
缓存穿透和雪崩学习
转自:https://segmentfault.com/a/1190000039688578,https://blog.51cto.com/u_14787961/3199848
1.缓存穿透
缓存穿透是指,缓存和数据库都没有的数据,被大量请求,由于数据不存在,缓存就也不会存在该数据,所有的请求都会直接穿透到数据库。
解决:
- 接口增加业务层级的
Filter,进行合法校验,这可以有效拦截大部分不合法的请求。使用布隆过滤器,针对一个或者多个维度,把可能存在的数据值hash到bitmap中,bitmap证明该数据不存在则该数据一定不存在。但也有可能误判。 - 针对数据库与缓存都没有的数据,对空的结果进行缓存,但是过期时间设置得较短,一般五分钟内。而这种数据,如果数据库有写入,或者更新,必须同时刷新缓存,否则会导致不一致的问题存在。
2.缓存击穿【数据竞争并发预热】
缓存击穿是指数据库原本有得数据,但是缓存中没有,一般是缓存突然失效了,这时候如果有大量用户请求该数据,缓存没有则会去数据库请求,会引发数据库压力增大,可能会瞬间打垮。
解决:
- 如果是热点数据,那么可以考虑设置永远不过期。
- 如果数据一定会过期,那么就需要在数据为空的时候,设置一个互斥的锁,只让一个请求通过,只有一个请求去数据库拉取数据,取完数据,不管如何都需要释放锁,异常的时候也需要释放锁,要不其他线程会一直拿不到锁。
例子:
public static String getProductDescById(String id) { String desc = redis.get(id); // 缓存为空,过期了 if (desc == null) { // 互斥锁,只有一个请求可以成功 if (redis.setnx(lock_id, 1, 60) == 1) {//请求一个分布式锁 try { // 从数据库取出数据 desc = getFromDB(id); redis.set(id, desc, 60 * 60 * 24); } catch (Exception ex) { LogHelper.error(ex); } finally { // 确保最后删除,释放锁 redis.del(lock_id); return desc; } } else { // 否则睡眠200ms,接着获取锁 Thread.sleep(200); return getProductDescById(id);//再重新执行该函数 } } }
3.缓存雪崩-集中失效
缓存雪崩是指缓存中有大量的数据,在同一个时间点,或者较短的时间段内,全部过期了,这个时候请求过来,缓存没有数据,都会请求数据库,则数据库的压力就会突增,扛不住就会宕机。
//看起来有点像多个缓存击穿问题,就称为雪崩?
- 如果是热点数据,那么可以考虑设置永远不过期;要是所有的热点数据在一台redis服务器上,也是极其危险的,如果网络有问题,或者redis服务器挂了,那么所有的热点数据也会雪崩(查询不到),因此将热点数据打散分不到不同的机房中,也可以有效减少这种情况。
- 缓存的过期时间除非比较严格,考虑设置一个波动随机值,比如理论十分钟,那这类key的缓存时间都加上一个1~3分钟,过期时间在7~13分钟内波动,有效防止都在同一个时间点上大量过期;过期时间=基础时间+随机时间。
4.什么是热点数据
比如秒杀商品、微博热搜,都是用户频繁访问的数据。
- 首先能先找到这个热key来,比如通过Spark实时流分析,及时发现新的热点key。
- 将集中化流量打散,避免一个缓存节点过载。由于只有一个key,我们可以在key的后面拼上有序编号,比如key#01、key#02。。。key#10多个副本,分为多个子key,这些加工后的key位于多个缓存节点上。
- 每次请求时,客户端随机访问一个即可。
![]()
5.缓存数据一致性
缓存是用来加速的,一般不会持久化储存。所以,一份数据通常会存在DB和缓存中,就可能会出现数据不一致的情况,另外,上面所说的缓存热点问题会引入多个副本备份,也可能会发生不一致现象。
解决:
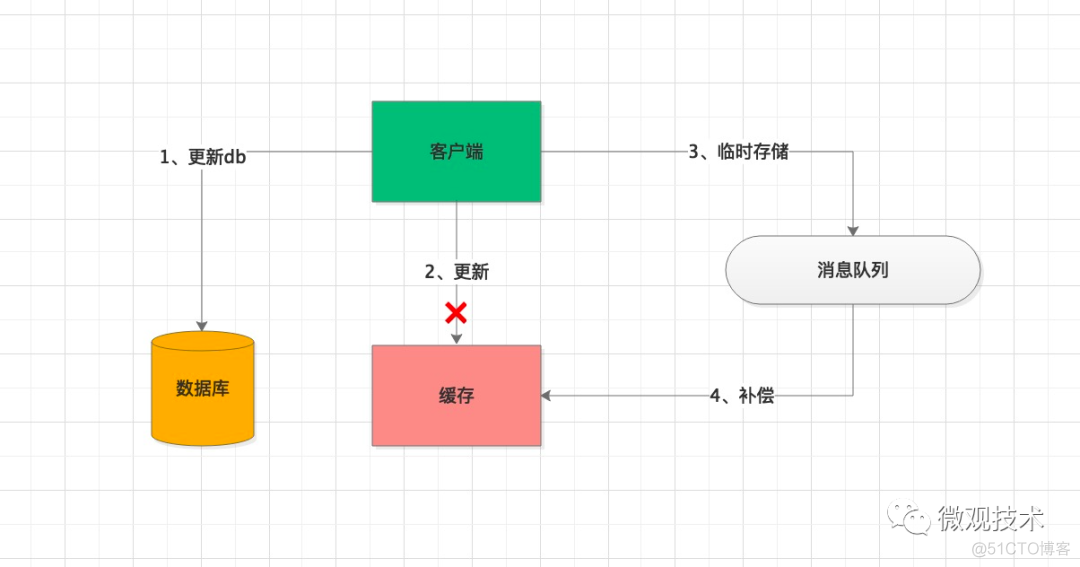
- 方案一:当缓存更新失败后,进行重试,如果重试失败,将失败的key写入MQ消息队列,通过异步任务补偿缓存,保证数据的一致性。
- 方案二:设置一个较短的过期时间,通过自修复的方式,在缓存过期后,缓存重新加载最新的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号