
爬虫技术之模拟登录
模拟登录
概述:通过requests模块模拟使用浏览器登录网站的行为。
1.模拟登录原理
概述:模拟登录,一般是网站在浏览器中使用POST请求向后端发送数据请求的过程,响应后的数据一般会设置相关的Session与Cookie标识用户的登录标识。对于前后端分离的项目中,也有可能是加密密钥的token,例如 ,jwt 登录的方式的 token 一般包含时效性,当然cookie 也具备时效性。但是在登录请求的请求头并不用包含,因为这些都是登录后的返回结果的信息,务必注意区分。
2.cookie 的介绍与使用
2.1 cookie 概述
相关博客:https://www.cnblogs.com/Blogwj123/p/15766297.html
简单概述:session 是通常存储在服务端(亦可在浏览器中)的数据,Cookie 是存储在浏览器中的数据,通常是保存浏览器上的键值对,用来保持会话,seesion 的使用一般依赖 cookie 。
cookie 一般可以使用抓包工具进行查看。
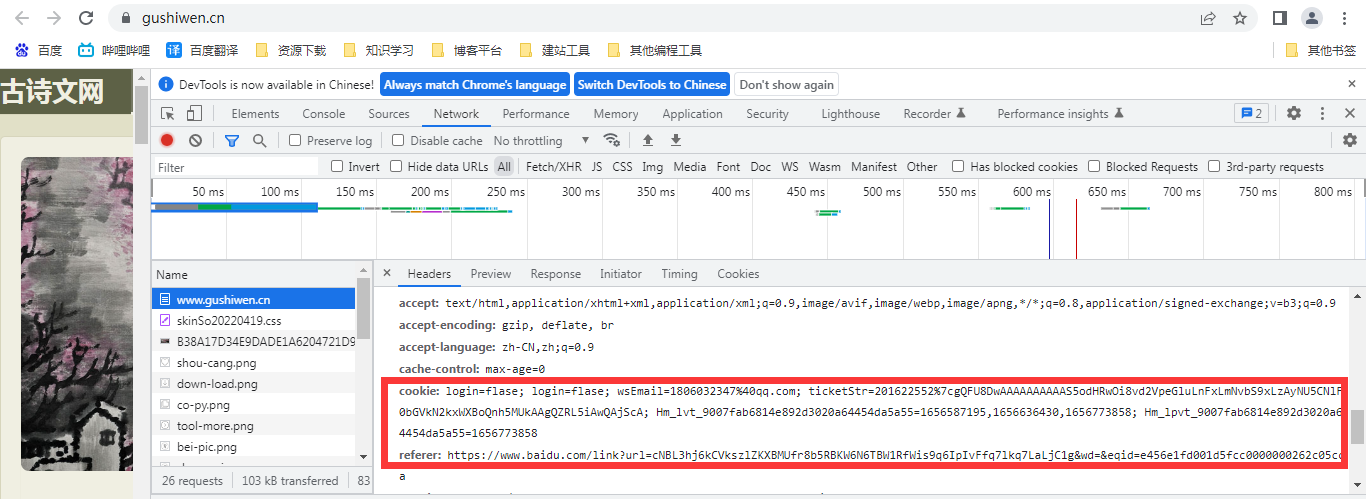
那么爬虫中怎么是用Cookie呢?
2.2 cookie 的使用
手动处理:
-
将cookie从浏览器中复制,进行字典的绑定。
# get请求 params ={ "cookie":"浏览器中进行赋值" } # post请求 data = { "cookie":"浏览器中进行赋值" } -
说明:cookie 一般具备时效性,因此手动处理,原理简单,比较麻烦,不建议使用
-
import requests url = "https://so.gushiwen.cn/user/collect.aspx" headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36", "cookie": "********" } res = requests.get(url=url,headers=headers) with open("ss.html",'w',encoding='utf-8')as fp: fp.write(res.text) -
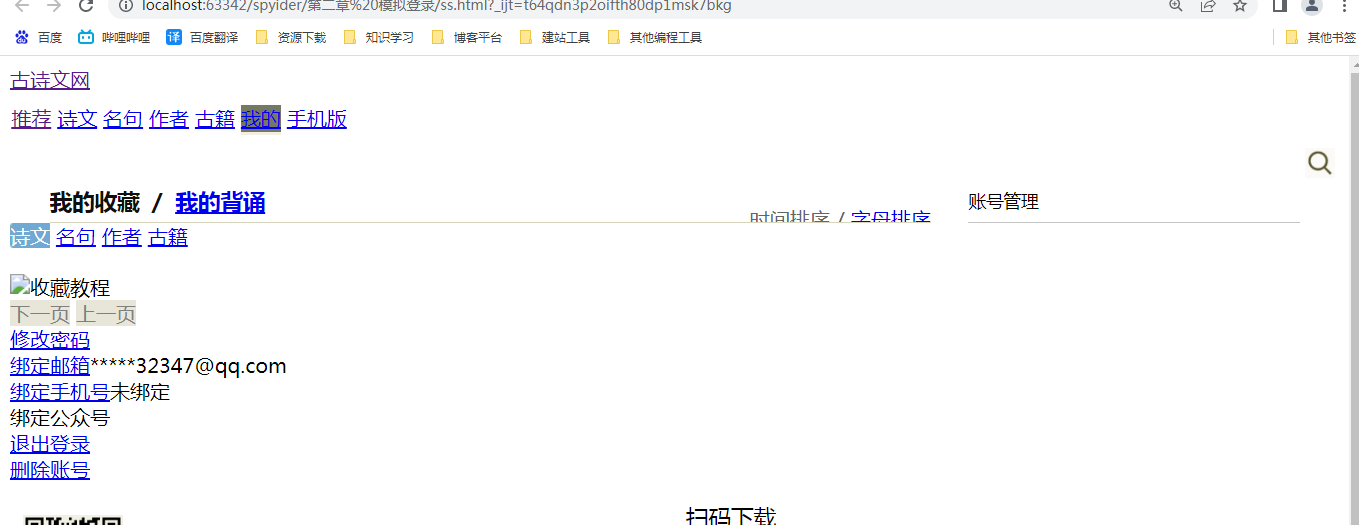
自动处理:
-
在发起请求前实例化
Session对象,直接在requests模块中进行导入,注意,一定要在有cookie 的请求前使用,最好使用单例模式这样所有的请求的 cookie 将会被保存在一个对象中。为了方便起见,可以将所有的请求都使用session进行请求。 -
import requests from lxml import etree # 1. 原始登录路由 url = "https://so.gushiwen.cn/user/login.aspx" # 2. 实例化session对象 session = requests.Session() # 3.发送请求 res = session.get(url=url)
2.3 补充:源码剖析
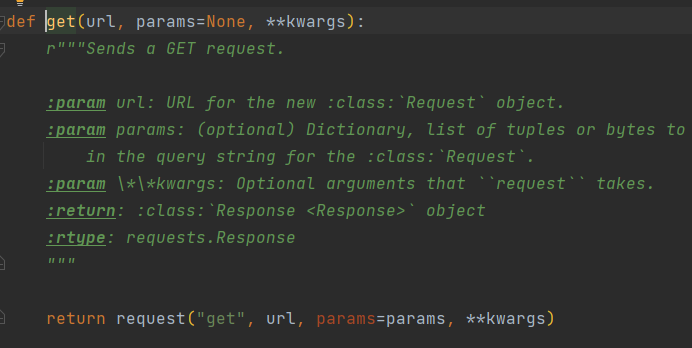
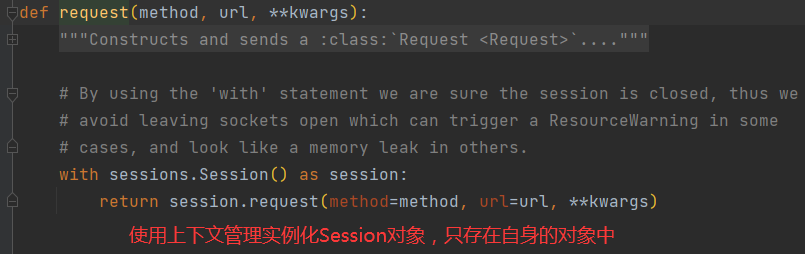
requests 模块内部也嵌套了部分Session操作。
requests 的get 方法如下图所示,调用request
3.模拟登录实战
说明:使用抓取程序需要进行账号的注册,并且具备打码平台的使用经验。
3.1 分析登录流程请求
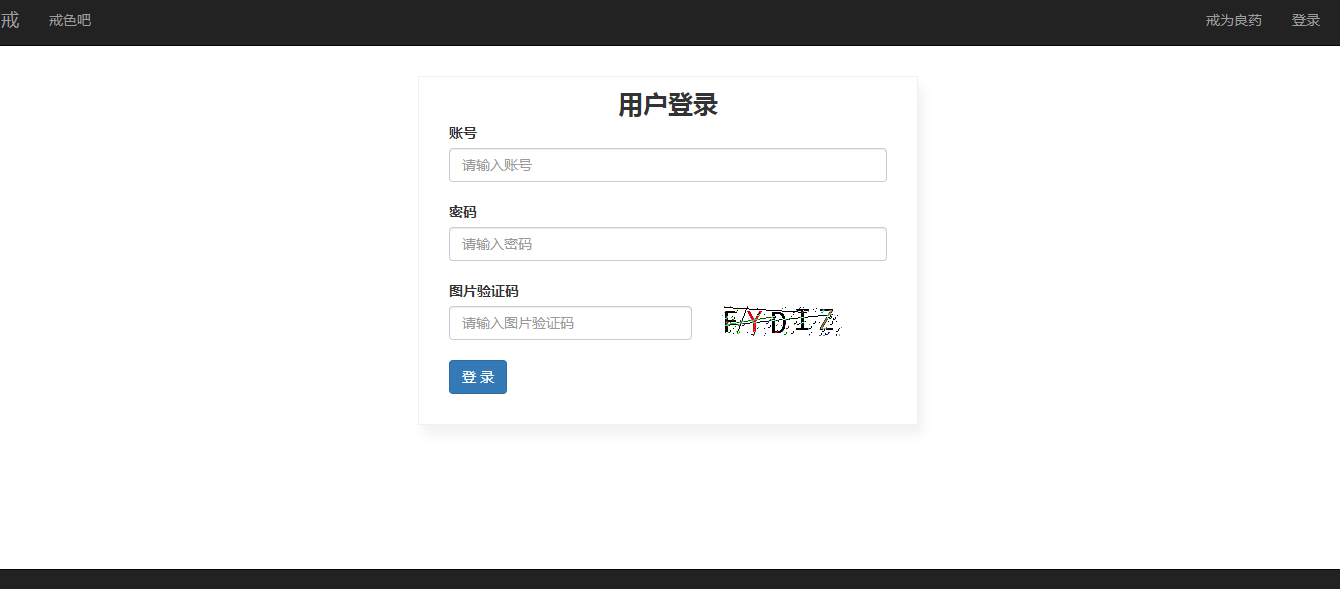
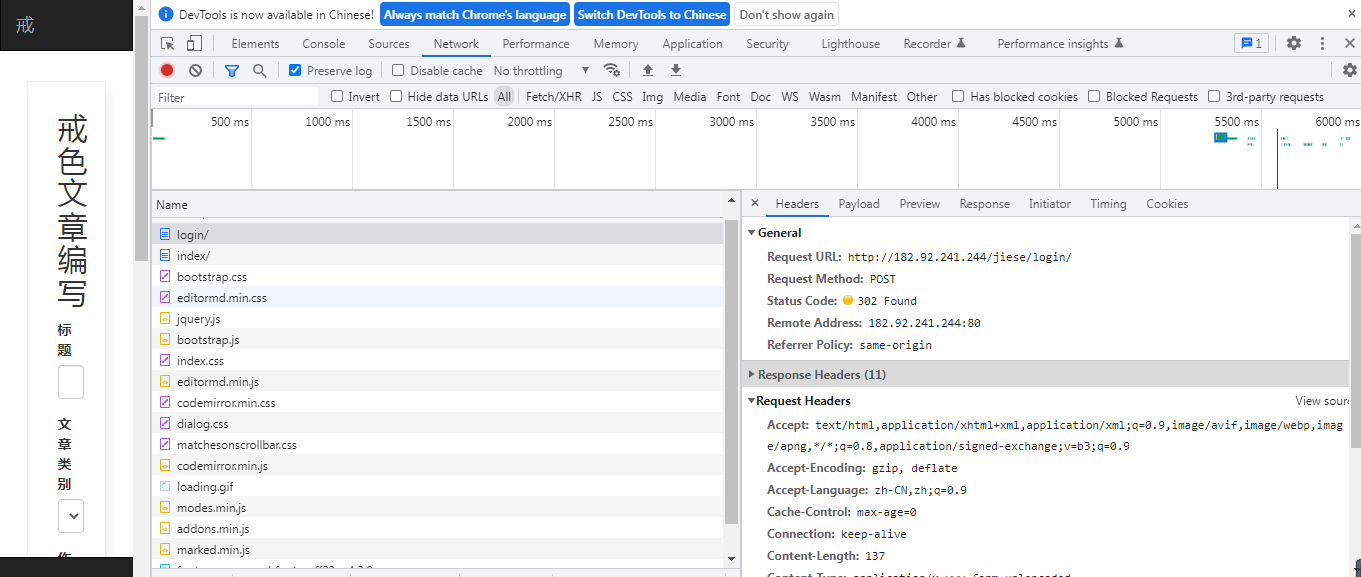
设置请求头的时候一定要把相关的参数进行设置,否则容易造成失败。
import requests
from lxml import etree
from code_result import get_code
session = requests.Session()
url = "http://182.92.241.244/jiese/login/"
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
page_text = session.get(url=url,headers=headers)
tree = etree.HTML(page_text.text)
iamge_code = "http://182.92.241.244/"+tree.xpath('//*[@id="imageCode"]/@src')[0]
image_byte = requests.get(url=iamge_code,headers=headers).content
with open('code.png','wb') as fp:
fp.write(image_byte)
code = get_code('code.png')
headers = {
"Origin": "http://182.92.241.244",
"Referer": "http://182.92.241.244/jiese/login/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Cookie': '#,
}
data ={
"csrfmiddlewaretoken": "#",
"username": "#@qq.com",
"password": "11111",
"code": code
}
resp = session.post(url=url,headers=headers,data=data)
print(resp.headers)
with open("resp.html",'w',encoding='utf-8')as fp:
fp.write(resp.text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号