VAE原理再理解||各种变形
转自:http://www.gwylab.com/note-vae.html
1.VAE模型架构
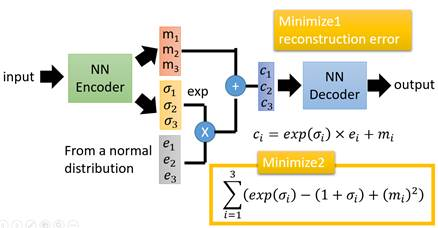
损失函数方面,除了必要的重构损失外,VAE还增添了一个损失函数(见上图Minimize2内容),这同样是必要的部分,因为如果不加的话,
整个模型就会出现问题:为了保证生成图片的质量越高,编码器肯定希望噪音对自身生成图片的干扰越小,于是分配给噪音的权重越小,这样只需要将(σ1, σ2, σ3)赋为接近负无穷大的值就好了。(那么在ci中,第一项就为0了,就退化为了自编码器。)
所以,第二个损失函数就有限制编码器走这样极端路径的作用(如果此时再赋值 为负无穷大,那么第二项就为正无穷大,但是总体是要minimize它的,所以不会使得σ负无穷大了),这也从直观上就能看出来,![]() 处取得最小值(但是σ实际上不会是0的),于是(σ1, σ2, σ3)就会避免被赋值为负无穷大。
处取得最小值(但是σ实际上不会是0的),于是(σ1, σ2, σ3)就会避免被赋值为负无穷大。
2.作用原理
对于生成模型而言,主流的理论模型可以分为隐马尔可夫模型HMM、朴素贝叶斯模型NB和高斯混合模型GMM,而VAE的理论基础就是高斯混合模型。
什么是高斯混合模型呢?就是说,任何一个数据的分布,都可以看作是若干高斯分布的叠加。
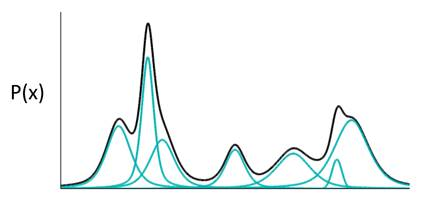
如果P(X)代表一种分布的话,存在一种拆分方法能让它表示成图中若干浅蓝色曲线对应的高斯分布的叠加。有意思的是,这种拆分方法已经证明出,当拆分的数量达到512时,其叠加的分布相对于原始分布而言,误差是非常非常小的了。
那么对于离散值来说:
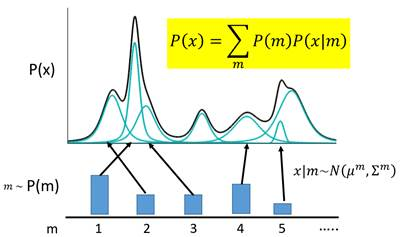
m代表着编码维度上的编号,譬如实现一个512维的编码,m的取值范围就是1,2,3……512。m会服从于一个概率分布P(m)(多项式分布)。
m表示每一个样本属于一个高斯分布的概率吧,m也服从一个上述的多项式的概率分布,那么总的px就可以表示为这些分布的叠加。
现在编码的对应关系是,每采样一个m,其对应到一个小的高斯分布![]() ,P(X)就可以等价为所有的这些高斯分布的叠加,即上图中黄色部分。
,P(X)就可以等价为所有的这些高斯分布的叠加,即上图中黄色部分。
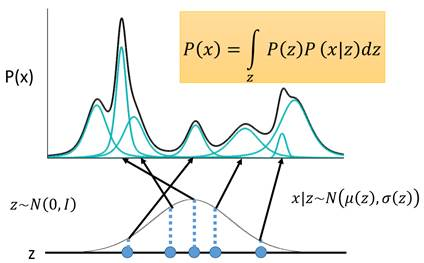
那么这个是针对连续的,z相当于m,z不是多项式分布,而是一个高斯分布。那么求和变为了求积分。
3.演进模型
https://zhuanlan.zhihu.com/p/68903857,讲了个大概,可以看看。
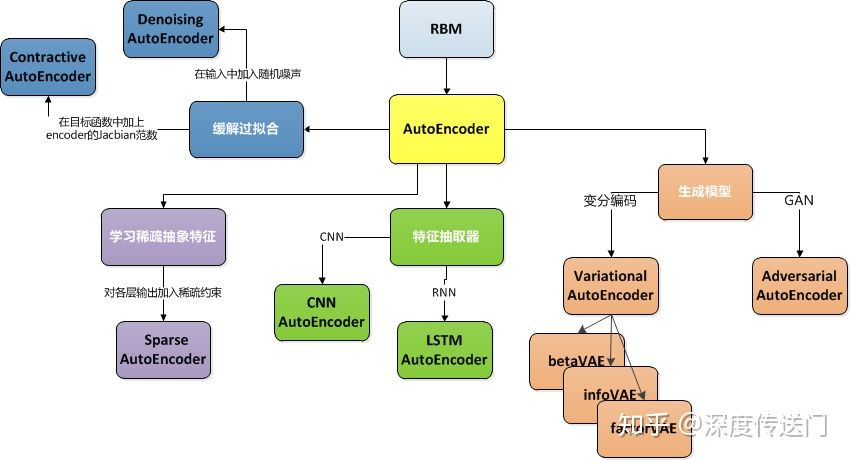
4. 后验坍缩
https://datascience.stackexchange.com/questions/48962/what-is-posterior-collapse-phenomenon
the model ends up relying solely on the auto-regressive properties of the decoder while
ignoring the latent variables, which become uninformative. 该模型最终仅依赖于解码器的自回归属性,而忽略了潜在变量,这些变量变得无用。

当后验没有坍缩的时候,每个维度都是从对应的输入的μ和σ采样的,即编码器仍能从x中学习到有用的信息μ和σ。

如果是坍缩的话,那么对任意的x都有相同的μ和σ,这里表示为了常数a、b,每次生成的x也都很相似,也就是z不具有从每个x中学习到的特异性了。
5.为什么VAE隐空间要选正态分布作为先验?
https://www.zhihu.com/question/359919018
重采样中的z就是服从正态分布,而正态分布的分布方差低,计算简单,。。先这么理解吧。
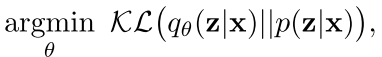
在这里,p是标准正态分布。
https://zhuanlan.zhihu.com/p/34998569
选定Z服从标准正态分布是为了给Z添加约束,而标准正态分布就可以看为是为了省事,而且实验发现因为它有效。
正态分布中又正好有均值和方差,分别用来重构和添加噪声,以免退化为AE。
重构就是为了模型编码能生成均值为0的Z,让它学习到的0均值。而σ方差就是为了添加接近1的噪声,即KL散度。
损失函数=重构loss+KL散度,一开始重构比较大,主要降低第一项,那么第二项就会相对升高,不用服从正态分布,主要管理均值而不管方差了。
随着训练进行,重构损失下降,KL相对来说上升,在均值降低的同时增大方差,就能够学习到每个样本特征,而不是学一个普遍特征。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号