
基于KNN对比学习的域外意图分类(KNN-Contrastive Learning for Out-of-Domain Intent Classification)阅读

发表在ACL2022上面的一篇文章
论文链接:KNN-Contrastive Learning for Out-of-Domain Intent Classification - ACL Anthology
Abstract
域外 (OOD) 意图分类是对话系统的一项基本且具有挑战性的任务。以前的方法通常将域内 (IND) 意图特征的区域(在特征空间中)限制为紧凑或隐式简单连接,假设没有 OOD 意图驻留,来学习判别性语义特征。然后,通常假定IND意图特征的分布服从假设分布(主要是高斯分布),并且该分布之外的样本被视为OOD样本。
在本文中,作者从OOD意图分类的性质出发,并探讨了其优化目标。并进一步提出了KNN-对比学习方法,这种方法利用IND意图的k-最近邻(KNN)来学习更有利于OOD检测的判别语义特征。
值得注意的是,基于密度的新颖性检测算法在该方法的本质中已根深蒂固,因此将其用作OOD检测算法是合理的,而无需对特征分布提出任何要求。在四个公共数据集上的大量实验表明,作者的方法不仅可以显着提高OOD检测性能,还可以改善IND意图分类,同时不需要限制特征分布。
Introduction
随着对话系统所面临的环境越来越开放,出现了越来越多的对话系统不知道如何处理的未知意图或域外(OOD)意图。为了解决这一问题,根据训练过程中是否使用了大量标记的OOD意图样本,将现有方法大致归纳为两类。
第一种方法(训练中使用OOD样本)认为OOD意图分类是一个(n+1)类分类任务,额外的(n+1)类代表标记的OOD意图。这些方法可能需要额外的大量且耗时的标记域外样本。此外,人工构建的具有人工感应偏置的OOD样本无法覆盖实际环境中的所有开放类别,因此这种方法存在一定的局限性。(参考链接:https://blog.csdn.net/anxiaomai520/article/details/123444586)
而作者关注的是另一种方法,它涉及两个阶段,学习犯罪语义特征与OOD检测。类内方差最小化和类间方差最大化一直被认为是解决如何学习有利于OOD检测的语义特征问题的本质,其是通过扩大IND和OOD意图之间的差距来促进检测。然后将高斯分布(或隐式)引入到学习到的意图特征的分布中,用于OOD检测。
其实OOD意图在语义空间中的实际位置并不受限制,它们可以出现在IND类之间,也可以出现在IND分布范围内。将分布在不同IND类别之间的OOD意图命名为OOD内部意图(inter),将分布在IND类别内或被局部IND意图样本组成的凸包包围的OOD意图称为OOD内意图(intra)。对于OOD内部意图,最小化类内方差和最大化类间方差可以降低被识别为IND的风险,而OOD内部意图由于与IND意图更接近,这种风险可能会增加。
同时,对IND语义特征分布进行高斯假设检验在临床全训练集中,发现只有57%的IND类符合高斯分布,这说明之前方法中OOD检测的高斯假设可能并不合理,针对这些问题,利用开放空间风险显式定义了OOD意图分类的优化目标。【封闭集:在训练时已知所有测试集;开放集识别:测试未知类,需要强泛化能力】
与以往只考虑 OOD内部意图的方法相比,本文提出了一种简单而有效的且同时考虑OOD内意向和OOD间意向的方法,即利用IND意图样本的k近邻作为正样本,并通过MoCo中的队列获取更多的负样本来学习区分性语义特征,进一步分析了该方法可以更好地降低开放空间风险的原因。直观地说,该方法在OOD意图周围留下了更多的余量,这可以确保使用基于基本密度的方法来进行OOD检测,而不需要对其分布进行任何假设。
贡献如下:
1. 遵循开放空间风险,明确OOD意图分类的优化目标,为求解OOD意图分类问题提供了一种范例。
2. 分析了现有方法的局限性,并提出了一种更好地降低经验风险和开放空间风险的新方法。
3. 在四个具有挑战性的数据集上展示了我们的方法,在不受特征分布限制的情况下实现一致的改进。
Related Work
Out-of-domain Detection(域外检测)
区分OOD,扩大IND和OOD之间的差异的以往方法:
1. 在高维空间中通过核函数寻找超平面或超球面来区分。
2. 提出了OpenMax模型,利用深度网络倒数第二层的得分来区分。
3. 基于最大softmax概率的基线。
4. 基于MSP添加了温度标度,添加扰动输入。
上述方法主要集中在计算机视觉上,并假设(或隐式)特征区域是紧凑的(单连通区域),许多研究工作都是在自然语言处理中进行的。
降低开放空间风险以往方法:
1. 通过高斯拟合收紧sigmoid函数的决策边界。
2. 学习具有边缘损失的判别性深度特征。
3. 使用高斯混合分布进行模型嵌入,以便于下游异常值检测。
4. 假设IND语义特征分布为高斯判别分析(GDA),并通过马氏距离识别域外样本。
5. 提出学习自适应循环决策边界,通过决策边界降低。
6. 提出了一个有监督的对比学习目标,以最大化类间方差和最小化类内方差。
这些方法还将特征分布限制在特征学习阶段或下游检测阶段,无法完全解决域外分类问题。
Contrastive Learning(对比学习)
广泛应用于无监督或自监督学习,以往方法通过点积的相似性,用InfoNCE损失来度量语义空间中样本对的相似性。为了获得更多的负样本用于对比学习,引入了动量对比学习(MoCo),构建了一个大型且一致的字典,有助于对比无监督学习。在不同领域普遍存在预训练模型(PTMs)并将PTMs与对比学习范式相结合,采用邻域,利用MoCo或记忆库获取足够的负样本。
Proposed Method
Objective of OOD Intent Classification
Open space risk(开放空间风险)
使用IND训练样本,开放空间可以定义为:
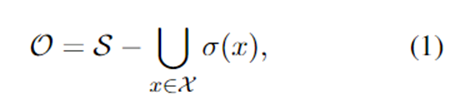
其中:σ是IND训练样本x跨越的局部(小)语义空间,x是所有IND训练样本和S的集合,包括开放空间O和剩余空间S。
考虑一个可测量的识别器(或判别器)f,对于IND意图f(x) = 1(> 0),否则f(x) = 0(<= 0),则可以根据勒贝格测度形成概率开放空间风险RO:
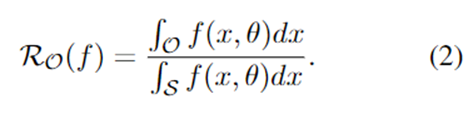
Objective of OOD Intent Classification(OOD意图分类的目标)
识别OOD意图首先需要学习意图表示,这在保证IND分类质量的同时也适应了下游检测。因此,引入了一个额外的优化目标,命名为经验风险Rε(f)。目标可以定义为:
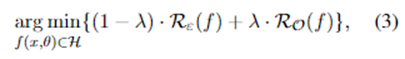
其中:λ是平衡经验风险和开放空间风险的超参数,H是函数空间。
Minimize Empirical Risk
优化上述目标,作者首先利用BERT来提取意图表示。给定第i条域内语句,得到了它的上下文嵌入[[CLS],T1,T2,…,TN]。对这些上下文令牌嵌入进行均值池化操作, 以获得句子语义表示Zi:

其中:Zi∈RH,N为序列长度,H为隐维数。
用简单的软最大交叉熵损失Lce优化经验风险:
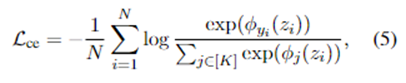
其中:ϕ(·)表示线性分类器,ϕj(zi)表示第j类的分数。
KNN-Contrastive Learning
由于缺乏OOD意图样本,无法直接优化开放空间风险。现有方法通过将同类IND样本拉到一起,将不同类别的样本分开来间接降低开放空间风险。然而,基于上述分析,这些方法可能会增加将OOD内意图识别为IND的风险。直观上,为了降低识别内部OOD意图为IND的风险,只需要将k近邻放在一起,同时将它们从不同的类意图样本中分开。为了实现这一目标,作者通过重写对比损失得到KNN对比损失 Lknn-cl:
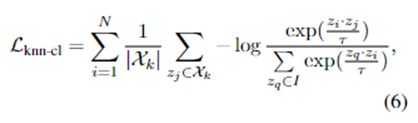
其中:Xk表示S是样本zi的k个近邻集合,I≡A{zj},A是类别与zj不同的样本集合。τ为温度超参数。
Momentum Contrast is All You Need
在进行KNN对比学习时,需要解决两个问题:
1. 批量大,选择的样本越多,越有可能找到k近邻;同时,还需要足够多的负样本来区分。
2. k近邻在训练过程中应该保持一致,否则KNN对比训练学习可能会不稳定。
遵循MoCo规则,我们还维护了一个包含IND样本的队列,并使用当前批次的特征对其进行更新,同时将最老的特征下线。队列将样本大小与批大小解耦,允许获得更多的负样本(好处是降低开放空间风险)。为了保持一致性,来自前几批的特征由一个缓慢更新的网络(编码器)编码,其参数是来自查询编码器(另一个网络)的参数的基于动量的平均值。结合softmax交叉熵损失和KNN对比学习损失,最终的微调目标学习区分性特征如下:
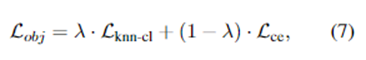
其中:λ 是平衡经验风险和开放空间风险的超参数。
Local Outlier Factor
为了更接近实际情况,倾向于在不假设IND意图潜在分布的情况下采用下游检测算法。因此,采用一种简单而通用的检测算法LOF算法,并随后计算LOF评分。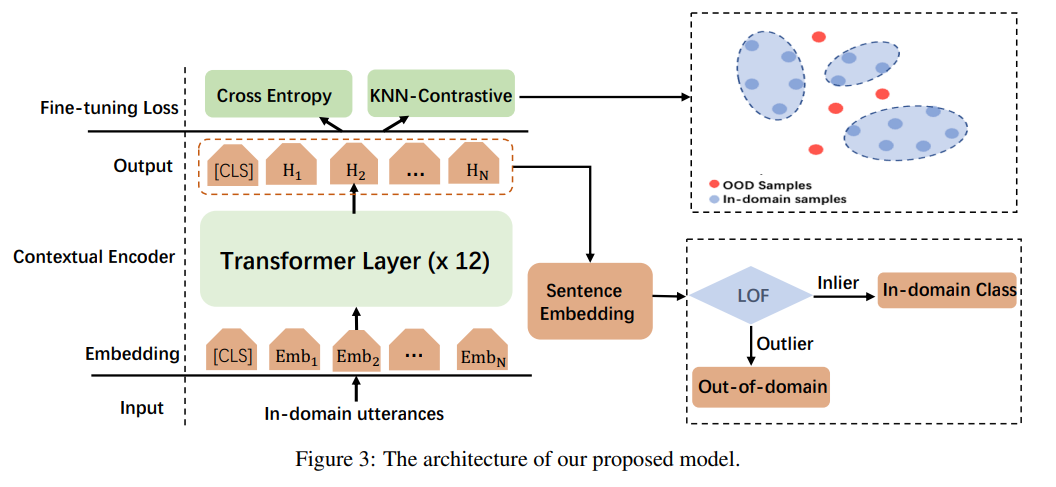
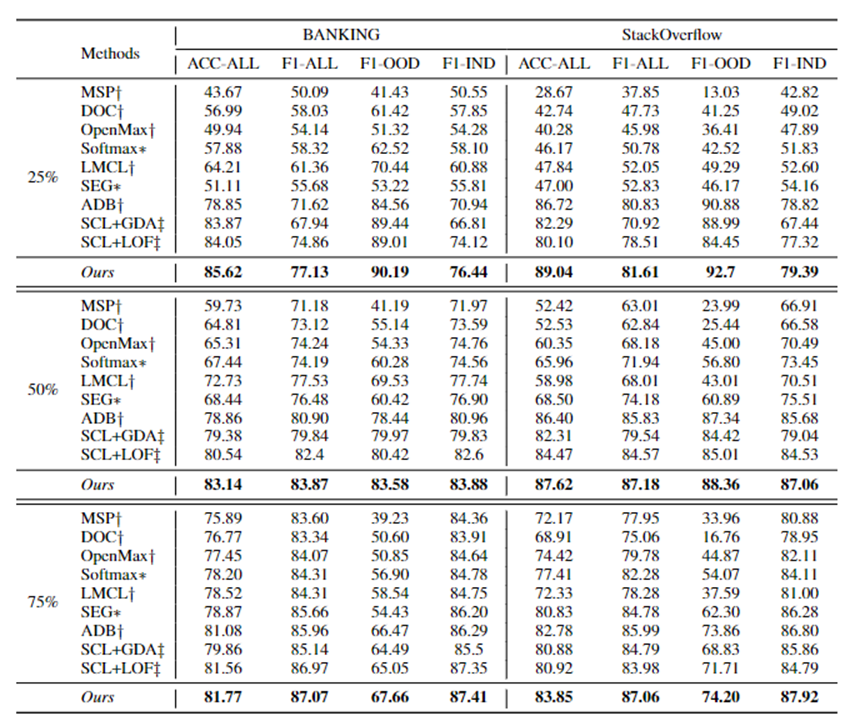
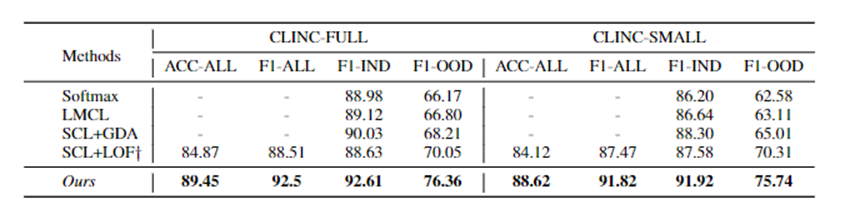
Experiments
Conclusion
本文明确了OOD意图分类的优化目标,分析了现有方法的局限性,并提出了一种简单而有效的学习判别语义特征的方法。该方法将IND意图的k个近邻集合在一起,并将它们从不同类别的样本中推开,以更好地降低经验风险和开放空间风险。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号