
GAN损失函数
https://zhuanlan.zhihu.com/p/33752313,讲的不错。
1.损失函数
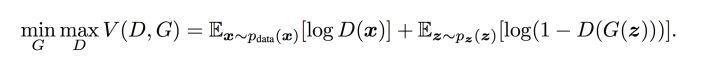
第一项主要是针对真实样本的,第二项是针对生成样本的损失。

//判别器是尽可能地判别出是真实数据还是生成数据,我一直以为是尽可能判别不出呢。。。
2.训练过程

可以看到是先确定G,优化D,确定了优化D之后,再优化G,然后循环进行上面的过程。
3.GAN的缺点
https://zhuanlan.zhihu.com/p/58260684

当固定Generator时,最优的Discriminator是

在面对最优Discriminator时,Generator的优化目标就变成了

如果把Discriminator训练到极致,那么整个GAN的训练目标就成了最小化真实数据分布与合成数据分布之间的JS散度。
有关JS散度的目标函数会带来梯度消失的问题。也就是说,如果Discriminator训练得太好,Generator就无法得到足够的梯度继续优化,而如果Discriminator训练得太弱,指示作用不显著,同样不能让Generator进行有效的学习。这样一来,Discriminator的训练火候就非常难把控,这就是GAN训练难的根源。
//2021-4-5更新——————
4.基本训练过程
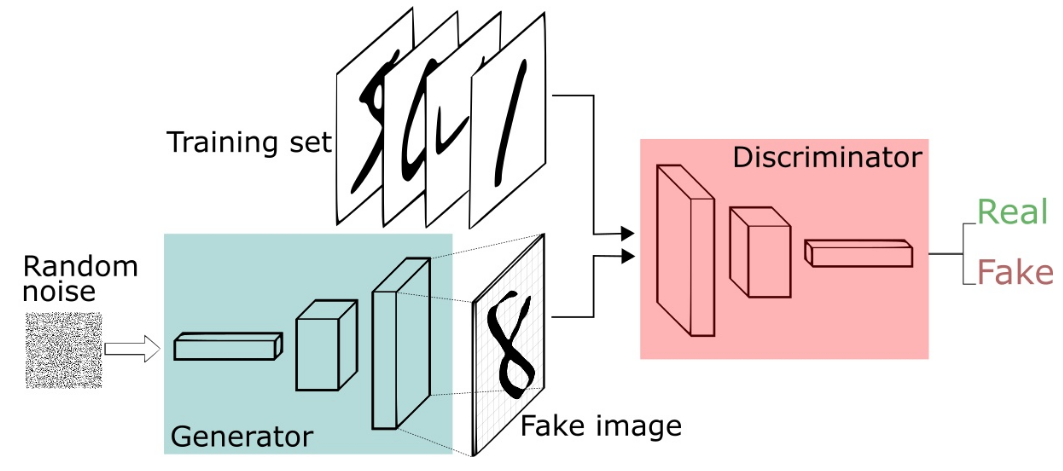
虽然图中画的是真实和生成图片同时进入判别器,但实际上是分阶段进入的。

使用交叉熵损失,针对判别器D和生成器G有不同的优化器,是分阶段优化的。
4.1 训练判别器D
基本分为4个步骤:
①向判别器D输入真实图片,获取输出,计算与真实label交叉熵损失;
②用生成器G生成虚假图片;
③将虚假图片输入判别器D,获取输出,计算与虚假label交叉熵损失;
④更新判别器D的参数
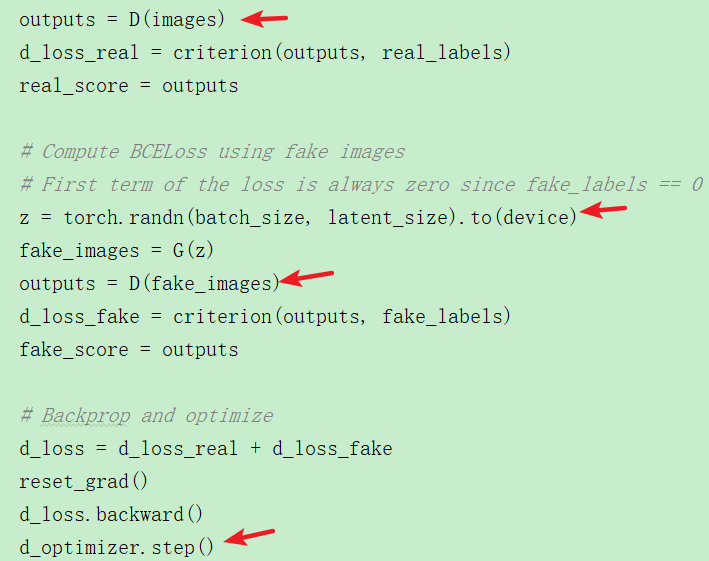
计算损失时分别计算的是真实的图片与真实的label,虚假的图片与虚假的label,目的是让判别器尽可能地分辨出真伪图片。
4.2 训练生成器G
基本分为3个步骤:
①生成虚假image;
②向判别器D输入虚假image,计算和真实label的交叉熵;
③更新G的参数
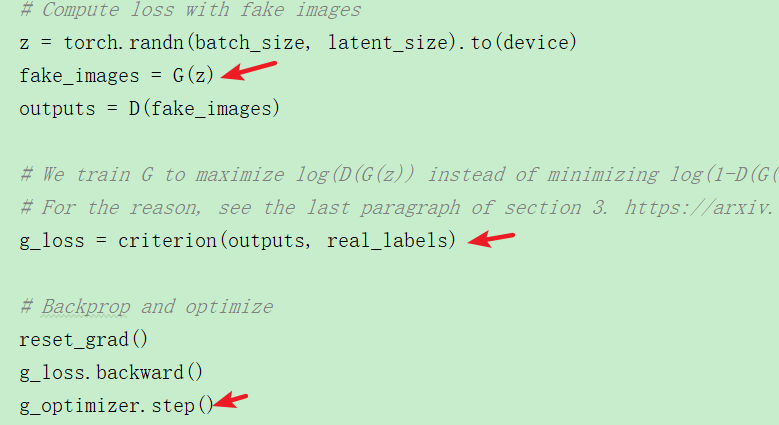
训练G的目的是尽可能生成和真实图片相似的image。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号