
torch中 lr_scheduler
转自:https://zhuanlan.zhihu.com/p/380795956
1.torch.optim.lr_scheduler.ReduceLROnPlateau
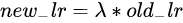
定义:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10,
threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
解释:
mode(str)模式选择 有 min和max两种模式 min表示当指标不再降低(如监测loss) max表示当指标不再升高(如监测accuracy)。factor(float)学习率调整倍数(等同于其它方法的gamma) 即学习率更新为 lr = lr * factor。-
patience(int)忍受该指标多少个step不变化 当忍无可忍时 调整学习率。 -
verbose是否每次改变都输出一次lr的值(单词的意思就是“冗长的” 默认是False。 threshold(float)配合threshold_mode使用 默认值1e-4 作用是用来控制当前指标与best指标的差异。??min_lr(float or list)学习率下限 可为float或者list 当有多个参数组时 可用list进行设置。
2.例子
skorch.callbacks.LRScheduler( policy=torch.optim.lr_scheduler.ReduceLROnPlateau, patience=5, factor=0.1, min_lr=1e-6, # **model_utils.REDUCE_LR_ON_PLATEAU_PARAMS, ),
即5个周期不变之后,就会以0.1降低学习率,学习率初始是1e-4,最小不小于1e-6。
例子2:
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9) >>> scheduler = ReduceLROnPlateau(optimizer, 'min') >>> for epoch in range(10): >>> train(...) >>> val_loss = validate(...) >>> # Note that step should be called after validate() >>> scheduler.step(val_loss)
是否还需要optimizer的zero_grad()及step()?上述链接中也给出了解答。
3.更新顺序
model = [Parameter(torch.randn(2, 2, requires_grad=True))] optimizer = SGD(model, 0.1) scheduler1 = ExponentialLR(optimizer, gamma=0.9) scheduler2 = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1) for epoch in range(20): for input, target in dataset: optimizer.zero_grad() output = model(input) loss = loss_fn(output, target) loss.backward() optimizer.step() scheduler1.step() scheduler2.step()
说明optimizer在batch_size中是正常更新的,scheduler1的更新是在经过了一个完成的epoch之后进行的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号