
系统过载理解
转自:https://cloud.tencent.com/developer/article/1329609
https://www.361shipin.com/blog/1552697548710346752,讲的很好
1.介绍
过载: 系统负载超过系统最大的处理能力。
服务器雪崩: 服务器的处理能力陡降,低于系统原本能达到的最大处理能力。
关系:
系统过载处理不当会造成服务器雪崩: 系统过载时,CPU、内存等资源达到瓶颈,系统响应会变慢。这时可能会发生大量的请求重试或系统内部重试,进一步加剧系统负载,产生恶性循环,导致系统处理能力急剧下降(服务器雪崩)。
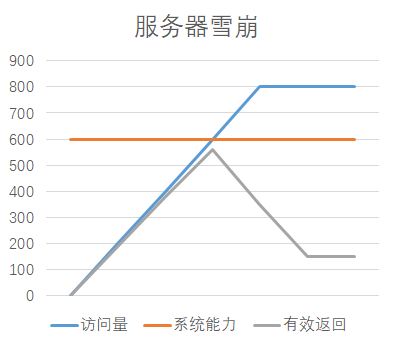
过载原因:
- 访问量过大,(某个时间内访问量过大,或突增)
- 系统内部瓶颈、故障。(系统内部故障会导致系统的处理能力下降,从而容易引发过载。)
- 后端故障、延迟。(后端处理能力的下降会影响到本系统的响应能力)
2.接口延时优化
https://blog.csdn.net/VitaminX181/article/details/117490627
优化有三个维度:分别是吞吐量、时延、系统容量。
- 吞吐量:指的是单位时间内系统能完成多少操作;
- 时延:指的是操作的响应时间,比如说搜索商品的结果必须在200ms内展示给用户;
- 系统容量:指的是在吞吐量和时延达标的情况下,对硬件环境的额外约束。
从系统层面看:CPU、内存、网络、磁盘这几个维度。
- sql查询语句如果结果返回的对象过大,可能会影响内存占用。
- sql慢查询,没有使用索引会影响cpu使用率。
3.过载保护
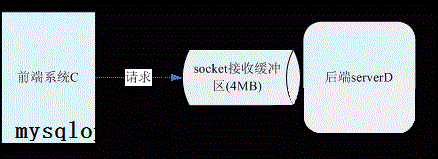
前端系统C通过udp请求访问后端serverD,后端server D的udp套接字缓冲区为4MB,每个请求大小约400字节。后端serverD偶尔处理超时情况下,前端系统C会重试,最多重试2次。
假设一个业务场景,秒杀门票,大量的用户聚集在同一时刻发起了大量请求,超出了后台serverD的最大负载能力。操作响应失败的用户又重试, 中间系统的重试,进一步带来了更大量的请求,导致所有用户操作都是失败的。
大量请求会马上将4MB大小的缓冲区堆满,请求可能会丢失,而且D在处理排队的请求时,处理到的时候可能该请求就已经超时了,已经被用户重试了,那么D所做的处理就是无用功。
- 所以,每个系统,自己的最大处理能力是多少要做到清清楚楚。如上图,前端进程C处理能力要取决于后端D。
- 前端要保护后段;重试要慎重;过载时,该拒绝的请求就拒绝;用户重试时,适当延缓;
过载保护很重要的一点,不是说要加强系统性能、容量,成功应答所有请求,而是保证在高压下,系统的服务能力不要陡降到0,而是顽强的对外展现最大有效处理能力。【不论如何,要保证系统的可用性!】
推荐解决方案:
对于“每个系统要有能力发现哪些是有效的请求,哪些是雪球无效的请求”。

- 在系统每个机器上都部署一个interface实例,它能够快速的从socket缓冲区中取得请求,打上当前时间戳,压入channel。
- 业务处理进程从channel中获取请求和该请求的时间戳,如果发现时间戳早于当前时间减去超时时间(即已经超时,处理也没有意义),就直接丢弃该请求,或者应答一个失败报文。
Channel是一个先进先出的通信方式,可以是socket,也可以是共享内存、消息队列、或者管道,不限。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号