
Elasticsearch 使用
Elasticsearch
简介:Elasticsearch (ES)是一个强大的搜索引擎,是一个基于 Lucene 广泛应用于数据存储和搜索场景,ES 使用 java 进行开发。它提供了一个分布式、多用户能力的全文搜索引擎,具有高扩展性、高可用性等特点。
注意:Elasticsearch 所提供的是站内搜索功能。
站内搜索是指在一个网站内部进行信息检索功能,允许用户通过输入关键词等方式,快速找到网站内相关的网页、产品、文章、文档等内容。
例如在拼多多、京东、淘宝等网站搜索我们想要购买的商品;在抖音搜索我们想看的短视频等,这些都属于是站内搜索,而我们通常在浏览器网页或百度进行搜索就不属于是站内搜索了。
1. ES 环境搭建
1.1 ubuntu 中安装
说明:本章节的环境搭建主要是基于 Ubuntu 上的安装教程。
首先,确保系统是最新的:
sudo apt update
sudo apt upgrade -y
Elasticsearch 需要 Java 环境,推荐安装 OpenJDK 11:
sudo apt install openjdk-11-jdk -y
验证 Java 安装:
java -version
添加 Elasticsearch 仓库,导入 GPG 秘钥
# 系统上要首先安装上 wget ,添加 gpg 秘钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# 添加仓库
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
安装 ES
# 更新安装列表
sudo apt update
# 安装 es
sudo apt install elasticsearch -y
编辑配置文件,路径位于/etc/elasticsearch/elasticsearch.yml
sudo vim /etc/elasticsearch/elasticsearch.yml
# 设置网路的绑定
network.host: 0.0.0.0
discovery.seed_hosts: ["127.0.0.1"]
# 保存并退出
服务启动
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch # 设置开机自启动
# 检查服务状态
sudo systemctl status elasticsearch
验证安装
通过 HTTP 请求验证 Elasticsearch 是否运行:
curl -X GET "localhost:9200/"
如果看到类似以下输出,说明安装成功:
{
"name" : "your-hostname",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "abc123",
"version" : {
"number" : "7.x.x",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "abc123",
"build_date" : "2023-01-01T00:00:00.000Z",
"build_snapshot" : false,
"lucene_version" : "8.x.x",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
可选步骤的操作
配置防火墙
如果启用了 UFW 防火墙,允许 Elasticsearch 端口:
sudo ufw allow 9200
sudo ufw allow 9300
sudo ufw reload
安装 Kibana
Kibana 是 Elasticsearch 的可视化工具,安装步骤类似:
sudo apt install kibana -y
sudo systemctl start kibana
sudo systemctl enable kibana
Kibana 默认运行在 5601 端口。
安装 Logstash
Logstash 用于数据处理,安装步骤:
sudo apt install logstash -y
sudo systemctl start logstash
sudo systemctl enable logstash
1.2 docker 中安装
安装 docker 的步骤此处不在进行赘述,直接进行安装;
1.2.1 拉取镜像
# 使用命令进行指定版本的镜像拉取
docker pull elasticsearch:8.6.0
拉取镜像的时候容易出现网络的错误,因此需要将 docker 的镜像进行配置源;
sudo vim /etc/docker/daemon.json
# 将以下的内容写入文件内
{
"registry-mirrors": [
"https://2a6bf1988cb6428c877f723ec7530dbc.mirror.swr.myhuaweicloud.com",
"https://docker.m.daocloud.io",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://your_preferred_mirror",
"https://dockerhub.icu",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]
}
再次拉取镜像;
1.2.2 运行容器
使用 docker run 命令创建并且运行容器
sudo docker run -d \ # 基础命令
--restart=always \ # 异常重启
--name es \ # 容器的名字
--network es-net \ # 网络连接的模式
-p 9200:9200 \ # 网络端口映射
-p 9300:9300 \
--privileged \ # 赋予完全的权限
-v /home/whj/data/docker_els/data \ # 设置目录的挂的映射
-v /home/whj/data/docker_els/plugins: /usr/share/elasticsearch/plugins \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ # 设置虚拟环境
elasticsearch:8.6.0 # 镜像的名称, 根据自己的版本进行设置
# 整行的命令
sudo docker run -d --name=whj_es --network=es-net -p 9200:9200 -p 9300:9300 -v /home/whj/data/docker_els/data:/usr/share/elasticsearch/data -v /home/whj/data/docker_els/plugins:/usr/share/elasticsearch/plugins --privileged -e "discovery.type=single-node" -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" elasticsearch:8.6.0
启动容器之后,进入容器内部,设置密码的策略
docker exec -it es bash
# 跳转到 config 目录
cd config
# 关闭密码的安全验证
echo 'xpack.security.enabled: false' >> elasticsearch.yml
# 退出 docker,重启容器
docker restart whj_es
1.2.3 测试安装的情况
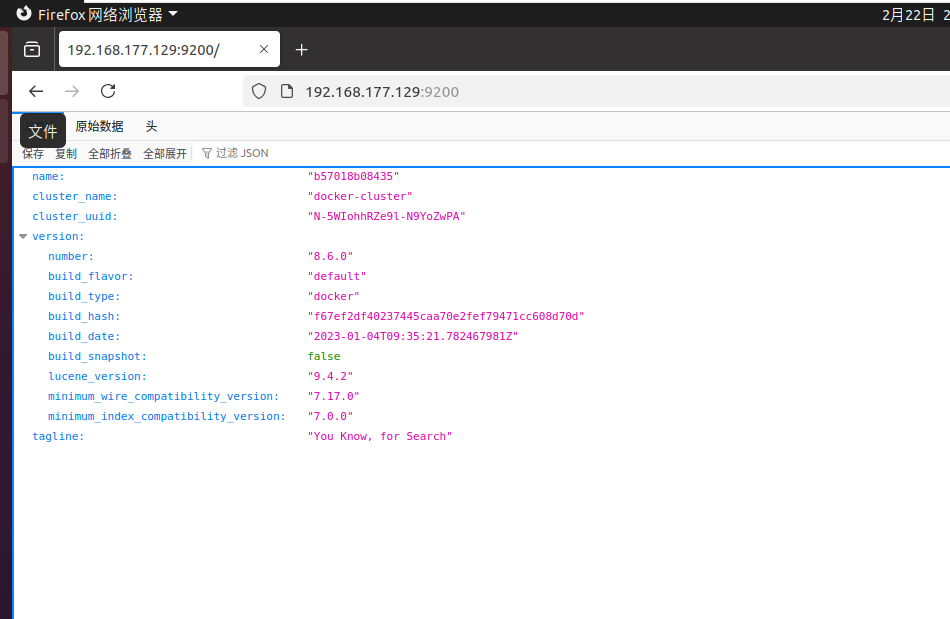
重启容器之后,打开浏览器输入
http:// 192.168.177.129:9200 # 根据自己电脑的IP 进行确定,看到类似的信息就是表示成功.
1.3 安装 Kibana
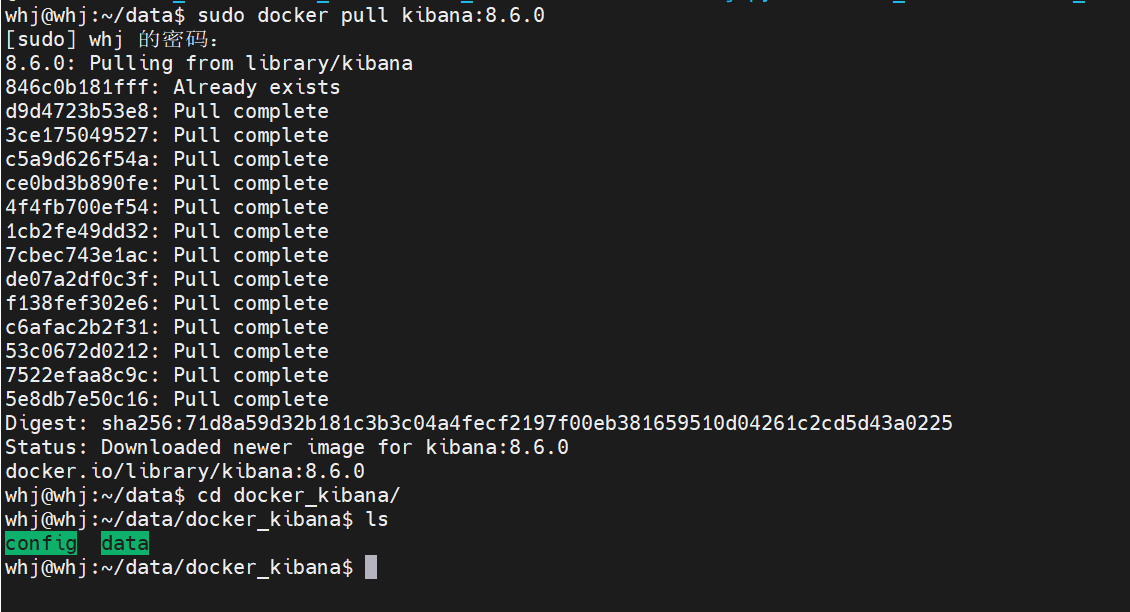
本文档只介绍基于 Docker 安装的过程。
# 1. 拉取镜像
sudo docker pull kibana:8.6.0 # 版本号根据自己的情况确定
# 创建挂载的目录
mkdir /home/whj/data/docker_kibana/data
mkdir /home/whj/data/docker_kibana/cofig
chmod 777 /home/whj/data/docker_kibana/data
chmod 777 /home/whj/data/docker_kibana/config
创建 Kibana 容器
# 使用 docker run 命令创建容器; IP 地址可以改为 es 进行域名的映射, 也可以设置成IP 的形式
sudo docker run -d --name=kibana --network es-net -p 5601:5601 --privileged -e ELASTICSEARCH_HOSTS=http://192.168.177.129:9200 kibana:8.6.0

测试 Kibnan 启动情况
# 在浏览器中输入地址
http://192.168.177.129
1.4 安装 IK 分词器
分词器主要是用来处理中文的情况,需要进行处理,后面进行详细的介绍;
注意:安装 IK 分词器的版本,必须和 Elasticsearch 的版本一致,上文安装的是 Elasticsearch 8.6.0 的版本,IK 分词器也是这个版本。
# 进入容器内部执行改命令
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.6.0/elasticsearch-analysis-ik-8.6.0.zip
# 上述命令失效可执行此语句尝试
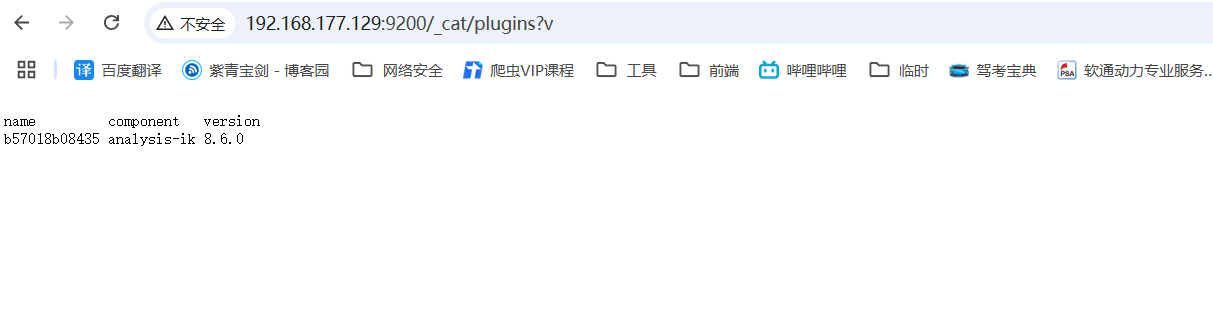
bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/8.6.0
# 验证是否安装成功,在浏览器输入如下地址
http://192.168.177.129:9200/_cat/plugins?v
2. ES 基本概念
补充:数据库与 Elasticsearch 的关系类比
| 关系数据库(RDBMS) | Elasticsearch |
|---|---|
| 数据库 - DataBase | 索引 - Index |
| 表 - Table | 类型 - Type, 已废弃 现用 _doc |
| 行 - Row | 文档 - Document |
| 列- Column | 字段 - Field |
| 表结构 - Schema | 映射 - Mapping |
| SQL 查询语言 | DSL 查询语言 |
2.1 存储形式
Elasticsearch 是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息,文档数据会被序列化为 json 格式之后存在在 ES 中。

索引:同类型文档的集合,类似与数据库的表。
- 类型,一个索引中可以定义一种或者多种类型。
文档:一条数据就是一个文档,类似与 MySQL 中的一条记录,es 中是 json 格式的。
字段:json 文档中的字段。
映射:索引中文档的约束,比如字段的名称类型。
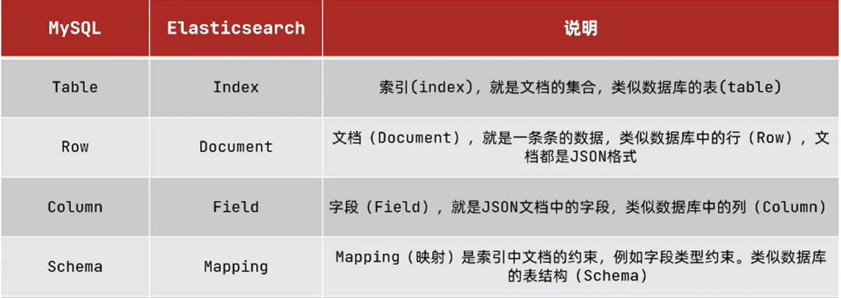
mysql 负责安全可靠的存储原始数据,以及数据之间的关系,Elasticsearch 负责进行数据搜素。
-
其他常见概念
-
接近实时NRT,Elasticsearch 是一个接近实时搜索平台,这意味着,从索引一个文档知道这个文档被搜索到有一个轻微延迟(通常是1秒内);
-
集群,一个集群是有一个或者多个节点组织在一起,他们共同持有整个的数据,并一起提供索引和搜索功能。一个集群是由一个唯一的名字标识,这个名字默认就是 Elasticsearch。这个名字是重要的,因为一个节点只能通过某个集群的名字,来加入这个集群。
-
节点,一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的搜索和索引功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
-
分片和复制
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据 1TB 的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个索引可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:
- 允许你水平分割扩展你的容量。
- 允许你在分片之上进行分布式并行的操作,进而提高性能与吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
-
2.2 正向索引和倒排索引
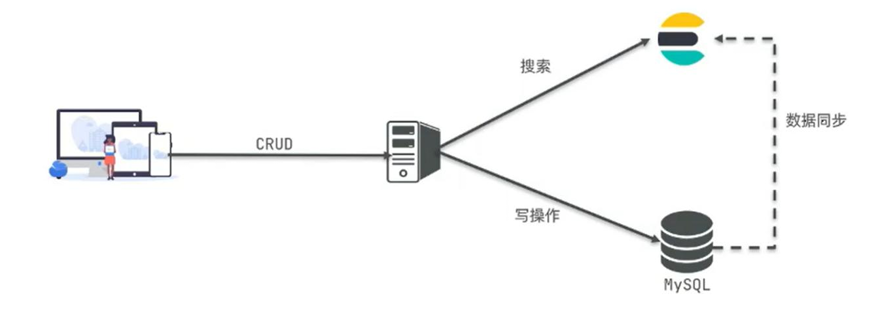
mysql 采用正向索引,即基于文档 id 创建索引,查询词条的时候必须先找到文档,而后判断是否包含搜索的内容。
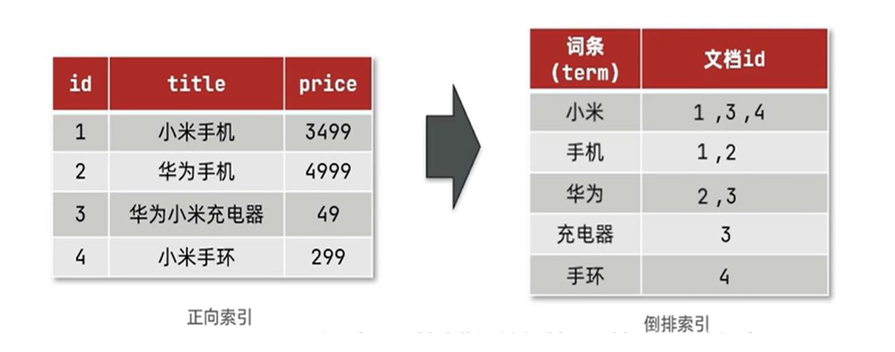
- 档(document):每条数据就是一个文档。
- 词条(term):文档按照语义分成的词语。
Elasticsearch 采用倒排索引,从关键词的角度来构建索引,记录了每个关键词出现在哪些文档中。
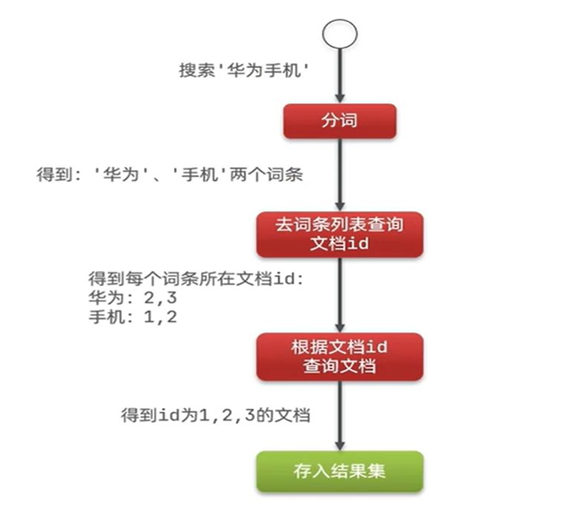
- 简单来说,正向索引就是一本书的目录,按照章节书序,列出每个章节(文档)出现的重要词汇(关键词)。
- 倒排索引,可以把他想象成一个词汇表,每个词汇后面跟着包含这个词汇的文档列表。
3. Elasticsearch 操作
实际开发中,主要有三种方式可以作为 Elasticsearch 服务端的客户端:
-
第一种,elasticsearch-head 插件
Elasticsearch-head已停止维护多年,官方建议使用Kibana DevTools或OpenSearch Dashboard作为替代方案。使用的时候需要 Elasticsearch < 7.x 版本,此处不做过多的阐述;
-
第二种,elasticsearch 提供的 Restful 接口直接访问
-
第三种,elasticsearch 提供的 API 接口进行访问
3.1 Postman 进行操作
3.1.1 接口语法
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'
参数解释:
| 参数 | 解释 |
|---|---|
VERB |
适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
PROTOCOL |
http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
HOST |
Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
PORT |
运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
PATH |
API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
QUERY_STRING |
任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
BODY |
一个 JSON 格式的请求体 (如果请求需要的话) |
CRUD 简单描述
| 方式 | 功能 |
|---|---|
| PUT | 创建索引库,PUT/索引库名 |
| GET | 查询索引库,GET/索引库名 |
| DELETE | 删除索引库,DELETE/索引库名 |
| PUT(修改映射字段) | 修改索引库,PUT /索引库名/_mapping |
3.1.2 创建索引和映射
索引库就相当数据库表,Elasticsearch 提供了简单的创建索引的方法,只需要发送一个 Http 请求即可。
# 语法
# 请求方式:PUT
# 请求路径:/索引库名, 可以自定义
# 请求参数:mapping 映射
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
自定义设置创建索引,可以再创建索引时自定义分片,副本和其他设置。
// 语法 PUT /my_index, 这个命令将在 Elasticsearch 中创建一个名为 my_index 的索引,使用默认的设置和映射。
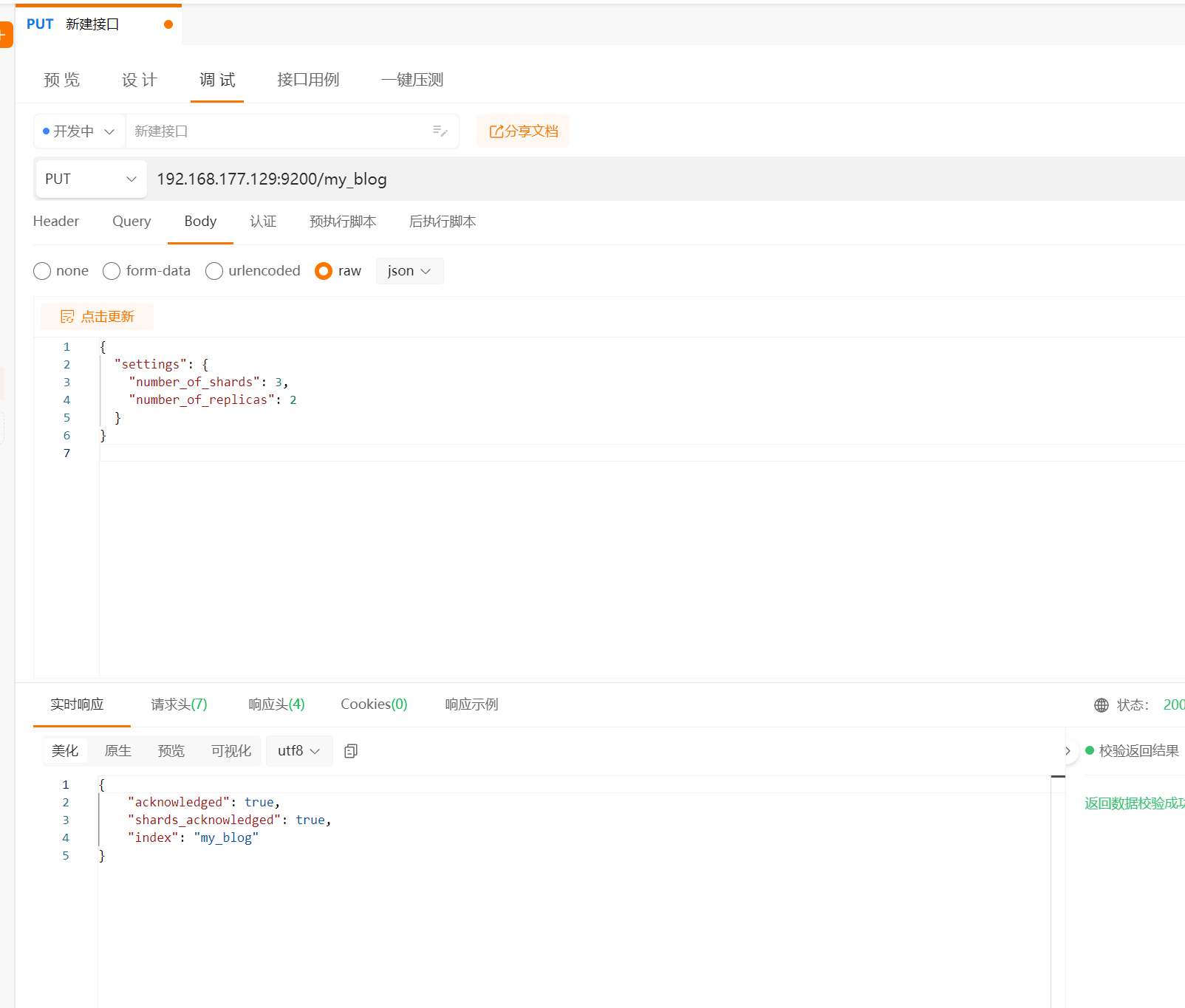
// put 192.168.177.129:9200/my_blog
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
// 这将创建一个名为 my_index 的索引,包含 3 个主分片和 2 个副本。
创建索引并设置映射,映射定义了索引字段的类型及其属性,可以再创建索引时一起定义。
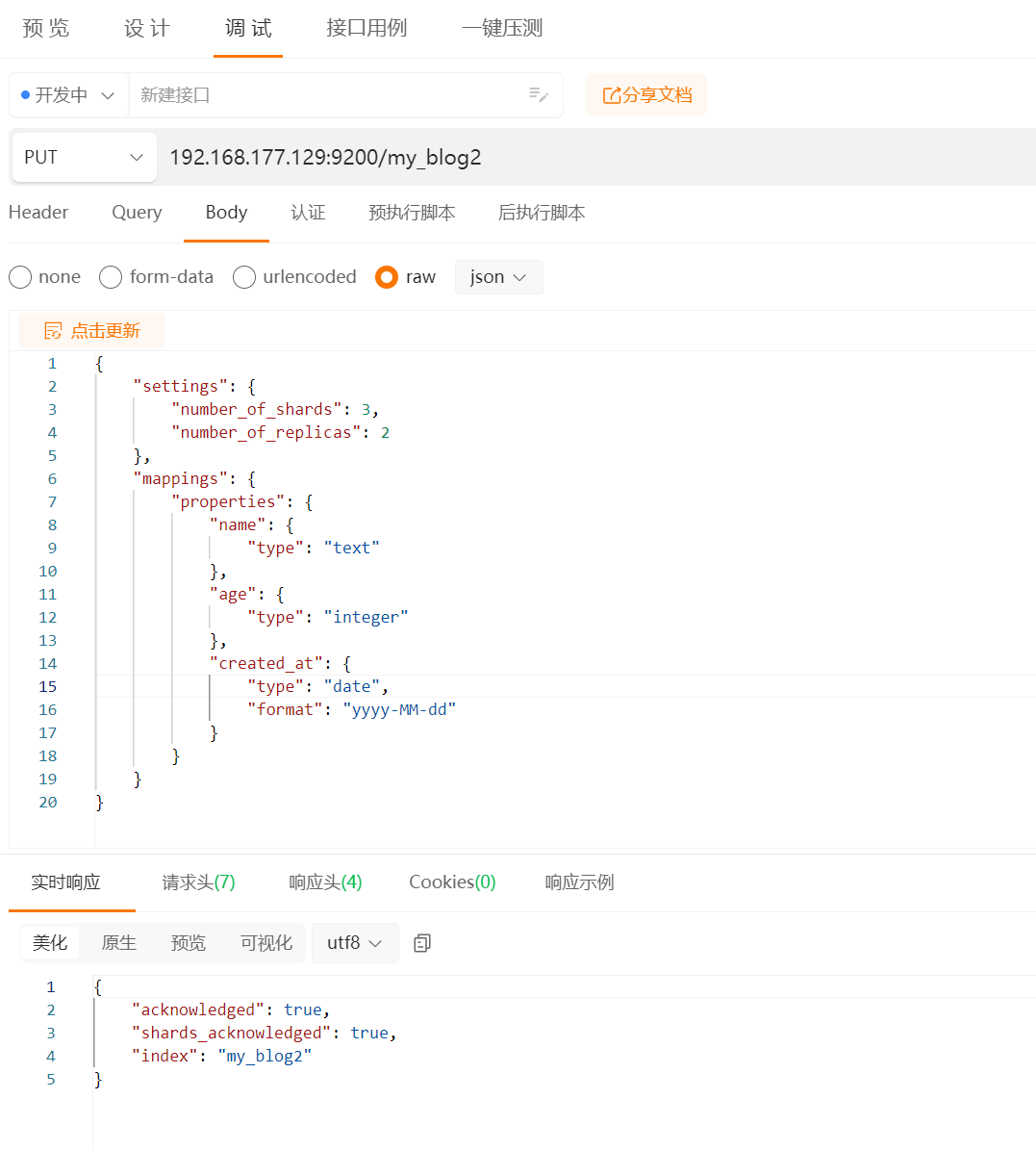
// 完整示例
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
}
// 这个命令创建了一个索引,并定义了三个字段:name(文本类型)、age(整数类型)和 created_at(日期类型)。
索引模板
索引模板允许你为符合特定模式的索引设置默认配置和映射,当索引名称符合模板定义的模式时,会自动应用模板中的设置和映射。
PUT /_template/my_template
{
"index_patterns": ["my_index_*"],
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
// 这个模板将应用于所有以 my_index_ 开头的索引,并自动设置其分片数量和映射。
当创建符合模板的索引的时候,模板会自动应用:
PUT /my_index_2025
这个命令将创建一个名为 my_index_2024 的索引,并应用 my_template 中定义的设置和映射。
Demo :
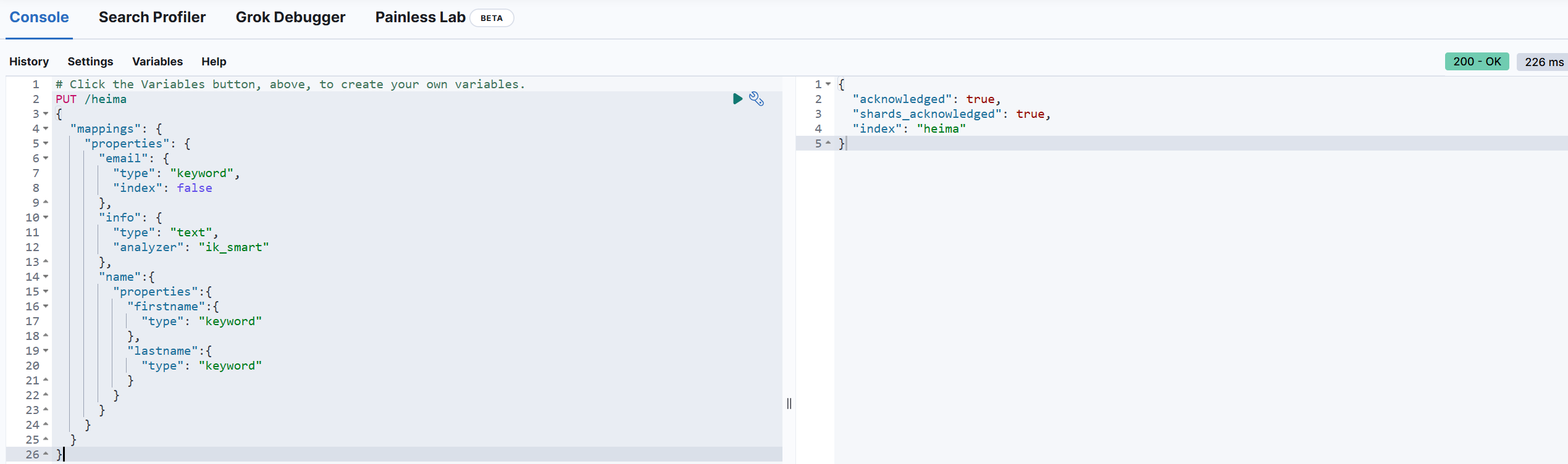
# Click the Variables button, above, to create your own variables.
PUT /heima
{
"mappings": {
"properties": {
"email": {
"type": "keyword",
"index": false
},
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"name":{
"properties":{
"firstname":{
"type": "keyword"
},
"lastname":{
"type": "keyword"
}
}
}
}
}
}
3.1.3 创建映射
Mapping 是对索引库中文档的约束,常见的 Mapping 属性包括以下几点:
-
type: 字段数据类型,常见的简单的类型有:
-
字符串: text(可分词的文本),keyword(精确值,例如,品牌、国家、IP 地址)
keyword 类型只能整体搜索不支持搜索部分内容
-
数值:long、integer、short、byte、double、float
-
布尔值:boolean
-
日期:date
-
对象:object
-
-
index:是否创建索引,默认为 true
-
analyzer:使用那种分词器
-
properties:该字段的子字段
-
示例:
{ "age": 21, "weight": 52.1, "isMarried": false, "info": "真相只有一个!", "email": "zy@itcast.cn", "score": [99.1, 99.5, 98.9], "name": { "firstName": "柯", "lastName": "南" } }- age:类型为 integer;参与搜索,因此需要 index 为 true;无需分词器;
- weight:类型为 float;参与搜索,因此需要 index 为 true;无需分词器;
- isMarried:类型为 boolean;参与搜索,因此需要 index 为 true;无需分词器;
- info:类型为字符串,需要分词,因此是 text;参与搜索,因此需要 index 为 true;分词器可以用 ik_smart;
- email:类型为字符串,但是不需要分词,因此是 keyword;不参与搜索,因此需要 index 为 false;无需分词器;
- score:虽然是数组,但是我们只看元素的类型,类型为 float;参与搜索,因此需要 index 为 true;无需分词器;
- name:类型为 object , 需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
我们可以再创建索引的时候设置 mapping,也可以先创建索引然后再设置 mapping。
在上一个步骤不设置 mapping 信息,直接使用 put 方法创建一个索引,然后设置 mapping 信息
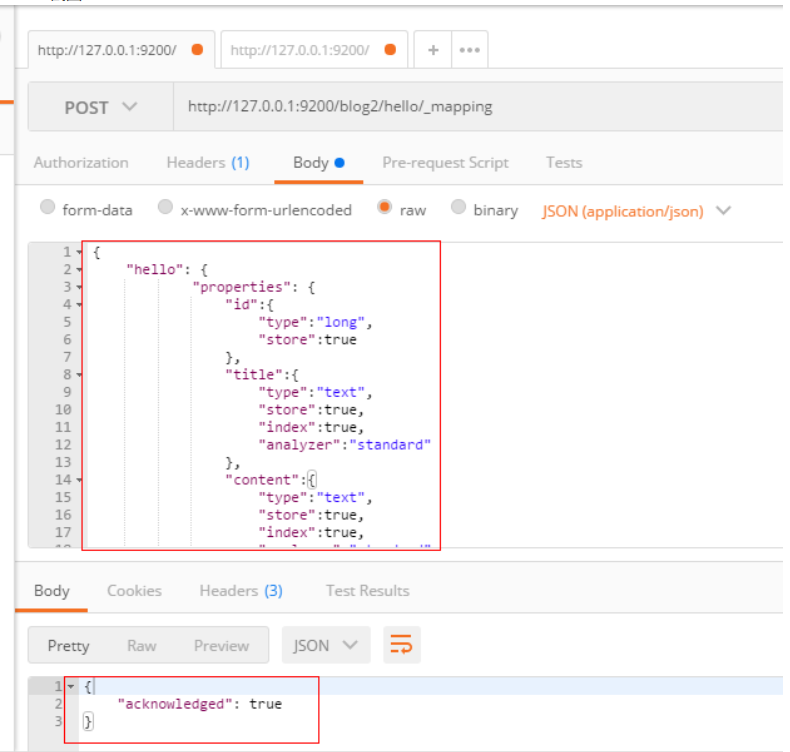
# POST
POST http://192.168.220.110:9200/blog2/hello/_mapping
# 请求体
{
"hello": {
"properties": {
"id":{
"type":"long",
"store":true
},
"title":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
},
"content":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
}
}
}
}
PostMan截图
3.1.4 查询索引库
- 请求方式:GET
- 请求路径:/索引库名
- 请求方式:无
格式:
GET /索引库名
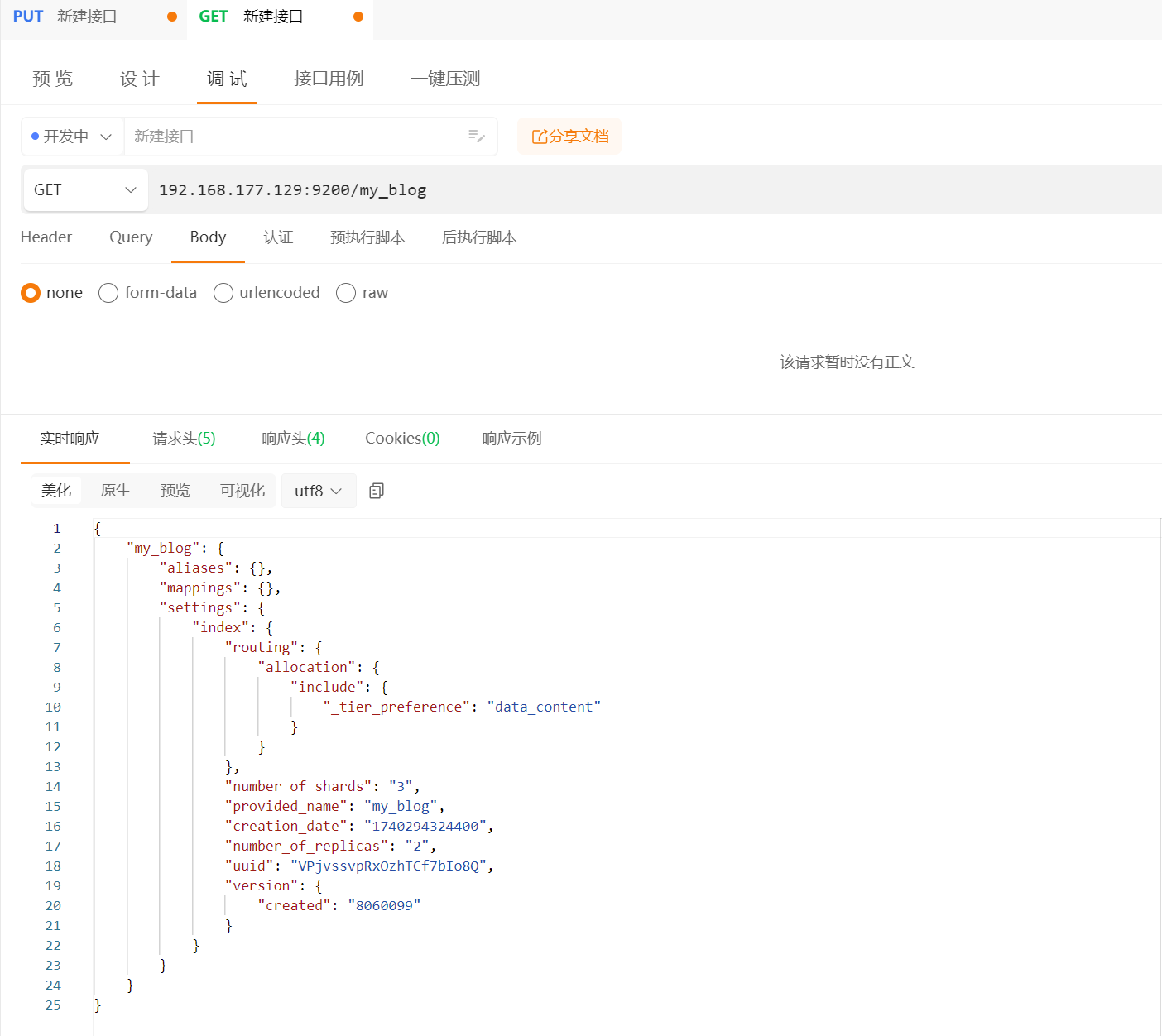
示例:
192.168.177.129:9200/my_blog
3.1.5 修改索引库
这里的修改是只能增加新的字段到 mapping 中
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,因此索引库一旦创建,无法修改 mapping。虽然无法修改 mapping 中的已有字段,但是却允许添加新的字段到 mapping 中,因为不会对倒排索引产生影响。
语法说明:
PUT /索引库名/_mapping
{
"properties":
"新字段名": {
"type": "integer"
}
}
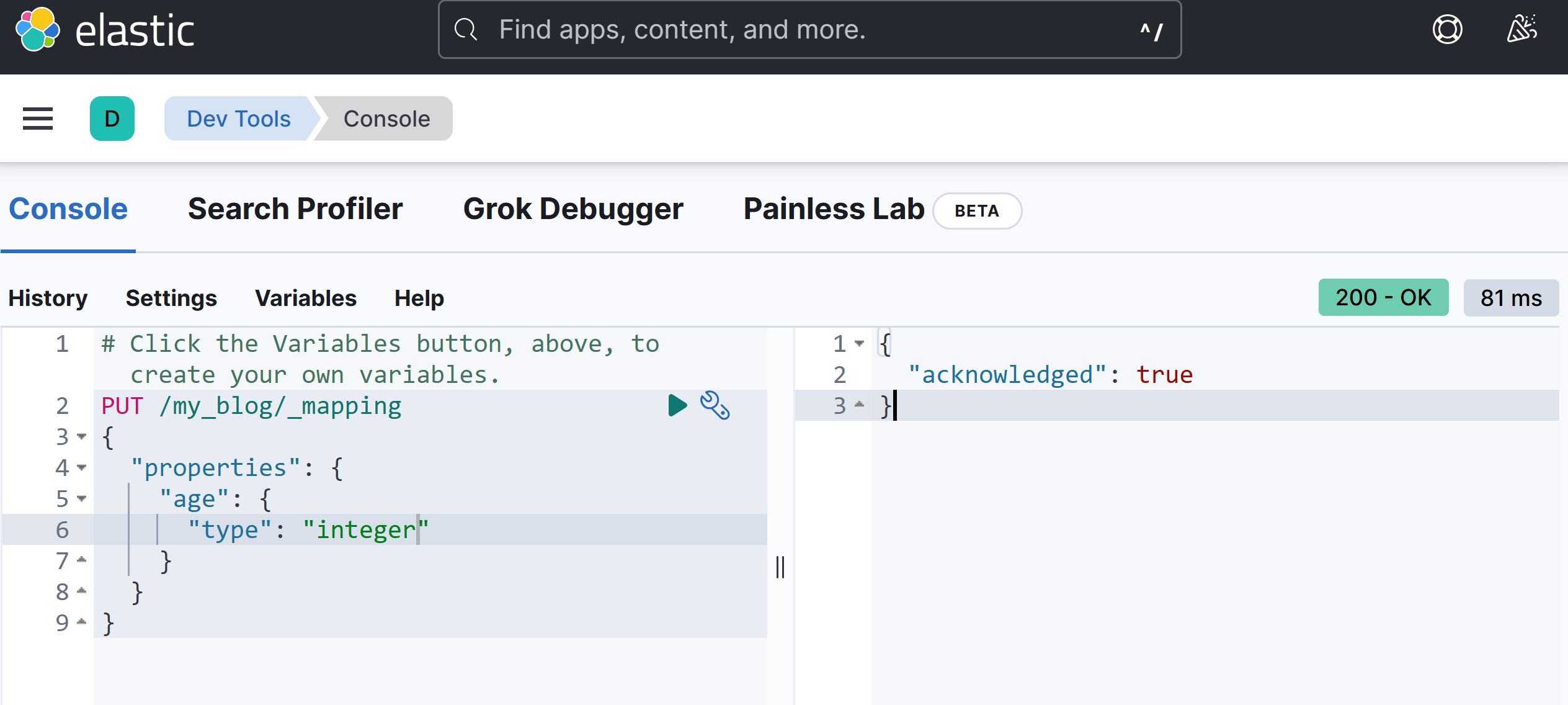
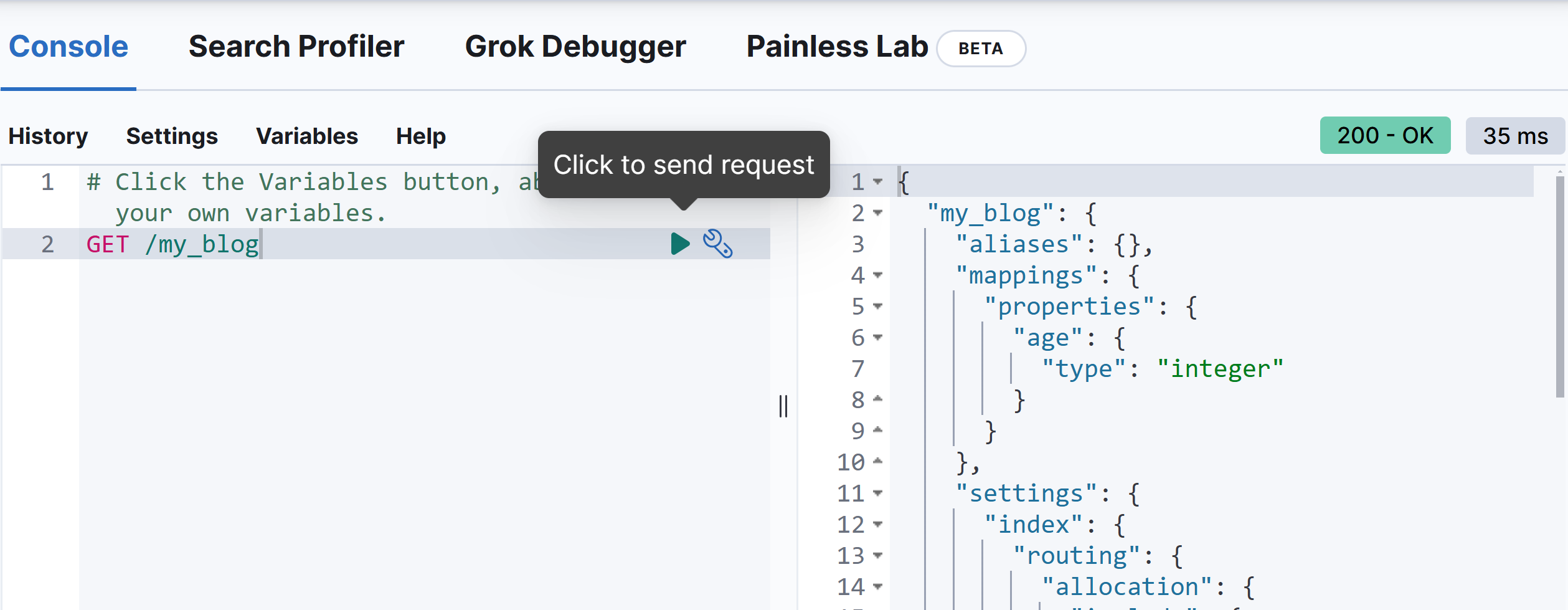
在 kibana 中使用 DSL 的语言进行修改
PUT /my_blog/_mapping
{
"properties": {
"age": {
"type": "integer"
}
}
}
3.1.6 删除索引库
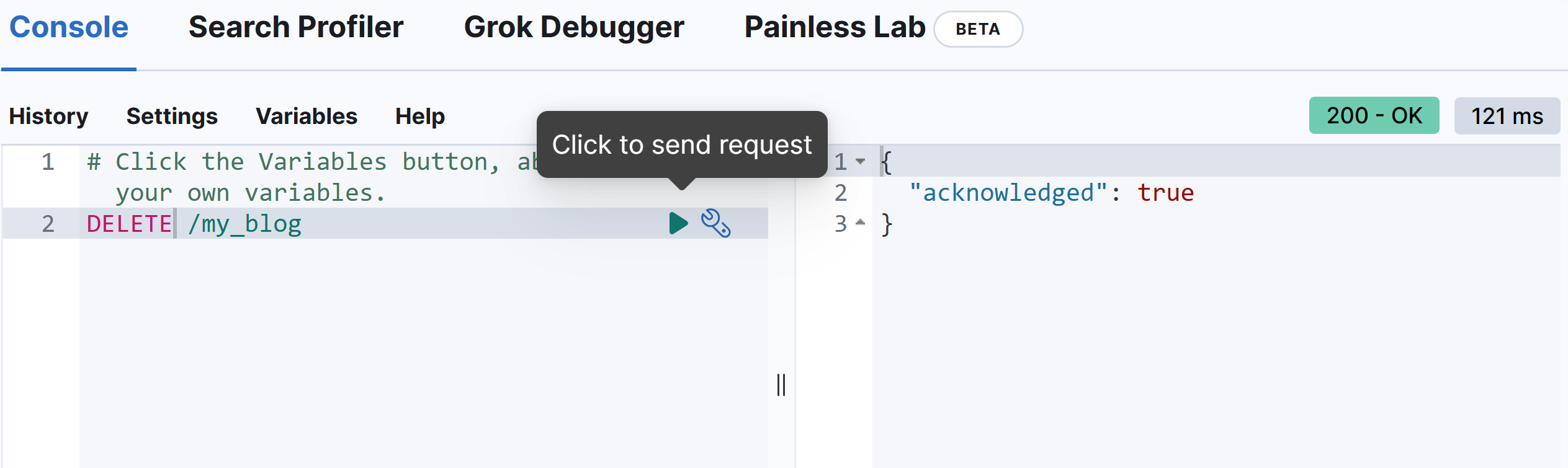
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
格式
DELETE /索引库名
# 在 kibana 中进行测试
3.2 文档操作
文档的操作主要有
-
创建文档
POST /索引库名/_doc/文档id -
查询文档
GET /索引库名/_doc/文档id -
删除文档
DELETE /索引库名/_doc/文档id -
修改文档
全量修改 PUT /索引库名/_doc/文档id 增量修改 POST /索引库名/_doc/文档id
3.2.1 创建文档
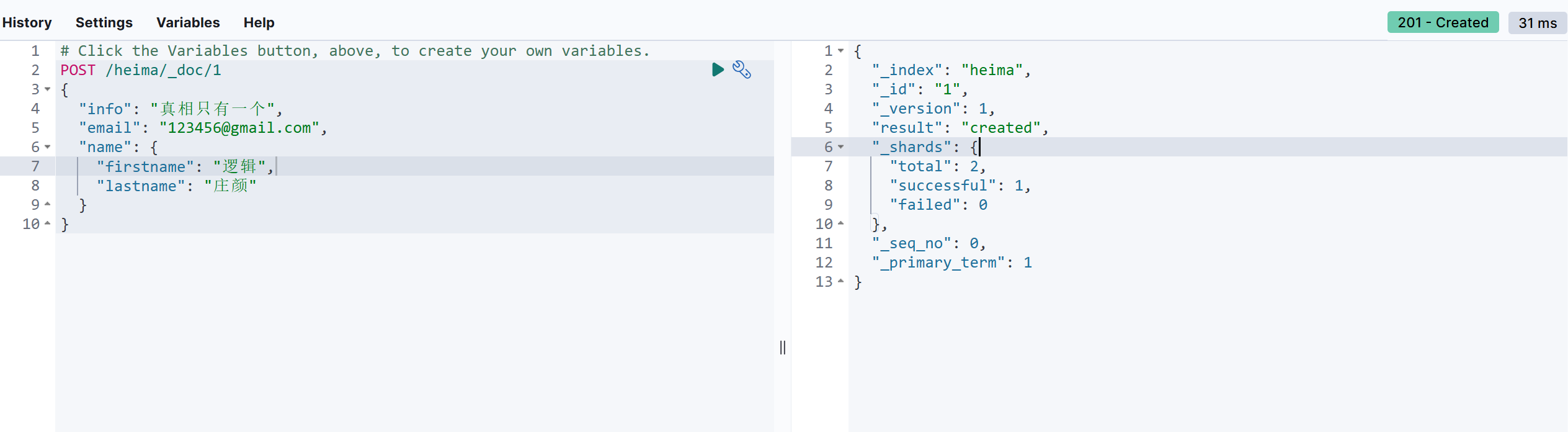
POST /heima/_doc/1
{
"info": "真相只有一个",
"email": "123456@gmail.com",
"name": {
"firstname": "逻辑",
"lastname": "庄颜"
}
}
创建文档的时候使用 POST 的方式进行处理;
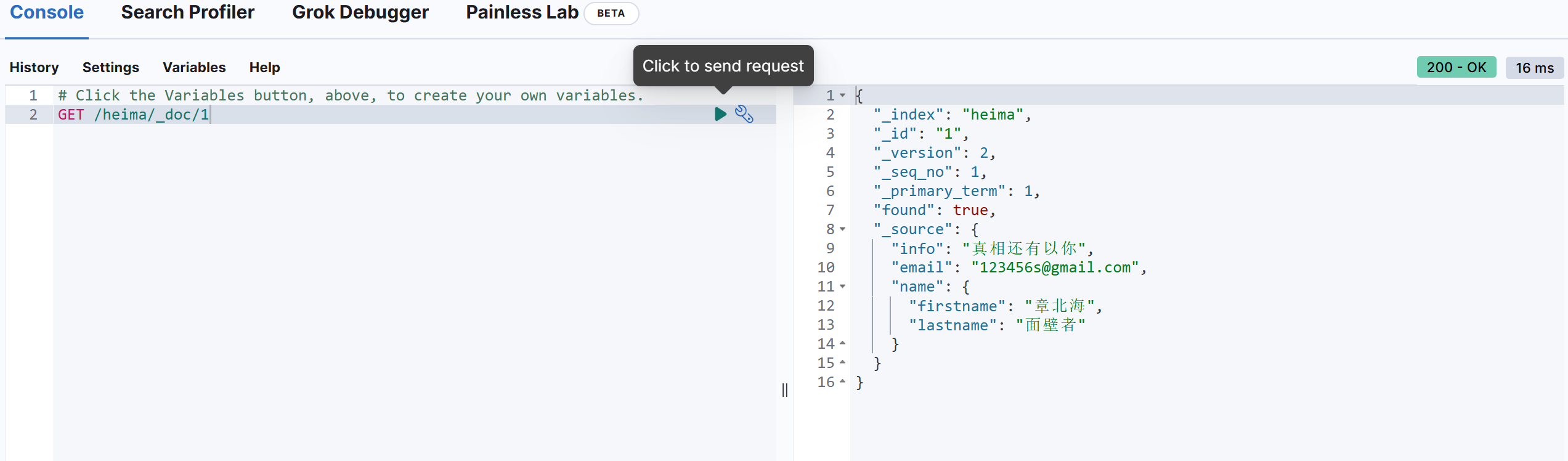
3.2.2 查询文档
根据 rest 风格,新增是 post,查询应该是 get, 不过查询一般都需要条件,这里我们把文档 id 带上。
语法:
# 单个查询
GET /索引库名称/_doc/{id}
# 批量查询
GET /索引库名称/_search
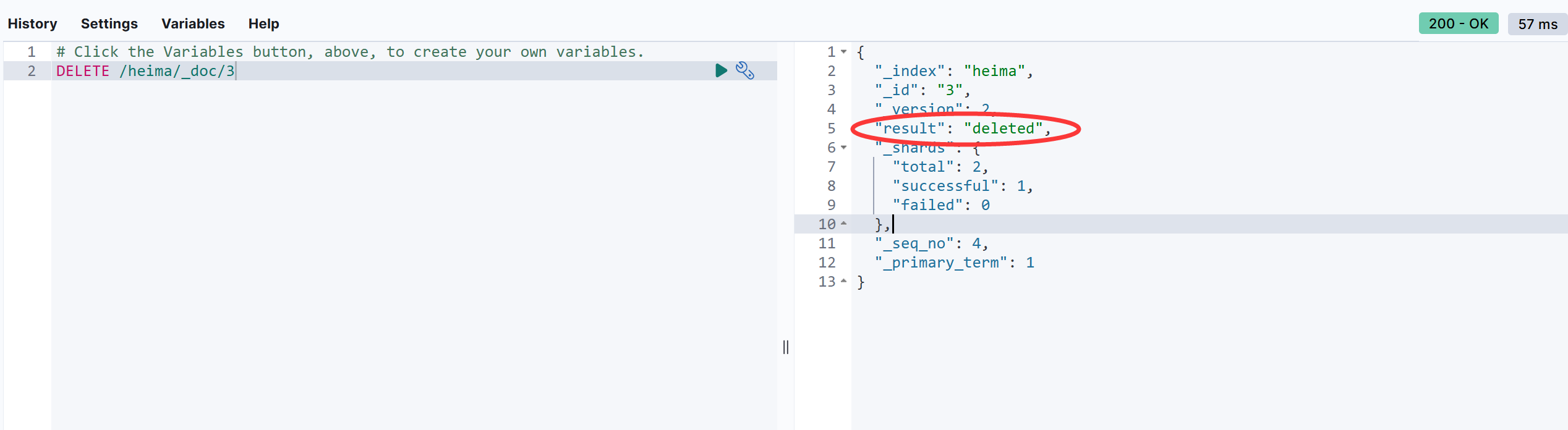
3.3.3 删除文档
使用 DELETE 请求删除文档,根据 id 进行删除;
语法:
DELETE /索引库名/_doc/id值
示例:
DELETE /heima/_doc/3
3.3.4 修改文档
-
修改有两种方式:
-
全量修改:直接覆盖原来的文档
-
增量修改:修改文档中的部分字段
-
全量修改:
全量修改是覆盖原来的文档,其本质是:
- 根据指定的 id 删除文档
- 新增一个相同 id 的文档
注意:如果根据 id 删除时,id 不存在,第二步的新增也会执行,也就变成新增的操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
示例:
copyPUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
增量修改:
增量修改是只修改指定 id 匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
示例:
POST /heima/_doc/2
{
"doc": {
"email": "987654321@qq.com"
}
}
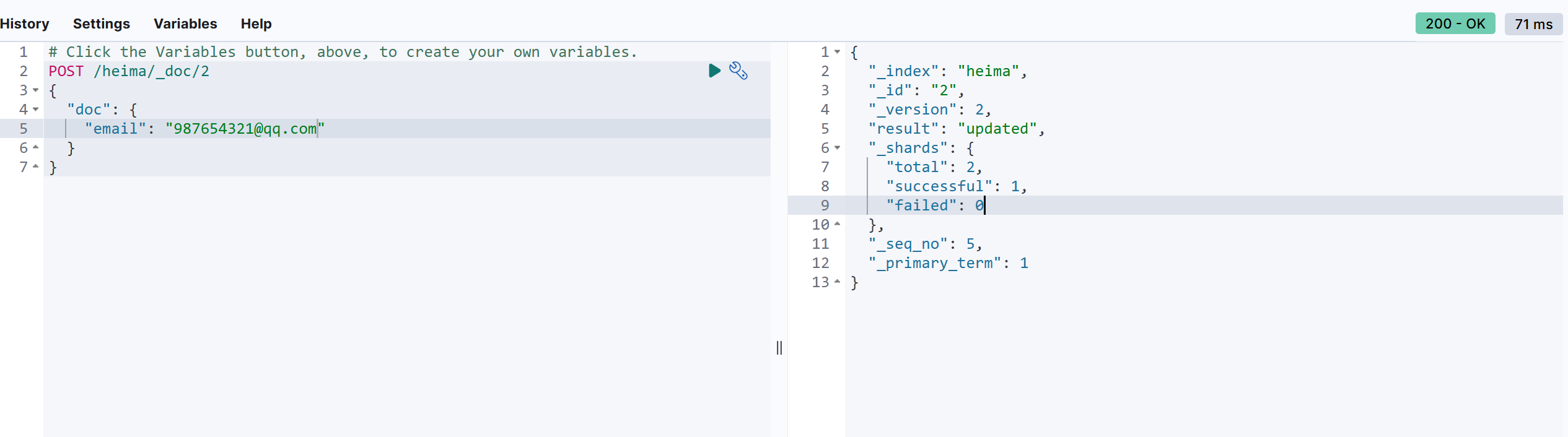
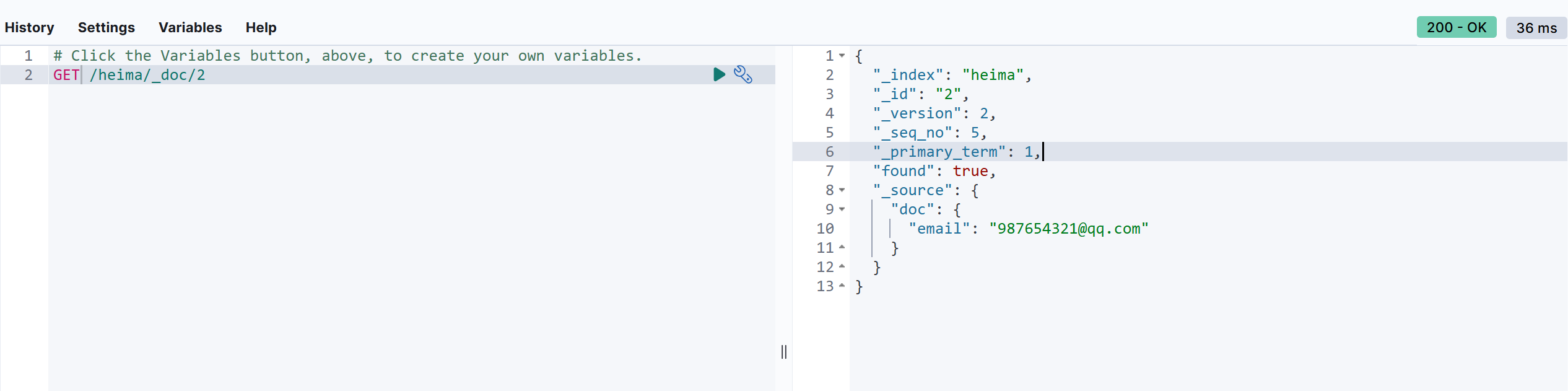
单独修改的时候的结果会在doc中显示。
继续努力,终成大器!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号