
RoBERTa模型学习
1.byte-level text encoding
https://zhuanlan.zhihu.com/p/170656789
BPE(Byte-Pair Encoding)该方法使用bytes(字节)作为基础的子词单元,这样便把词汇表的大小控制到了5w。它可以在不需要引入任何未知字符前提下对任意文本进行编码,这是在GTP2中实现的,roberta也采用了这种编码方式。
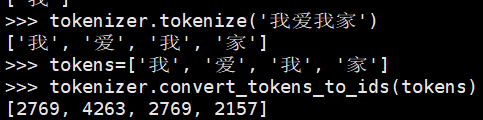
上面这个是bert的编码方式,下面的是roberta:

可以看到编码方式是非常不同的。
BERT原始版本使用一个字级(character-level)的BPE词汇表,大小是3w,是用启发式分词规则对输入进行预处理学习得到的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号