
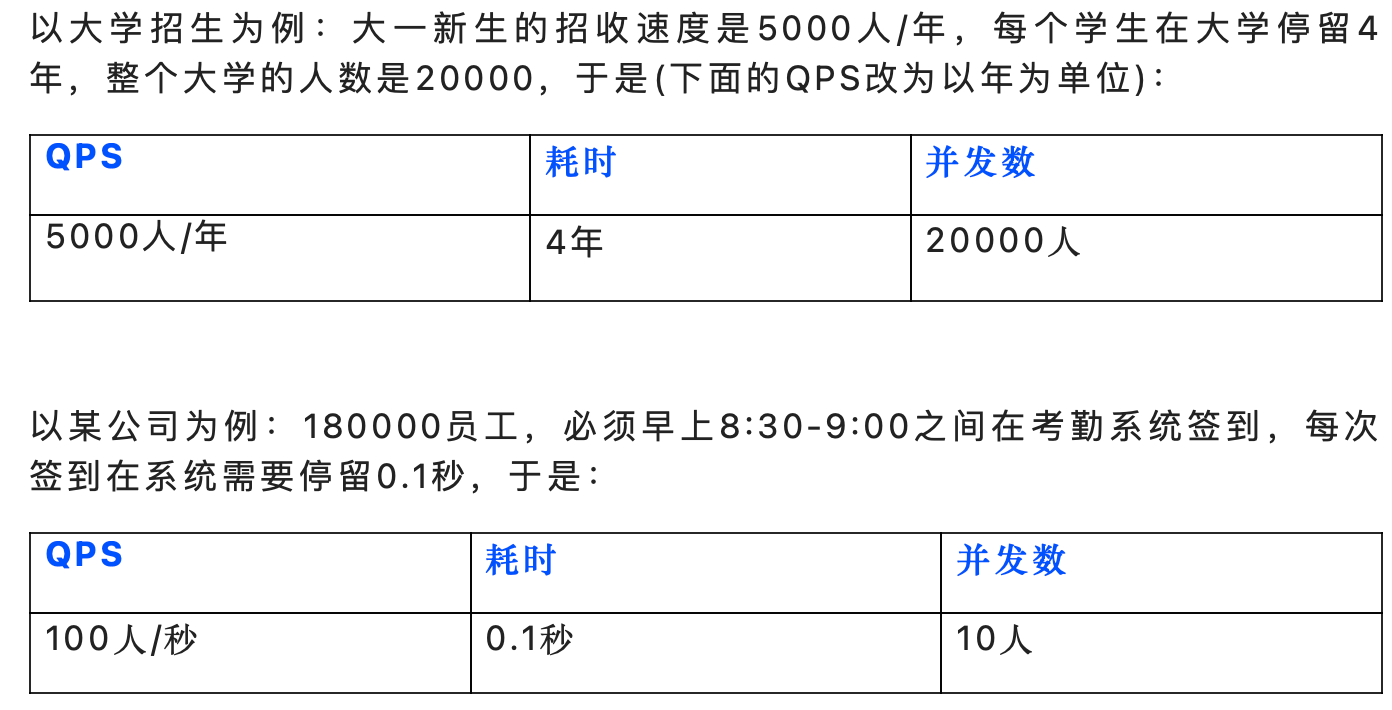
qps和tps计算
转自:https://www.cnblogs.com/fengjian2016/p/12321895.html
1.QPS每秒查询率
QPS:Queries Per Second,“每秒查询率”,= req/sec = 请求数/秒。
QPS是一台服务器每秒能够处理的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。代表的是服务器的机器的性能最大吞吐能力。(所以qps也可以叫做吞吐率?)【觉得“吞吐能力”这个词好难理解,英文是handling capacity,也可翻译为[计] 处理能力,”处理能力“明显更好理解!】
有时会强调,QPS 代表的是单个进程每秒请求服务器的成功次数。但也可以代表服务器的处理能力。(随使用场景而变吧。)
计算例子:
原理:每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间 公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS) 机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器 问:每天300w PV 的在单台机器上,这台机器需要多少QPS? 答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS) 问:如果一台机器的QPS是58,需要几台机器来支持? 答:139 / 58 = 3
注:一天24h秒数为86400秒。
PV(Page View):访问量,即页面浏览量或者点击量,用户每次对网站的访问均被记录1次。用户对同一页面的多次访问,访问量值累计。
2.TPS-每秒处理的事务数目
TPS 的过程包括:
- 客户端请求服务端、
- 服务端内部处理、
- 服务端返回客户端。
3.QPS和TPS两者区别
Qps 基本类似于 Tps,但是不同的是,对于一个页面的一次访问,形成一个 Tps;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“Qps”之中。
例如,访问一个 Index 页面会请求服务器 3 次,包括一次 html,一次 css,一次 js,那么访问这一个页面就会产生一个“T”,产生三个“Q”。
4.QPS和并发数
https://blog.csdn.net/vxzhg/article/details/118548270
QPS和并发数关系-非常生动的例子!
- QPS是每秒钟处理的请求数。对于一个系统来说,这个值有一个上限,压测的一个目的是测出这个最大值,来评估我们系统的能力。
- 并发数是一个时刻能系统中有多少在处理中的请求。对于一个系统来说,当然这个值也有一个上限,压测也可以测出最大并发数。
- 平均耗时avg,即一个请求从被接收到,到处理完成所耗费的平均时间。
三者关系:
并发数=QPS * avg耗时
例子:

系统的并发数趋近于0,即这是一个高QPS、低延时系统,是一个很好的系统,轻轻松松地快速处理各种请求,来一个灭一个。
- 值得一提的是,此时并发数很低,但这不表明系统实际能够承受的并发数很低,它实际上可能承受很高的并发数。
- 系统实时并发数低,并不代表系统的处理能力差。相反,在系统处理较快时,没有请求积压,并发数接近于0。
上述两点对于理解并发数很重要,并发数表示系统中同时存在的请求数,那么数量越大越说明有更多的请求在等待队列中,那么cpu负载可能就会更高!(之前一直以为并发数越高越好,并发数是说目前系统的一个状态,而不是理想能处理多少,之前理解反了。)
压测思路:
设定x个线程去同时请求接口(人为指定并发数为x),测得此时的qps、平均耗时等值。然后逐渐增大并发数进行测试,随着并发数的增大qps会逐渐增大直到达到一个最大值。这时我们就得到了系统的一个qps上限。
这时如果并发数继续增大,因为qps已经到达上限了,那么为了满足并发请求,只能增大耗时,也就是会看到耗时的增加,接口响应变慢。(我认为是,因为吞吐率下降,也就是每秒能够处理的请求数下降,那么新来的请求只能先在等待队列中等待,所以请求等待时间增大。)
此外,还可以不断增大并发数直到接口响应出现error,测得一个系统能承载的最大并发数。(我的理解是,qps降低,请求到放到队列中,但队列有大小限制,超过一定数目就会返回error?或者说在等待队列中的请求都会占用缓存资源,那么缓存不够了,就没办法放到等待队列中,所以就会返回错误。)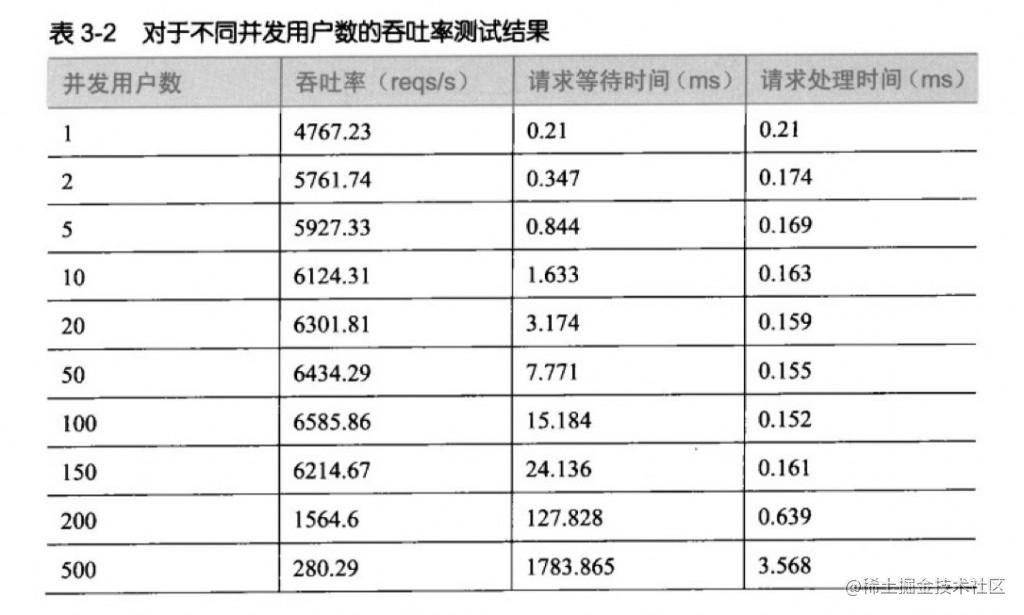
5.如何提高QPS
https://juejin.cn/post/6844903605036662797
由上述公式可知, QPS(TPS)= 并发数/平均响应时间,增大分母,减小分子:
5.1 增大并发数
(这里并发数的意思和之前又不一样了?可以理解为服务器能够连接的数目?)
- 比如增加服务器并发的线程数,启动和服务器性能匹配的线程数,可以更多满足服务请求。
- 加数据库的连接数,预建立合适数量的连接实例,形成连接池。
- 后端服务尽量无状态话,可以更好支持横向扩容,满足更大流量要求。
- 调用链路上的各个系统和服务尽量不要单点,要从头到尾都是能力对等的,不能让其中某一点成为瓶颈。(所以在看一个系统时,要从请求链路角度来看?提问哪一部分会是瓶颈bottleneck?)
- RPC调用的尽量使用线程池,预先建立合适的连接数。
5.2 减少平均响应时间
-
请求尽量越前结束,越好,这样压力就不要穿透到后面的系统上,可以在各个层上加上缓存。(什么意思?)
-
流量消峰。放行适当的流量,处理不了的请求直接返回错误或者其他提示。
-
减少调用链(?具体是什么意思?)
-
优化程序
-
减少网络开销,适当使用
-
长连接优化数据库,建立索引
思路是从前往后?从请求直接返回错误,或者加缓存,或者处理时优化逻辑,或者是到数据库这里,优化数据库查询等操作。
后续再了解:https://testerhome.com/topics/25499

 浙公网安备 33010602011771号
浙公网安备 33010602011771号