transformer的encoder和decoder学习
https://www.infoq.cn/article/lteUOi30R4uEyy740Ht2,这个后半部分讲的不错!
1.Transformer Encoder
(N=6 层,每层包括 2 个 sub-layers):
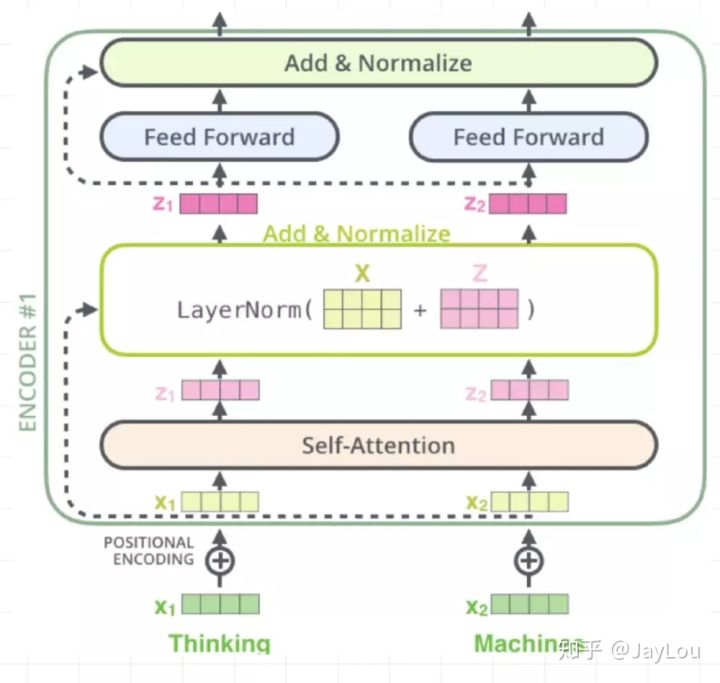
上面这个图真的讲的十分清楚了。
- multi-head self-attention mechanism多头自注意力层: 输出z的shape应该是和x一样的,既然能在残差网络部分相加。
- 全连接网络:
![]() 使用relu作为激活,并且使用了残差网络:
使用relu作为激活,并且使用了残差网络:![]()
2.Decoder

- Masked multi-head self-attention mechanism:由于是序列生成过程,所以在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做 Mask。
- Position-wise Feed-forward Networks全连接层:同 Encoder。
- Encoder-Decoder attention 计算。不同于self-att。
Encoder-Decoder attention与self-att的不同:
前者的q来自解码的输入,kv来自编码输出;后者的qkv来源均是编码的输入。
3.Transformer在GPT和BERT中的应用?
-
GPT 中训练的是单向语言模型,其实就是直接应用 Transformer Decoder;
- Bert 中训练的是双向语言模型,应用了 Transformer Encoder 部分,不过在 Encoder 基础上还做了 Masked 操作;
BERT Transformer 使用双向 self-attention,而 GPT Transformer 使用受限制的 self-attention,其中每个 token 只能处理其左侧的上下文。双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,decoder 是不能获要预测的信息的。
双向 self-attention的意思就是计算的att是针对整个句子的吧。而不是只关注左边或者右边。
学习了。
4.Decoder中seq mask问题
https://www.zhihu.com/question/369075515,这个回答的蛮好的!
总的来说训练时,decoder是并行的,在计算第i个输出的时候,只能看到i之前的输出,而不能看到它后面的,所以就用一个三角矩阵来进行mask,让它不能看到后面的内容。
https://www.zhihu.com/question/337886108,这个讲了shift right操作:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号