torch.optim.Adam优化器参数学习
1.参数
https://blog.csdn.net/ibelievesunshine/article/details/99624645
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)[source]
- params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
- lr (
float, 可选) – 学习率(默认:1e-3) - betas (Tuple[
float,float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999) - eps (
float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8) - weight_decay (
float, 可选) – 权重衰减(L2惩罚)(默认: 0)
2.算法
https://arxiv.org/pdf/1412.6980.pdf

可以看到,beta参数是用来更新m、v这两个动量向量和梯度的,梯度经过动量估计之后代替了SDG中的直接用梯度来更新参数。
α也就是lr学习率,用来更新参数,作为一个步长吧。
weight_decay 是针对最后更新参数的时候,给参数加的一个惩罚参数,
![]()
总结:lr是在更新梯度的时候用到的,weight_decay权重衰减是在损失函数中的模型参数的权重,更新参数时用到的。
总的loss中加入了一个对权重的限制,防止过大产生过拟合现象,
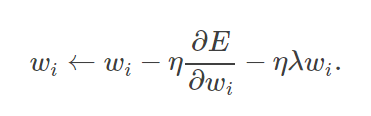
在参数更新时反映出来,正则化参数λ决定了你如何权衡原始损失E和较大的权重惩罚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号