
atomic原子操作 c++
转自:https://zhuanlan.zhihu.com/p/107092432,讲的很好。
1.原子操作
原子操作,就是多线程程序中“最小的且不可并行化的”操作。对于在多个线程间共享的一个资源而言,这意味着同一时刻,多个线程中有且仅有一个线程在对这个资源进行操作,即互斥访问。
C++11 对常见的原子操作进行了抽象,定义出统一的接口,并根据编译选项/环境产生平台相关的实现。新标准将原子操作定义为atomic模板类的成员函数,囊括了绝大多数典型的操作——读、写、比较、交换等。
//atomic是一个模版类 template <class T> struct atomic
将变量定义为原子类型,就不需要为它显示地调用加锁、解锁的API,线程就能够对共享数据进行互斥地访问。 原子操作在多线程开发中经常用到,比如在计数器,序列产生器等地方,这类情况下数据有并发的危险,但是用锁去保护又显得有些浪费,所以原子类型操作十分的方便。
2.类型与操作
//定义数据类型,这两种效果是一样的,但在6-2的表格中,其他非整型的声明,可用的操作类型不同,
//最好还是用后一种声明方式,可用的操作类型更多。 std::atomic_int <----> std::atomic<int>
支持的数据类型,可以看到只支持基本的数据类型,布尔、整型、字符,不支持向量等复杂的类型。
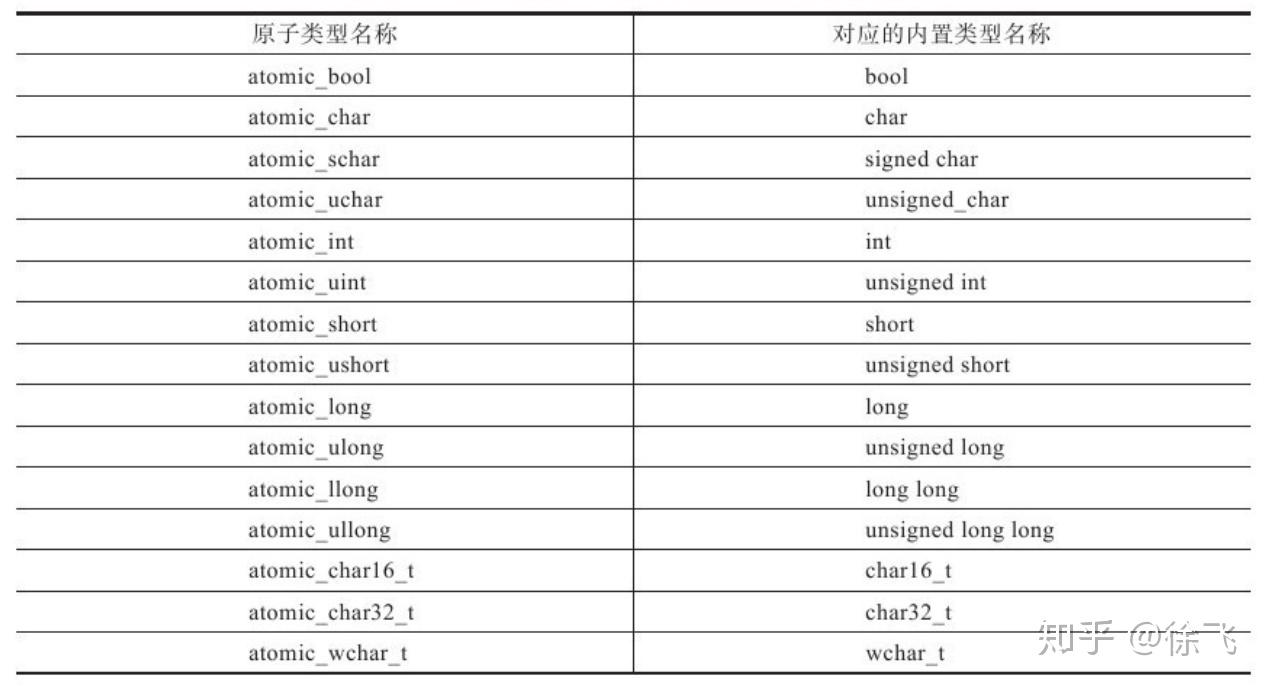
常用的操作:
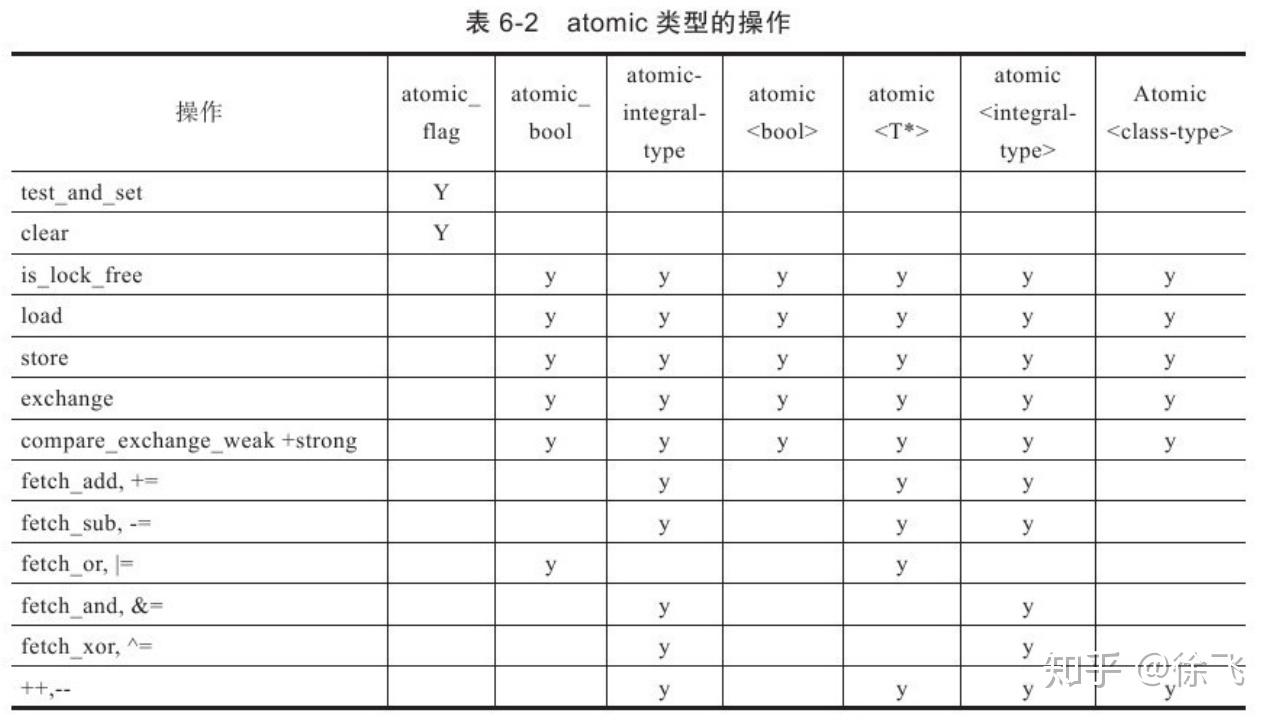
store接口定义:
void atomic<T>::store( T desired, std::memory_order order = std::memory_order_seq_cst ) volatile noexcept;
但在存取数据的时候必须要显式地调用load和store吗?https://stackoverflow.com/questions/18850752/must-i-call-atomic-load-store-explicitly
不是的,直接访问和用🟰赋值也都是原子的,和显式调用是一个效果。
atomic<T>::operator Tandatomic<T>::operator=are equivalent toatomic<T>::loadandatomic<T>::storerespectively.
3.效率
https://blog.csdn.net/yzf279533105/article/details/90605172,这篇文章有详细的代码,
测试代码:


#include<iostream> #include<atomic> #include<thread> #include<vector> #include<atomic> using namespace std; atomic<int> num (0); // 线程函数,内部对num自增1000万次 void Add() { for(int i=0;i<10000000;i++) { num++; } } int main() { clock_t startClock = clock(); // 记下开始时间,cpu时钟时间 // 3个线程,创建即运行 thread t1(Add); thread t2(Add); thread t3(Add); // 等待3个线程结束 t1.join(); t2.join(); t3.join(); clock_t endClock = clock(); // 记下结束时间 cout<<"耗时:"<<endClock-startClock<<",单位:"<<CLOCKS_PER_SEC<<",result:"<<num<<endl; return 0; }
使用互斥锁的耗时:耗时:3897908,单位:1000000,result:30000000 使用atmic变量耗时:耗时:2078330,单位:1000000,result:30000000
可见atomic效率是更高的,而且不用有加锁的语句,更neat。
4. 内存模型
通常情况下,内存模型是一个硬件上的概念,表示的是机器指令(或者将其视为汇编指令也可以)是以什么样的顺序被处理器执行的。现代的处理器并不是逐条处理机器指令的。弱顺序的内存模型可以进一步挖掘指令中的并行性,提高指令执行的性能。在C++11标准中,可以让程序员为原子操作指定所谓的内存顺序:memory_order。知乎链接中给出了一个ValueSet和Observer的例子很好理解。枚举如下:
typedef enum memory_order { memory_order_relaxed, // 松散内存顺序 memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, memory_order_seq_cst } memory_order;

原子变量的通用接口使用store()和load()方式进行存取,可以额外接受一个额外的memory order参数,而不传递的话默认是最强模式Sequentially Consistent。
例子:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
using namespace std;
atomic<string*>ptr;
atomic<int> data;
void Producer()
{
string*p=new string("Hello");
data.store(42,memory_order_relaxed);
ptr.store(p,memory_order_release); // 保证了在此之前对 data 的写操作对其他线程可见。
}
void Consumer()
{
string*p2;
while(!(p2=ptr.load(memory_order_consume)))
;
assert(*p2=="Hello");//总是相等
assert(data.load(memory_order_relaxed)==42);//可能断言失败
}
int main()
{
thread t1(Producer);
thread t2(Consumer);
t1.join();
t2.join();
}
- memory_order_relaxed:不对内存操作施加任何顺序限制,只保证原子性。
- memory_order_release:对之前的所有写操作进行排序,使得在此操作之前的所有写操作都对其他线程可见。
assert可能失败的断言:由于 data.load(memory_order_relaxed) 使用的是 memory_order_relaxed,这个加载操作并不保证顺序。虽然 memory_order_release 保证了 ptr.store 之前的所有写操作对其他线程可见,但 memory_order_relaxed 并不确保 data.load 的结果一定是最新的。由于编译器和硬件的优化,加载操作可能会在 ptr.load 成功之前或者之后执行,所以有可能看到旧值或者新值,导致断言失败。
5.atomic_store方法
https://en.cppreference.com/w/cpp/atomic/atomic_store
template< class T > void atomic_store( std::atomic<T>* obj, typename std::atomic<T>::value_type desired ) noexcept; template< class T > void atomic_store_explicit( std::atomic<T>* obj, typename std::atomic<T>::value_type desired, std::memory_order order) noexcept;
原子性地存储,还可以指定内存顺序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号