
IMDB情感分类学习
需要学习链接:
使用pandas做预处理,https://blog.csdn.net/mpk_no1/article/details/71698725
https://www.jianshu.com/p/8d3f929c9444
1.想法:
1.首先是要读取数据集,建立字典,将word转为id准备输入;
2.想获取数据文本的长度分布,然后做截断,但不知道怎么写;
但是链接中考虑的更全面
1.去掉非ASCII字符,2.去掉换行符,3.转换为小写。
https://blog.csdn.net/icbm/article/details/79747024 非ASCII字符:
[^\x00-\x7f]
比如这样。就是不在ASCII编码中的字符吧。
其中用到了pandas库,
2.使用RNN+一层MLP:
class RNN(nn.Module): def __init__(self, num_classes, input_size, hidden_size, num_layers, sequence_length): super(RNN, self).__init__() self.num_classes = num_classes self.num_layers = num_layers self.input_size = input_size self.hidden_size = hidden_size self.sequence_length = sequence_length#1000 self.embedding_size = embedding_size self.embedding = nn.Embedding(input_size, embedding_size)#这里使用的emb_size是200维的。 self.rnn = nn.RNN(input_size=embedding_size, hidden_size=hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size * 2, num_classes) # 相较于之前,又多了一个全连接层 def forward(self, x): # Initialize hidden and cell states # (num_layers * num_directions, batch, hidden_size) for batch_first=True h_0 = self.init_hidden(x.size(0)) embeddings = self.embedding(x) # Reshape input embeddings.view(x.size(0), self.sequence_length, self.embedding_size) # Propagate input through RNN # Input: (batch, seq_len, input_size) # h_0: (num_layers * num_directions, batch, hidden_size) out, _ = self.rnn(embeddings, h_0) # 由于设置了batch_first=True,输出格式为(batch,seq_length,hidden_size) out=out.permute([1,0,2]) #需要赋值啊亲。 out = self.fc(torch.cat((out[0], out[-1]), -1)) return out.view(-1, num_classes) def init_hidden(self,size): return torch.zeros(self.num_layers, size, self.hidden_size).to(device)
trainloss和testloss一直都很高
epoch:0,train loss:0.7623,train accuracy:0.51,test loss 0.8200,test accuracy:0.52,time:32.62 epoch:1,train loss:0.7542,train accuracy:0.53,test loss 0.7367,test accuracy:0.52,time:31.89 epoch:2,train loss:0.7422,train accuracy:0.53,test loss 0.7173,test accuracy:0.51,time:32.06 epoch:3,train loss:0.7572,train accuracy:0.53,test loss 0.7470,test accuracy:0.53,time:31.55 epoch:4,train loss:0.7444,train accuracy:0.53,test loss 0.7474,test accuracy:0.51,time:31.59
3.尝试加入固定的embedding,glove的100维的
一点问题:
这里我在add_scalar的时候,要求输入,然后我就用这个zero生成了输出数据:
writer = SummaryWriter('runs/IMDB_RNN_500/') #simu_input=torch.zeros([batch_size,sequence_length,embedding_size]) #BUG:Expected tensor for argument #1 'indices' to have scalar type Long; but got torch.FloatTensor instead (while checking arguments for embedding) writer.add_graph(model,simu_input)
import torch a=torch.zeros([1,2,3]) print(type(a)) print(a.dtype) #输出: <class 'torch.Tensor'> torch.float32 #默认为float,而emb需要的是int
a=torch.zeros([1,2,3],dtype=torch.int) print(type(a)) print(a.dtype) #结果: <class 'torch.Tensor'> torch.int32 #这样设置就ok
torch中的dtypehttps://ptorch.com/news/187.html

最终还是选择了像这样对loader进行遍历iteration,...

dataiter = iter(train_loader) sentences,labels=dataiter.__next__() writer.add_graph(model,sentences.to(device)) runtimeWarning: Iterating over a tensor might cause the trace to be incorrect.
Passing a tensor of different shape won't change the number of iterations executed (and might lead to errors or silently give incorrect results). 'incorrect results).', category=RuntimeWarning) Expected hidden size (1, tensor(32), 100), got (tensor(2), tensor(32), tensor(100)) Error occurs, No graph saved
使用RNN保存了train和test的loss:


反正是损失一直都很高
4.将RNN换为双向LSTM/GRU
效果不错啊,双向LSTM!比单向的RNN好太多了
epoch:0,train accuracy:0.72,test accuracy 0.79,time:30.01 epoch:1,train accuracy:0.83,test accuracy 0.82,time:30.31 epoch:2,train accuracy:0.85,test accuracy 0.84,time:30.29 epoch:3,train accuracy:0.87,test accuracy 0.82,time:29.88 epoch:4,train accuracy:0.89,test accuracy 0.83,time:30.89
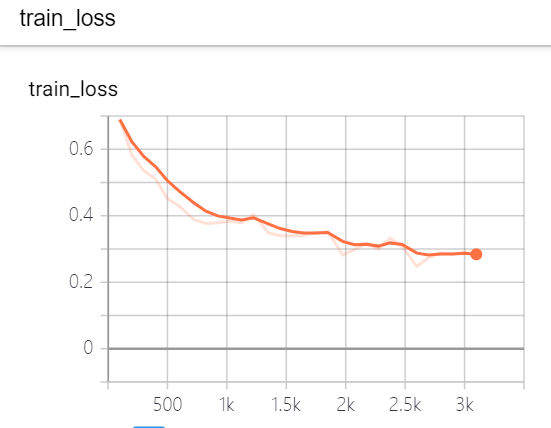
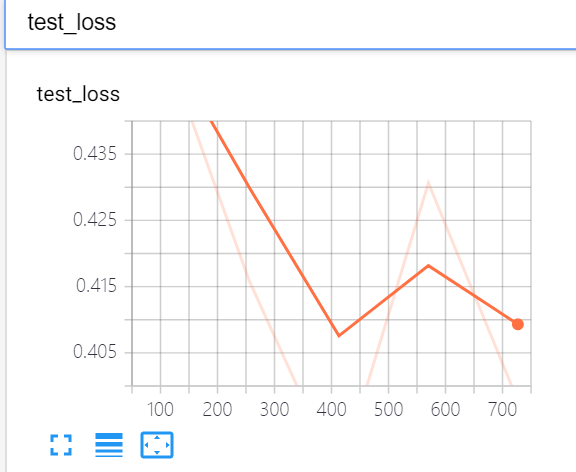
就精度各方面都有高,损失函数也在稳步下降,想把两个curve放到一个里。。但是这里横轴不一样,不可。
试下GRU:
epoch:0,train accuracy:0.77,test accuracy 0.76,time:30.42 epoch:1,train accuracy:0.84,test accuracy 0.82,time:30.37 epoch:2,train accuracy:0.86,test accuracy 0.81,time:30.59 epoch:3,train accuracy:0.87,test accuracy 0.82,time:30.74 epoch:4,train accuracy:0.87,test accuracy 0.83,time:29.96
效果也很不错的。
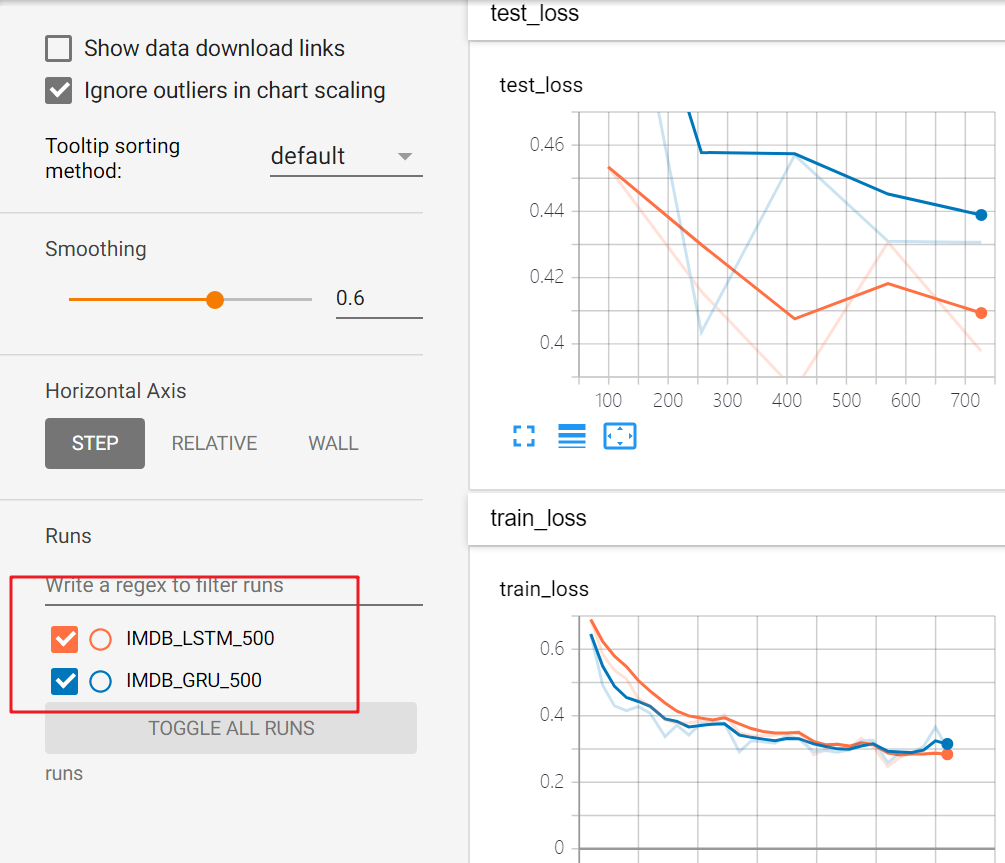
还是LSTM效果更好一点。
5.CNN做情感分类
这个链接里给出了一个CNN的text,所以就用一下,然后它的模型:

进行了实验:
import torch import torch.nn as nn m=nn.Conv2d(1,1,(3,100))#(输入通道数,输出通道数,(kernel_size1,kernel_size2)) pool=nn.MaxPool2d((498,1))#这里是进行pool的(kernel_size1,kenel_size2),没有什么疑问。 inp=torch.randn(32,1,500,100) a=m(inp) b=pool(a) #结果: >>> a.size() torch.Size([32, 1, 498, 1]) >>> b.size() torch.Size([32, 1, 1, 1])
结果:
epoch:0,train accuracy:0.72,test accuracy 0.77,time:3.59 epoch:1,train accuracy:0.77,test accuracy 0.78,time:3.14 epoch:2,train accuracy:0.79,test accuracy 0.78,time:3.19 epoch:3,train accuracy:0.79,test accuracy 0.80,time:3.20 epoch:4,train accuracy:0.79,test accuracy 0.79,time:3.17
效果还ok,但确实是速度非常地快。
7.将模型保存、读取模型进行预测,
或者直接写一个predict函数,其中读取test文件,然后进行预测,之后结果存储到文件,然后上传到kaggle预测啊。

1.这里在预测时每次都是单个的句子,那是否可以用batch_size一次预测32或64个句子呢?
2.这里对句子没有进行补0,补到500,那么对单个句子可能是适用的,如果是对一个batch的数据呢?是否需要补0?
3.还是说,针对这个预测,只能一句一句地预测?
这样直接写入的后果就是:
pred.append((testData['id'][i],label.data.max(1)[1].cpu()))#这里只是转到cpu上存储,它的类型还是个tensor #写入文件中 with open('./data/summit.tsv','w') as f: for data in pred: f.write(str(data[0])+'\t'+str(data[1]))

https://www.kaggle.com/c/word2vec-nlp-tutorial
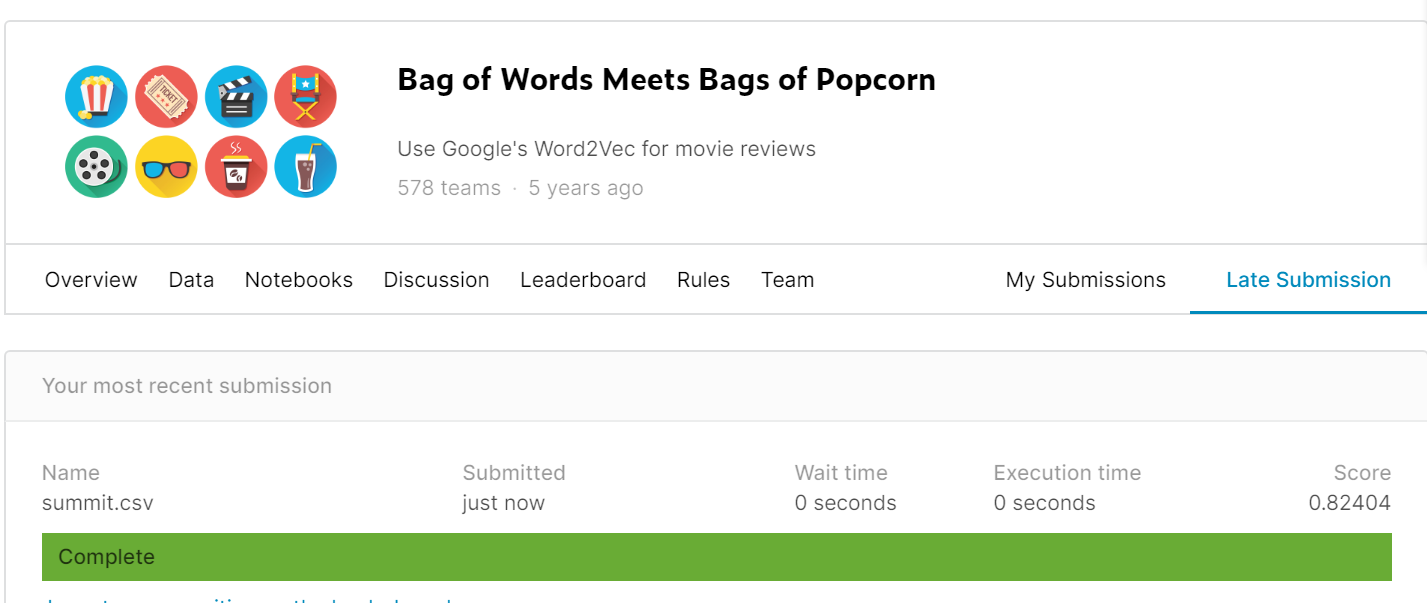
提交之后是0.82,要求是转换成csv形式的,那么就这道题来说,该怎么去提高呢?我有以下的几个想法可以尝试:
1.首先就是对文本做更多的预处理,参考那一个博客,正则化去掉一些,减少oov吧。
2.对word_embeding做fine tune。
3.尝试使用其他分类模型,如何text CNN会更快,或者更好?
4.调参。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号