
使用Keras构建神经网络图像识别模型
一、Keras的结构与安装
1. Keras简介
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。
Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结果,如果有如下需求,可以优先选择Keras:
1)简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性);
2)支持CNN和RNN,或二者的结合;
3)无缝CPU和GPU切换。
2. Keras的模块结构
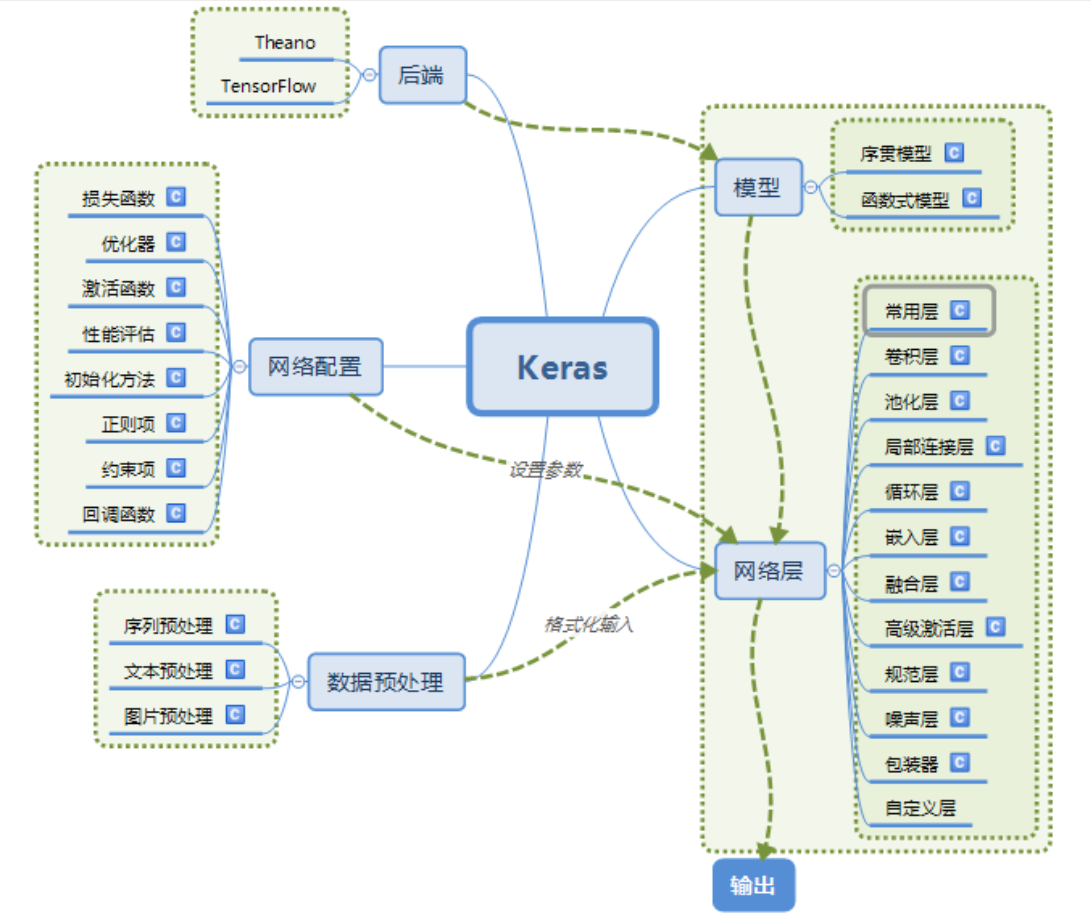
3. 使用Keras搭建神经网络的过程
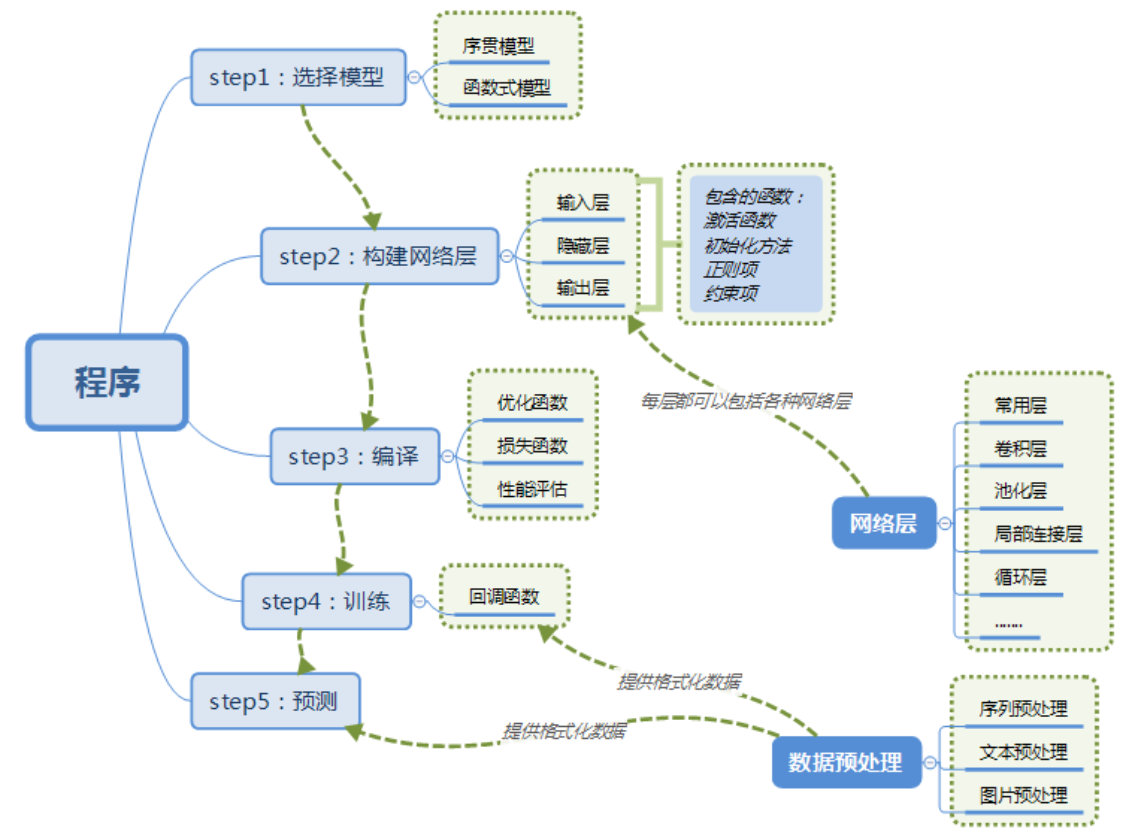
4. Anaconda3环境下Keras的安装教程
1)方法一
a)右键选择anaconda3用管理员权限打开,进入anaconda3的主界面,如图所示;

b)点击左边的environment,在右边的搜索栏内输入keras,点击跟前的选择Not installed,如图所示;
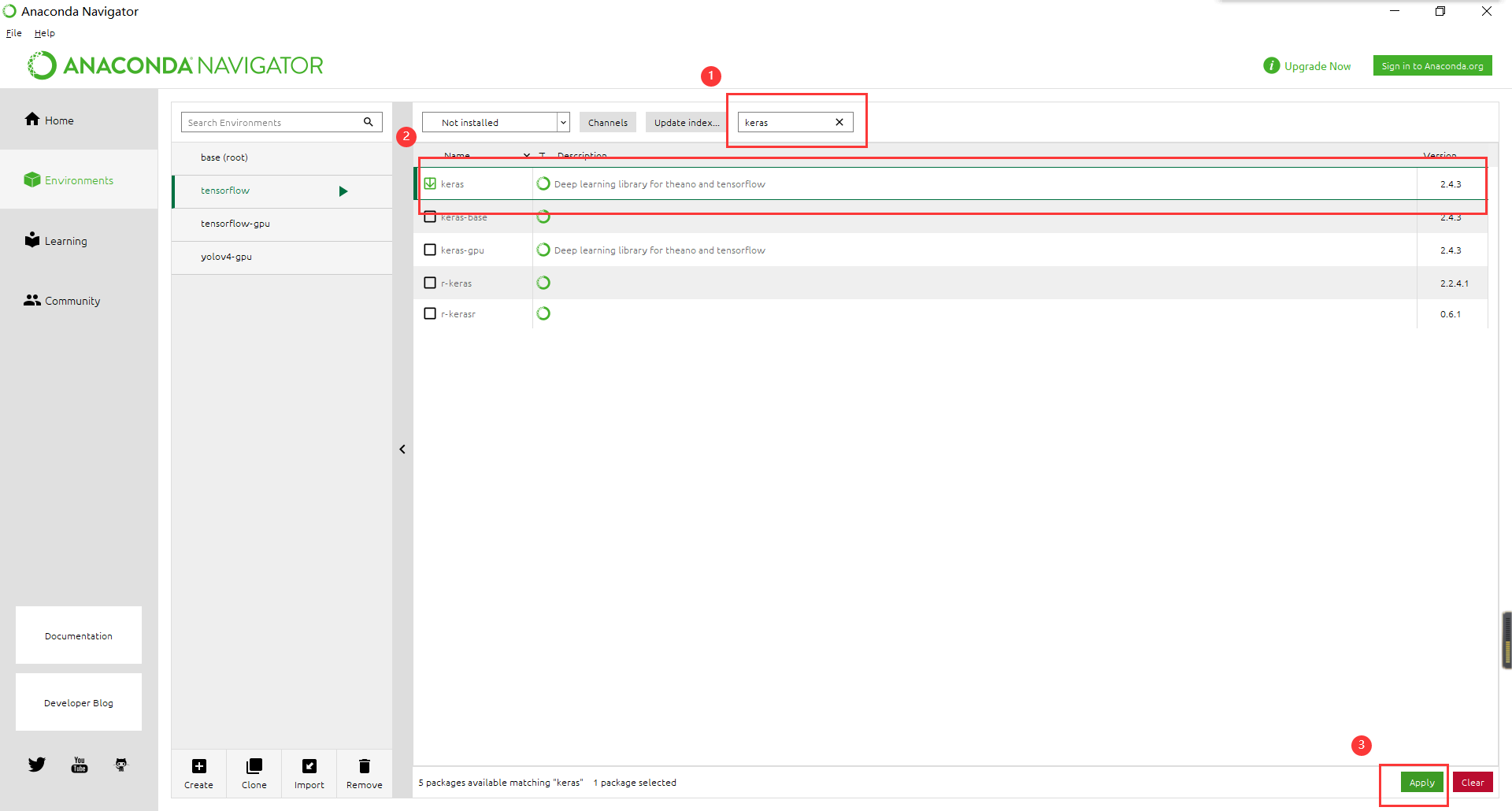
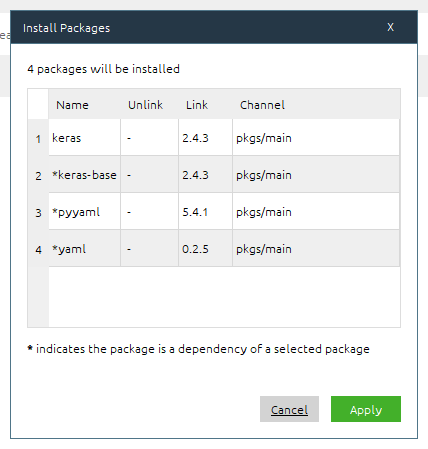
c)搜索到keras之后,右边会有点击安装的选择项,直接点击安装即可,安装时间可能有点长,请耐心等待。
2)方法二
a)在anaconda3下的script文件下进入cmd命令内,输入命令pip install keras,如图所示;
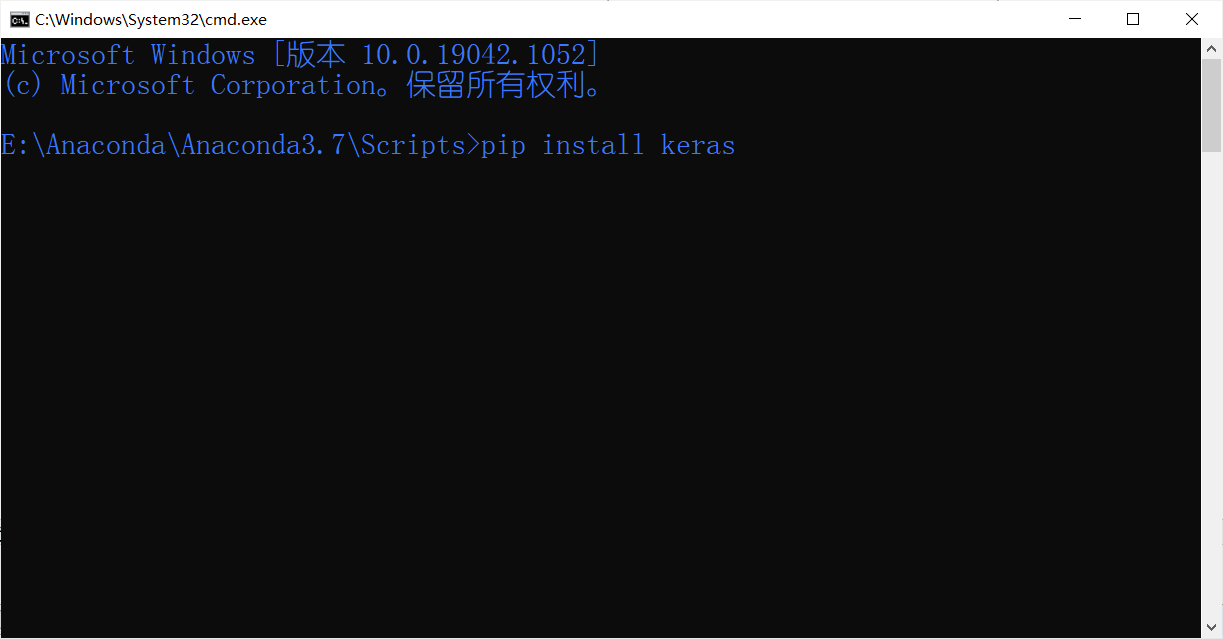
b)回车,运行成功后的结果如图所示。
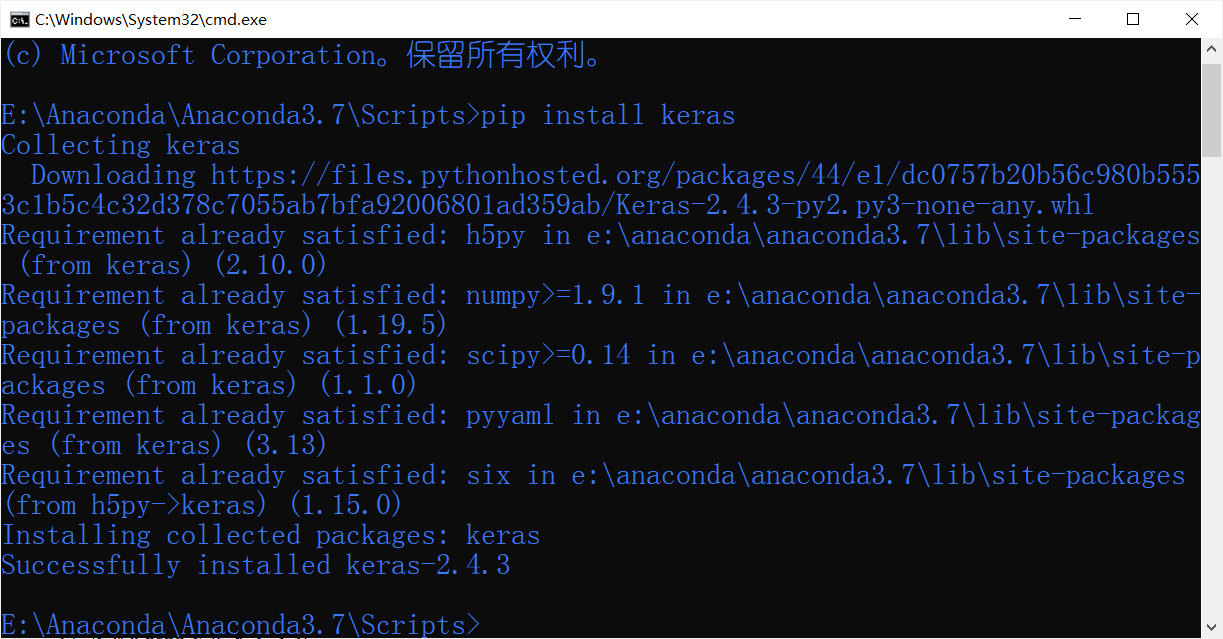
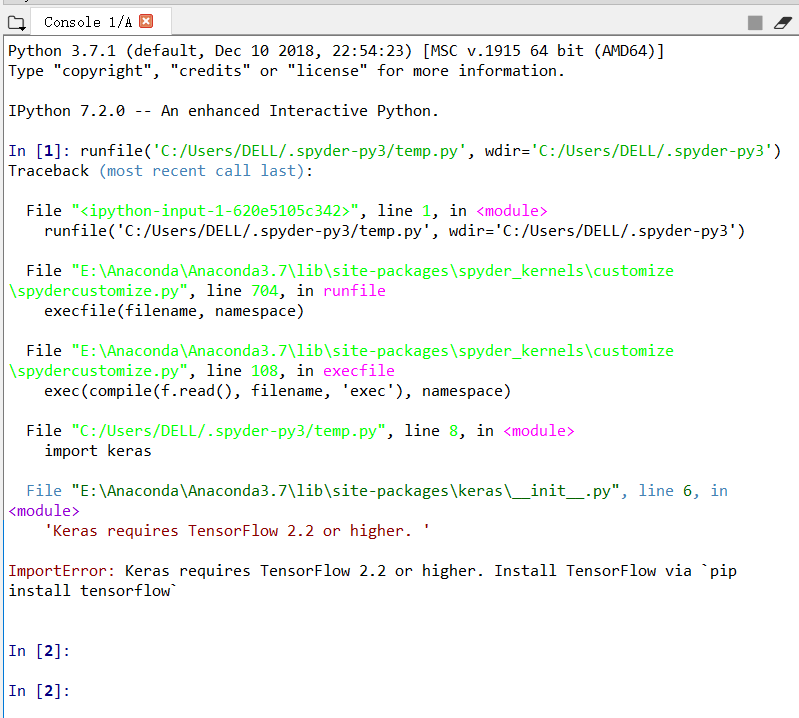
3)检验Keras安装是否成功
a)快速打开Anaconda3自带的Spyder编辑器,如图所示;

b)输入import keras,运行后查看,如图所示表示安装成功;

c)注意:可能会出现“ImportError: Keras requires TensorFlow 2.2 or higher. Install TensorFlow via `pip install tensorflow`”错误,说明安装的keras版本过高,降低版本,在anaconda3下的script文件下进入cmd命令内,输入命令pip install keras==2.2即可。

二、典型示例--手写识别模型
1. 目标
1)示例背景
给定多张 0 - 9 手写数字图像(集合),从中通过学习产生神经网络识别模型。使用该模型,能够对输入的一幅手写数字图像,识别出 0 - 9 的数字。
2)选取数据集
本模型将选取MNIST数据集进行训练测试。MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张 28*28 像素的灰度手写数字图片。
a)读入MNIST数据
测试下载MNIST数据代码如下(可能会很慢,建议用镜像下载):
from tensorflow.keras.datasets import mnist # 导入mnist数据集,需要保持网络畅通 # 训练数据:x_train是60000张28*28的数据,所以尺寸是60000*28*28,y_train是对应的数字,尺寸是60000*1;测试数据x_test和y_test同理 (x_train,y_train),(x_test,y_test)=mnist.load_data() print('x_shape:',x_train.shape) # (60000,28,28)
测试成功输出结果如下图:

b)展示MNIST部分数据
代码如下:
from tensorflow.keras.datasets import mnist import matplotlib.pyplot as plt (x_train,y_train),(x_test,y_test)=mnist.load_data() plt.subplot(3,3,1) plt.imshow(x_train[0]) plt.subplot(3,3,2) plt.imshow(x_train[1]) plt.subplot(3,3,3) plt.imshow(x_train[2]) plt.subplot(3,3,4) plt.imshow(x_train[3]) plt.subplot(3,3,5) plt.imshow(x_train[4]) plt.subplot(3,3,6) plt.imshow(x_train[5]) plt.subplot(3,3,7) plt.imshow(x_train[6]) plt.subplot(3,3,8) plt.imshow(x_train[7]) plt.subplot(3,3,9) plt.imshow(x_train[8]) plt.show()
结果如下图:

2. Keras构建手写识别模型
1)处理输入输出数据;
a)处理输入数据:由于每幅图像的每个像素作为一个神经网络的输入,所以一共有 28*28 = 784 个输入,需要对输入数据进行变换,即(60000,28,28)→ (60000,784),接着将像素值转换到 0 - 1 之间,以便加入到Keras神经网络模型中。代码如下:
# (60000,28,28) -> (60000,784) x_train=x_train.reshape(x_train.shape[0],x_train.shape[1]*x_train.shape[2]) x_test=x_test.reshape(x_test.shape[0],x_test.shape[1]*x_test.shape[2]) # 将像素值转换到0-1之间,便于应用神经网络 x_train=x_train/255 x_test=x_test/255
b)处理输出数据:需要将输出转换为one-hot的模式。one-hot编码又称为一位有效编码,是将分类变量作为二进制向量的表示,一般用于多分类识别。对于one-hot编码,举一个小例子,如下图:
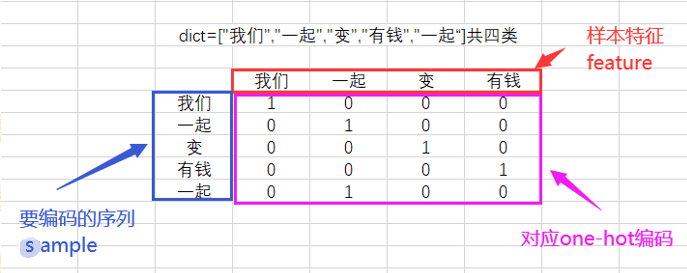
输出数据转换代码及其对应效果图如下:
import tensorflow.keras.utils as ut print("y_train:\n",y_train) print("y_test:\n",y_test) print("\nAfter the one-hot code conversion") y_train=ut.to_categorical(y_train) y_test=ut.to_categorical(y_test) print("y_train:\n",y_train) print("y_test:\n",y_test)

2)构建深度神经网络模型
如下图模拟需要构建的神经网络:

a)创建序贯模型,添加全连接层,以形成深度网络结构;
代码如下:
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense,Activation model = models.Sequential() # 向模型中添加层 model.add(layers.Conv2D(32, kernel_size=(5, 5), # 添加卷积层,深度32,过滤器大小5*5 activation='relu', # 使用relu激活函数 input_shape=(img_rows, img_cols, 1))) # 输入的尺寸就是一张图片的尺寸(28,28,1) model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层,过滤器大小是2*2 model.add(layers.Conv2D(64, (5, 5), activation='relu')) # 添加卷积层,简单写法 model.add(layers.MaxPooling2D(pool_size=(2, 2))) # 添加池化层 model.add(layers.Flatten()) # 将池化层的输出拉直,然后作为全连接层的输入 model.add(layers.Dense(500, activation='relu')) # 添加有500个结点的全连接层,激活函数用relu model.add(layers.Dense(10, activation='softmax')) # 输出最终结果,有10个,激活函数用softmax
b)生成模型(编译)和训练;
代码如下:
# 自动完成模型的训练过程 model.fit(X_train, Y_train, # 训练集 batch_size=128, # batchsize epochs=5, # 训练轮数 validation_data=(X_test, Y_test)) # 验证集
c)对训练结果进行评估。
代码如下:
# 定义损失函数、优化函数、评测方法 model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy']) # 打印运行结果,即损失和准确度 score = model.evaluate(X_test, Y_test) print('Test loss:', score[0]) print('Test accuracy:', score[1])
d)运行效果图

3)将构建好的网络模型应用于手写识别实战分类,并对分类结果进行预测
代码如下:
x_predict=X_test[0:9] y=model.predict(x_predict) print(y)
结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号