis的Hash是使用ziplist进行存储的,当超出一定限制后,再改为hashtable进行存储。
- ziplist是双向链表,存储顺序和数据插入顺序一致。查询结果顺序和存储顺序一致。
- hashtable是字典结构,查询结果顺序和插入顺序不一致。
HGETALL 没有顺序性。如果需要顺序,业务上层排序。Hash会根据数据量进行数据结构调整。目的:提高性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号