
pandas 常见函数的使用
Pandas 的使用
介绍:pandas 是 python 语言的的一个关于数据分析的扩展库;pandas 可以对各种数据进行操作, pandas 依赖于 numpy ,在常规的数据分析中,pandas 的使用范围是最宽广的;
参考文章:https://www.runoob.com/pandas/pandas-tutorial.html
原则:使用pandas处理数据的时候,尽量不要使用for循环去做操作,这样会使得 pandas 失去意义;
1.安装与导入
pip install pandas
导入
import pandas as pd
2.pandas 数据结构
pandas 的数据结构主要分为Series和DataFrame两种数据结构;
2.1 Series 数据结构
v = pd.Series([1,2,3,4,5,6]) # 构建结构
sv = pd.Series([1,2,3], index=['x','y','z'])
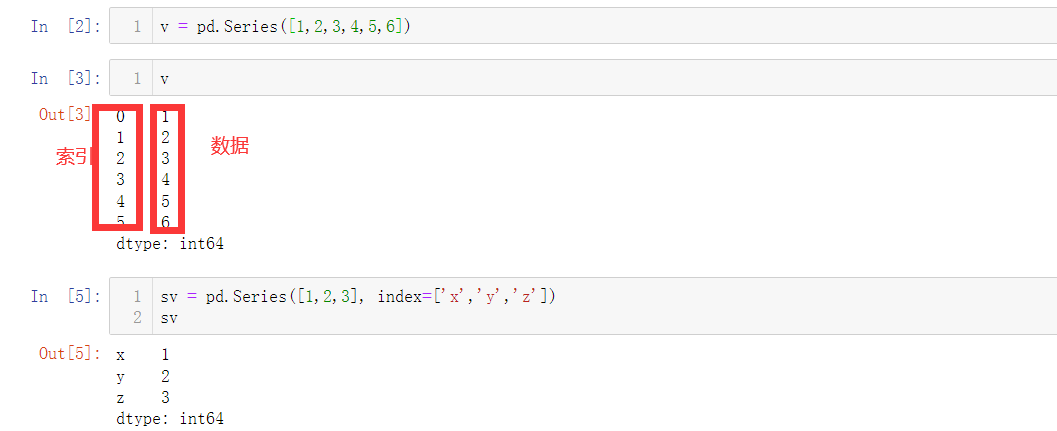
使用字典直接构建数据
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
myvar
2.2 DataFrame 数据结构
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
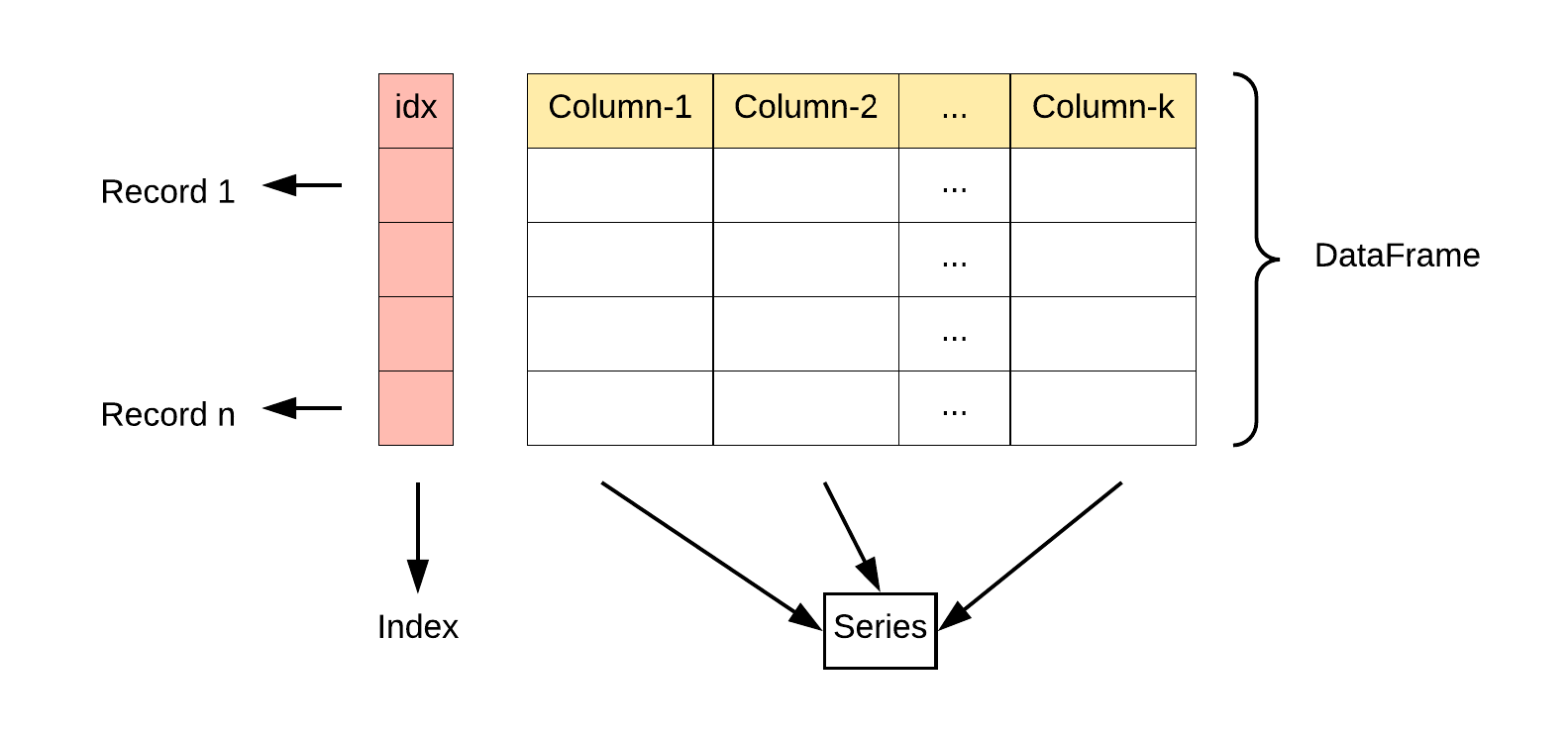
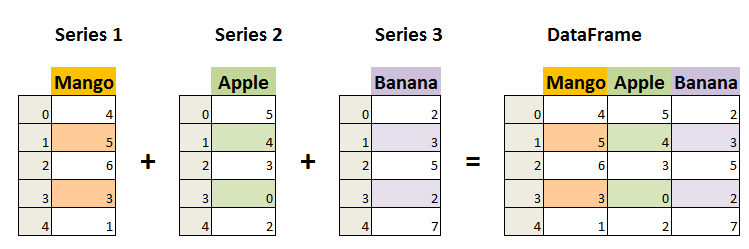
这种数据结构是我们最常用的数据结构的信息;
# 转换列表为数据对象
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float) # 构建对象;
df
转换字典
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])
>>>
calories 420
duration 50
Name: 0, dtype: int64
calories 380
duration 40
Name: 1, dtype: int64
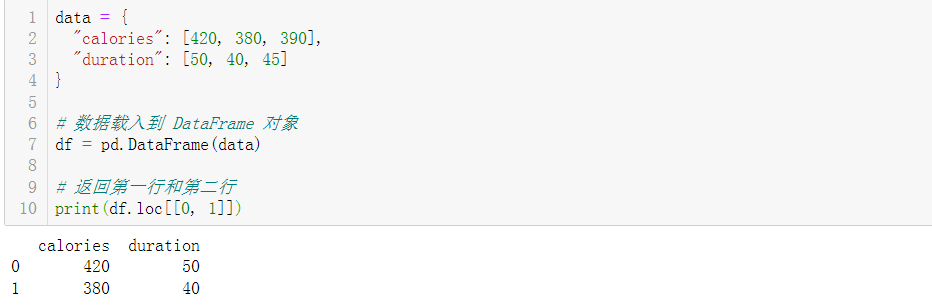
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])
3.Pandas的数据导入
数据导入主要看数据的来源与数据的形式,最常见的数据的形式是json,csv,sql,mongo,txt;
3.1 csv 数据的导入
# 读取数据消息
v = pd.read_csv('../data/tag.csv')
print(v.head()) # head(10)显示头部数据信息;
print(v.tail()) # tail(10) 显示末尾的数据信息;
v = pd.read_csv('../data/tag.csv', index_col=0) # 读取数据不显示行索引;
pandas 的导入方式如上,还有原生的python操作文件的方式;
补充:.txt文件的使用是表格的时候,可以使用read_csv方法,将分隔符设置成为文件中的分隔符就可以;当.txt文件中是一段文本的时候,可以直接使用 python 的文件处理;
3.2 json 数据的导入
v = pd.read_json('s.json')
print(v.head())
3.3 sql 数据读取
import pandas as pd
from utils.db import db
# 已经封装好的模块获取数据库连接池中的连接;
conn = db.get_conn_cursor()[0]
sql_str = "select * from blogs"
v = pd.read_sql(sql_str, con=conn)
print(v.head())
说明: SQL 语句本身具备数据筛选与过滤的作用,如果可以在数据读取的时候直接使用复杂的 SQL 过滤掉一部分的数据,可以为数据预处理的部分省去很多的事情;
3.4 读取Mongo
pandas 读取 mongodb 的数据的时候直接,使用 pymongo 从非关系型数据库中读取数据,将数据转换成列表,在使用
import pandas as pd
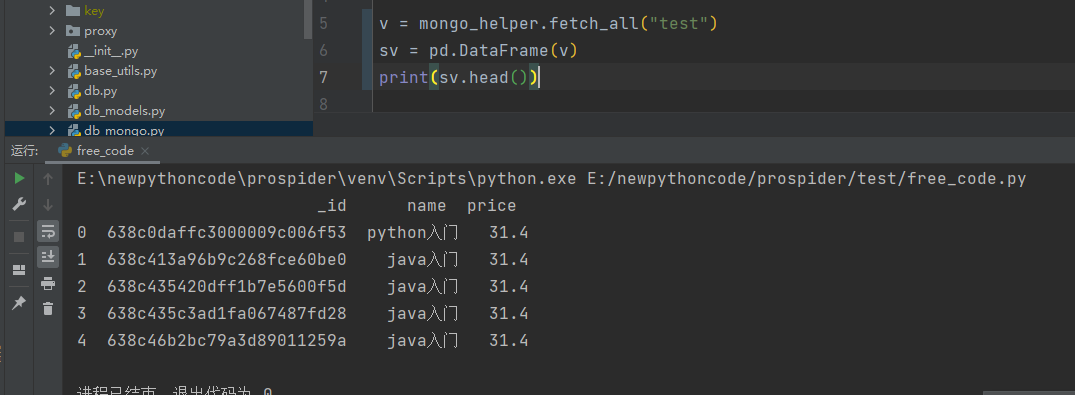
from utils.db_mongo import mongo_helper
v = mongo_helper.fetch_all("test") # 调用已经封装好的模块将信息成功,返回列表
sv = pd.DataFrame(v) # 加载成为 pandas 对象;
print(sv.head())
3.5 数据信息的统计
本部分属于额外补充,因为导入数据完成之后,会直接将数据信息设置,进行一下简单的统计;
v = mongo_helper.fetch_all("test")
sv = pd.DataFrame(v)
print(sv.shape) # 获取数据的行数和列数;
print(sv.info()) # 显示各列的数据类型以及是否包含空值;
4.数据清洗
数据清洗,是数据预处理中的一个步骤;pandas 数据处理主要包含缺失值的处理和异常值处理
4.1 空值的清洗
缺失值的处理:对待缺失值的处理一般有两种方法,分别是插值法和删除法操作的类型也主要有两种,一种是有具体数值的,另一种是类别的离散值;
4.1.1 空值的删除
相关的函数
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为
'any'如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置how='all'一行(或列)都是 NA 才去掉这整行。 - thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
检查单元格是否为空isnull(),判断单元格是否为空;
4.1.2 空值的填充
使用较少,因为当数据量较大的时候删除一些空值数据并不影响具体的操作,当数据量较少的时候填充是非常不错的选择;
对于类别值或离散值,,我们将“NaN”视为一个类别。比如name列有"Tom"和“NaN”两个类别,pandas会自动将一列转化为两列,并且两列分别为“name_Tom”和"name_NaN"。并且转化为的两列中,每一行等于该列对应的类别的取1,否则取0。比如name_Tom列,只有第一行为1,其余行均为0,这里有点类似onehot编码。
这里用到get_dummies()函数,类似onehot编码。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
按照上一行(下一行)进行数据的填充,参考文章:https://blog.csdn.net/weixin_46089741/article/details/122305108
# 上一行: 经常用在有分组信息的表里面
data = data.fillna(method='ffill', inplace=True)
4.2 重复值的处理
判断重复行
# 重复值为 True
DataFrame.duplicated()
删除重复行
# 重复值的删除
DataFrame.drop_duplicates()
默认是,当这一行与前面某一行所有元素都重复才删除。否则,需要指定判断重复的标志列。默认保留第一行重复值,也可指定保留最后一行;
df.drop_duplicates(['商品名称'], keep='last')
Out[2]:
商品名称 地区 销量
0 李老吉 北京 15
2 康帅傅 广州 28
3 娃啥啥 上海 13
4.3 经验异常值处理
经验指的是行业经验,即要结合具体业务。以气温为例子。放在全球来讲,气温最高也就 50 左右。那么可以简单认为超过 60 的气温数据就是异常。结合上一章讲的数据过滤即可实现。
df
Out[1]:
城市 温度
0 北京 -5
1 上海 5
2 广州 15
3 基加利 75
# 只选择温度小于60的
df[df['温度']<60]
Out[2]:
城市 温度
0 北京 -5
1 上海 5
2 广州 15
5.数据的类型转换与简单计算
dataframe.info() # 查看数据的类型;与值的描述;
dataframe.dtypes # 查看数据类型;
这里不在对数据类型进行介绍;只对常见的数据类型之间的转换进行记录
5.1 读取数据时直接指定数据类型
import pandas as pd
df = pd.read_excel('数据类型转换案例数据.xlsx',
dtype={
'国家':'string',
'向往度':'Int64'
}
)
使用astype()函数
df.受欢迎度.astype('float')
5.2 日期类型的转换
pd.to_datetime(s, unit='ns') # 常见的情况
pd.to_datetime(s, format='%Y%m%d', errors='coerce')
# 时间差类型
pd.to_timedelta转化为时间差类型
In [23]: import numpy as np
In [24]: pd.to_timedelta(np.arange(5), unit='d')
Out[24]: TimedeltaIndex(['0 days', '1 days', '2 days', '3 days', '4 days'], dtype='timedelta64[ns]', freq=None)
In [25]: pd.to_timedelta('1 days 06:05:01.00003')
Out[25]: Timedelta('1 days 06:05:01.000030')
In [26]: pd.to_timedelta(['1 days 06:05:01.00003', '15.5us', 'nan'])
Out[26]: TimedeltaIndex(['1 days 06:05:01.000030', '0 days 00:00:00.000015500', NaT], dtype='timedelta64[ns]', freq=None)
说明:时间字符串,日期和时间是有一个空格的2022-12-31 18.01.02,没有空格是无法转换的;
5.3 智能转换数据类型
convert_dtypes方法可以用来进行比较智能的数据类型转化,请看
6.数据的筛选
数据筛选是读取和预处理之后,
"""参考文章: https://blog.csdn.net/joker_zsl/article/details/119874694
"""
import pandas as pd
df = pd.DataFrame({'key': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'], 'data': [0, 5, 10, 5, 10, 15, 10, 15, 20]})
def print_line():
print("---------------------------------------------------------------------")
# 简单条件筛选; 类似于 SQL 的 where key = 'A'
print(df[df['key'] == 'A'])
"""
key data
0 A 0
3 A 5
6 A 10
"""
print_line()
# 复杂条件筛选, 选出大于均值的数据, 在将取到的值按照指定列进行升序排序;
print(df[df['data'] > df['data'].mean()].sort_values(by='data', ascending=False))
"""
key data
8 C 20
5 C 15
7 B 15
"""
print_line()
"""
loc : 通过索引 index 中取出具体的值;
iloc : 通过行号去数据;
参考文章: https://blog.csdn.net/weixin_44852067/article/details/122301685
"""
print(df.loc[1]) # 取出索引为 1 的数据;
print(df.iloc[0]) # 第 0 行数据;
# 取出 A列所有的行
"""
key B
data 5
Name: 1, dtype: object
key A
data 0
Name: 0, dtype: object
"""
print_line()
print(df.loc[:, ['key', 'data']])
"""
key data
0 A 0
1 B 5
2 C 10
3 A 5
4 B 10
5 C 15
6 A 10
7 B 15
8 C 20
"""
print_line()
# 按照条件提取
print(df.loc[(df['data'] > df['data'].mean()), ['key']])
"""
key
5 C
7 B
8 C
"""
print_line()
# isin 函数使用包含筛选筛选
print(df.loc[df['data'].isin([0, 5, 15]), :])
"""
key data
0 A 0
1 B 5
3 A 5
5 C 15
7 B 15
"""
print_line()
# str.contains 字符串包含查询; 经常用在长字符串中;
print(df.loc[df['key'].str.contains('A'), :])
"""
key data
0 A 0
3 A 5
6 A 10
"""
print_line()
# where, 不满足条件的被赋值(默认赋空值)
cond = df['key'] == 'A'
print(df['key'].where(cond, inplace=False)) # 赋值空
print(df['key'].where(cond, other="Hello", inplace=False)) # 赋值 hello
"""
0 A
1 NaN
2 NaN
3 A
4 NaN
5 NaN
6 A
7 NaN
8 NaN
Name: key, dtype: object
0 A
1 Hello
2 Hello
3 A
4 Hello
5 Hello
6 A
7 Hello
8 Hello
Name: key, dtype: object
"""
print_line()
# query 查找
print(df.query('data > 10')) # 与最开使得 df[df['data'] > 10] 相同
print(df.query('key.str.contains("A") & data > 5'))
# 上面的 query 一般情况下都是可以用原生的函数进行还原;
print(df[(df['key'].str.contains('A')) & (df['data'] > 5)])
"""
key data
5 C 15
7 B 15
8 C 20
key data
6 A 10
key data
6 A 10
"""
print_line()
# filter 过滤
"""
filter是另外一个独特的筛选功能。filter不筛选具体数据,而是筛选特定的行或列。它支持三种筛选方式:
- items:固定列名
- regex:正则表达式
- like:以及模糊查询
axis:控制是行 index 或列 columns 的查询
"""
print(df.filter(items=['key']))
print(df.filter(regex='e', axis=1)) # 查找列
print(df.filter(regex='1', axis=0)) # 查找行
# 模糊匹配
print(df.filter(like='a', axis=1))
"""
key
0 A
1 B
2 C
3 A
4 B
5 C
6 A
7 B
8 C
key
0 A
1 B
2 C
3 A
4 B
5 C
6 A
7 B
8 C
key data
1 B 5
data
0 0
1 5
2 10
3 5
4 10
5 15
6 10
7 15
8 20
"""
print_line()
"""
any方法意思是,如果至少有一个值为True结果便为True,all需要所有值为True结果才为True,比如下面这样。
any和all一般是需要和其它操作配合使用的,比如查看每列的空值情况。
"""
print(df['key'].any())
print(df.isnull()) # 检查是否存在空值,存在返回 True
print(df.isnull().any(axis=0)) #
print(df.isnull().any(axis=1).sum()) # 查看空值的函数
"""
---------------------------------------------------------------------
True
key data
0 False False
1 False False
2 False False
3 False False
4 False False
5 False False
6 False False
7 False False
8 False False
key False
data False
dtype: bool
0
"""
8.数据分析常用函数与功能
pandas 可以完成数据统计分析的基础部分,因此也是必不可少的利器;
8.1 pandas 分组聚合
说明:当数据源是mysql等关系数据库的时候,可以使用group by进行数据的分组聚合,效果依旧很好,pandas 最长用在 csv 等数据集中;
pandas 分组聚合是简单的统计分析的利器,但是其中的函数特别容易混乱,不需要记住每个函数的信息,只需要知道逻辑是分组后的操作,就可以根据查询,或者自定义操作后的函数信息;
参考文章:https://blog.csdn.net/fullbug/article/details/122892358
# 构建数据数据集, 通过简单的数据集进行分析,可以更好的剖析每个函数的功能;
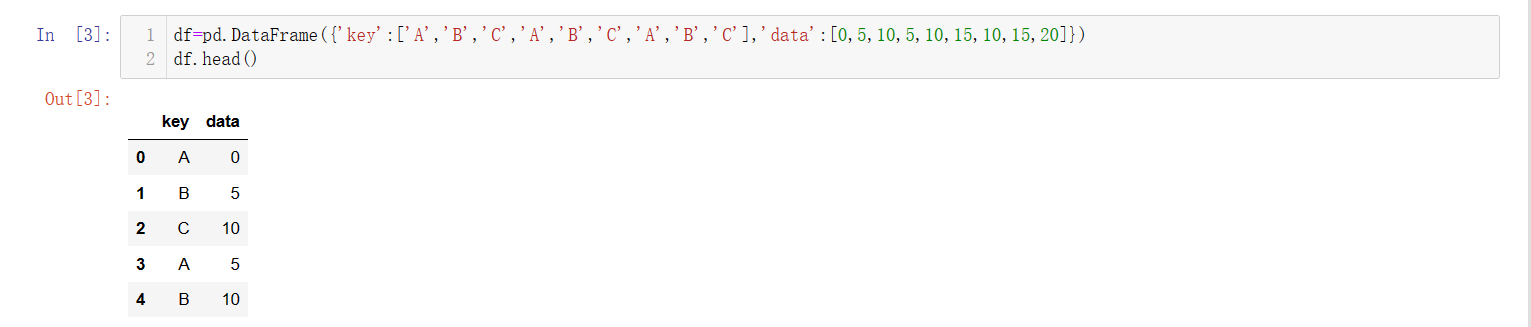
df=pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'],'data':[0,5,10,5,10,15,10,15,20]})
df.head()
8.1.1 数据分组
# 按照 key 进行分组,分组后没一个类别中相当于有一个字表
pd.DataFrame(df.groupby(['key']))
# 查看字表的信息;
pd.DataFrame(df.groupby(['key']))[1][0]


虽然这种方法可以查看到分组后的字表,但是不到万不得已,不要使用这种表嵌套的形式,该种方式不太符合展示与后期的程序处理,可以在中间过程试用一下作为中间数据的处理桥梁,但是步骤依旧繁琐,因此最好减少使用;
8.1.2 数据聚合
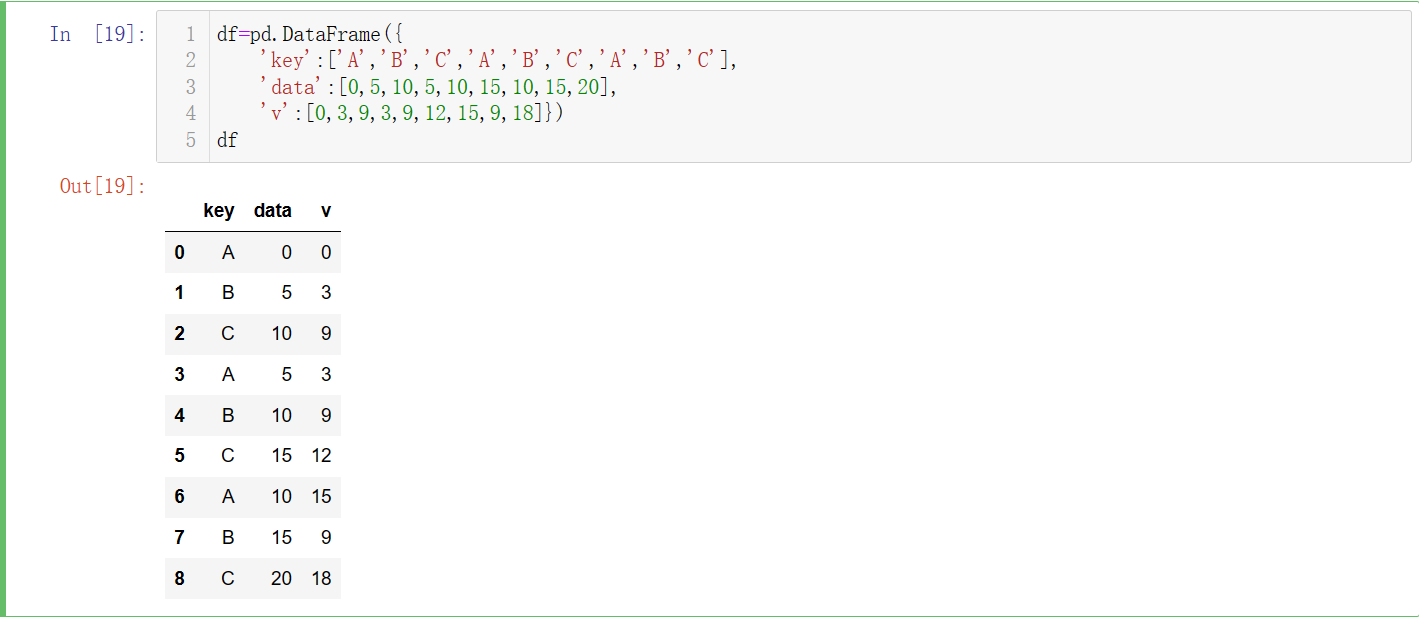
# 此处重新构建数据集,因为实际的数据分析中往往都是多列的数据信息
df=pd.DataFrame({
'key':['A','B','C','A','B','C','A','B','C'],
'data':[0,5,10,5,10,15,10,15,20],
'v':[0,3,9,3,9,12,15,9,18]})
df
分组求和
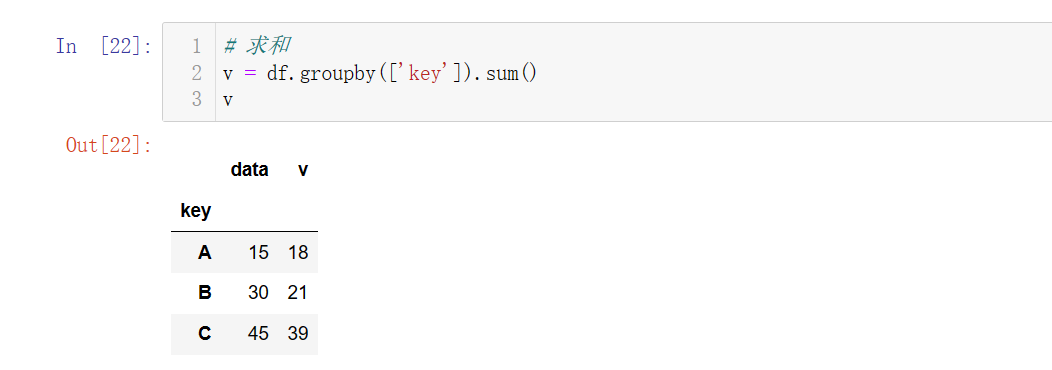
# 求和,使用分组聚合之后,是对数据中得每一列都进行了聚合
v = df.groupby(['key']).sum()
v
# 只对某一列进行求和
sv = df.groupby(['key'])['v'].sum()
sv

# 其他的常见聚合函数
# 每一列求均值,求取单独一列的时候可以像上一步一样进行选取
df.groupby(['key']).mean()
df.groupby(['key']).max()
df.groupby(['key']).min()
其他常见的函数信息
| 函数名 | 描述 |
|---|---|
| count | 分组中非NA值的数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的中位数 |
| std, var | 标准差和方差 |
| min, max | 非NA的最小值,最大值 |
| prod | 非NA值的乘积 |
| first, last | 非NA值的第一个,最后一个 |

更多的分组后的操作
使用自定义的聚合函数
# 求极差函数:
def peak_to_peak(arr: pd.Series):
return arr.max() - arr.min()
# 执行自定义的函数信息;
df.groupby(['key']).agg(peak_to_peak)
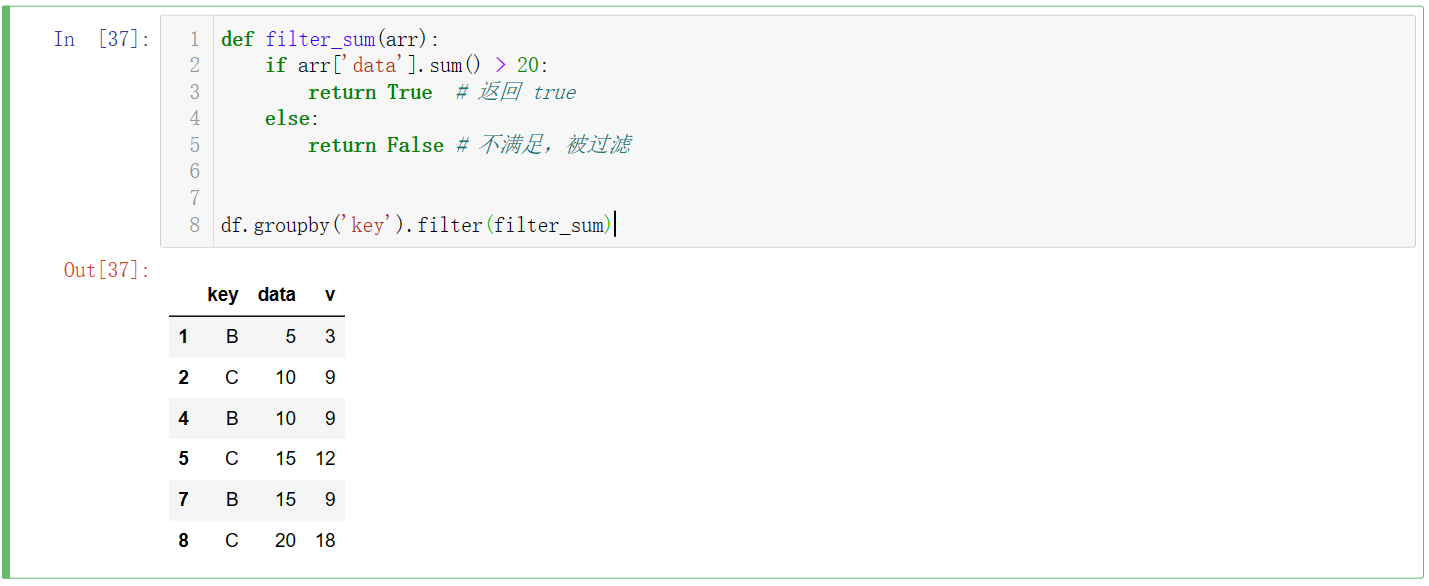
分组后的过滤
def filter_sum(arr):
if arr['data'].sum() > 20:
return True # 返回 true
else:
return False # 不满足,被过滤
df.groupby('key').filter(filter_sum)
8.2 one-hot 编码
import pandas as pd
# 构建数据集
df = pd.DataFrame([
['green', 'A', 2],
['red', 'B', 3],
['blue', 'A', 2],
])
# 重新命名列名
df.columns = ['color', 'class', 'num']
print(df)
# 进行 one-hot 编码
print(pd.get_dummies(df))
8.3 apply() 的使用
参考文章:https://blog.csdn.net/weixin_44852067/article/details/122364306
Pandas 的apply()方法是用来调用一个函数(python method),让自定义的函数对数据进行批处理。Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe、Series、分组对象、各种时间序列等。
# apply(函数), 最常见的是内部传入的是匿名函数信息;
import pandas as pd
import numpy as np
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
print(df)
# pandas 使用 numpy 的函数;
print(df.apply(np.sqrt)) # 求开方后的值
print(df.apply(np.sum, axis=1)) # axis=1 横向,axis=0 纵向;
# 使用匿名函数;
print(df.apply(lambda x: x + 2)) # 每一个值加 2
# 使用自定义的函数
def square(x):
return x ** 2
print(df.apply(square))
"""
A B
0 4 9
1 4 9
2 4 9
A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
0 13
1 13
2 13
dtype: int64
A B
0 6 11
1 6 11
2 6 11
A B
0 16 81
1 16 81
2 16 81
"""
8.4 导出为 python数据类型
# 经常用在使用 python 原生数据中,常见的是 Pyecharts 的可视化操作中;
print(df['A'].tolist())
print(df['A'].to_dict())
8.5 pandas 计算分位数
import pandas as pd
df = pd.DataFrame({'a': [1, 2, 3], 'b': [4, 5, 6], 'c': ['d', 'e', 'f']})
print(df['a'].quantile(0.25))
9.数据的合并与导出
数据的导出主要分为SQL的导出和csv文件的导出;当数据量不是特别巨大的时候 csv 文件是不错的选择,因为SQL导出的时候会将数据之间的相关的关联与约束全部取消掉;
9.1 表连接
表的连接分为横向和纵向两个方向;
9.1.1 横向连接
不到万不得已的情况下不要使用表的拼接;
# 只能实现两张表的合并,按照指定的列进行合并
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.arange(12).reshape(3, 4), columns=['a', 'b', 'c', 'd'])
print(df1)
df2 = pd.DataFrame({'b': [1, 5], 'd': [3, 7], 'a': [0, 4]})
print(df2)
# 横向连接重叠列自动
print("------------------")
print(pd.merge(df1, df2)) # 只会留下数据相同的列;
"""
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
b d a
0 1 3 0
1 5 7 4
------------------
a b c d
0 0 1 2 3
1 4 5 6 7
"""
直接拼接
print(pd.concat([df1, df2], axis=1))
"""
A B C D E A B C D F
0 A0 B0 C0 D0 E0 A4 B4 C4 D4 F4
1 A1 B1 C1 D1 E1 A5 B5 C5 D5 F5
2 A2 B2 C2 D2 E2 A6 B6 C6 D6 F6
3 A3 B3 C3 D3 E3 A7 B7 C7 D7 F7
"""
concat 的函数模式较多不做过多的描述;
9.1.2 纵向连接
import pandas as pd
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3'],
'E': ['E0', 'E1', 'E2', 'E3']
})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7'],
'F': ['F4', 'F5', 'F6', 'F7']
})
# 默认的concat,参数为axis=0、join=outer、ignore_index=False
print(pd.concat([df1, df2]))
"""
A B C D E F
0 A0 B0 C0 D0 E0 NaN
1 A1 B1 C1 D1 E1 NaN
2 A2 B2 C2 D2 E2 NaN
3 A3 B3 C3 D3 E3 NaN
0 A4 B4 C4 D4 NaN F4
1 A5 B5 C5 D5 NaN F5
2 A6 B6 C6 D6 NaN F6
3 A7 B7 C7 D7 NaN F7
"""
9.2 数据导出
# 导出到 csv
df.to_csv("data.csv", encoding="utf-8")
# 其他导出 json 文件的方法与之类似;
导出数据到数据库中
import pymysql
from sqlalchemy import create_engine
# 创建数据库引擎,传入uri规则的字符串
engine = create_engine('mysql+pymysql://root:chuanzhi@127.0.0.1:3306/python?charset=utf8')
# 数据库中会创建对应的表, 但是对应之间关系没有,数据类型约束可能也没有
df.to_sql('tb_scientists', engine, index=False, if_exists='append')
继续努力,终成大器!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号