
验证码的识别
验证码的识别
验证码和爬虫之间的爱恨情仇?
反爬机制:验证码.识别验证码图片中的数据,用于模拟登陆操作。
识别验证码的操作:
-
人工肉眼识别。(不推荐)
-
第三方自动识别(推荐)
-
可以使用机器学习算法或者
gitee上的一些开源项目进行识别,但是效果比较单一。
1.云打码的使用
说明:云打码平台多种多样,不一定局限与某一个。本次使用的云打码平台请点击详情查看;
相关 Python 文档如下图。
平台已经转换好了相关的base64转换等工作,只需将图片的路径传入下面的运行部分即可。
import json
import requests
import base64
class YdmVerify(object):
_nom_url = "https://www.jfbym.com/api/YmServer/verifyapi"
_fun_url = "https://www.jfbym.com/api/YmServer/funnelapi"
_token = "" //填用户中心秘钥
_headers = {
'Content-Type': 'application/json'
}
def common_verify(self, image_content, verify_type="10101"):
# 英文数字,中文汉字,纯英文,纯数字,任意特殊字符
# 请保证购买相应服务后请求对应 verify_type
# verify_type="10101" 单次积分
print(base64.b64encode(image_content).decode())
payload = {
"image": base64.b64encode(image_content).decode(),
"token": self._token,
"type": verify_type
}
resp = requests.post(self._nom_url, headers=self._headers, data=json.dumps(payload))
print(resp.text)
return resp.json()['data']['data']
def slide_verify(self, slide_image, background_image, verify_type="20101"):
# 通用滑块
# 请保证购买相应服务后请求对应 verify_type
# verify_type="20101" 单次积分
# slide_image 需要识别图片的小图片的base64字符串
# background_image 需要识别图片的背景图片的base64字符串(背景图需还原)
payload = {
"slide_image": base64.b64encode(slide_image).decode(),
"background_image": base64.b64encode(background_image).decode(),
"token": self._token,
"type": verify_type
}
resp = requests.post(self._nom_url, headers=self._headers, data=json.dumps(payload))
print(resp.text)
return resp.json()['data']['data']
def click_verify(self, image, extra=None, verify_type=30001):
# 点选,点选+额外参数
# 请保证购买相应服务后请求对应 verify_type
# verify_type="30001" 单次积分 点选
# verify_type="30002" 单次积分 点选+需要按某种语义点选
# 注意:
# 例如 :extra="请_点击_与小体积黄色物品有相同形状的大号物体。"
# 例如 :extra="请点击正向的大写V。"
# 例如 请依次点击 "鹤" "独" "剩" 这种 转换成:extra="鹤,独,剩"
# 例如 拖动交换2个图块复原图片 这种 转换成:extra="拖动交换2个图块复原图片"
# 如有其他未知类型,请联系我们
payload = {
"image": base64.b64encode(image).decode(),
"token": self._token,
"type": verify_type
}
print(base64.b64encode(image).decode())
if extra:
payload['extra'] = extra
payload['type'] = str(int(payload['type'])+1)
resp = requests.post(self._nom_url, headers=self._headers, data=json.dumps(payload))
print(resp.text)
return resp.json()['data']['data']
def hcaptcha_verify(self, site_key, site_url, verify_type="50001"):
# Hcaptcha
# 请保证购买相应服务后请求对应 verify_type
# verify_type="50001"
payload = {
"site_key": site_key,
"site_url": site_url,
"token": self._token,
"type": verify_type
}
resp = requests.post(self._fun_url, headers=self._headers, data=json.dumps(payload))
print(resp.text)
return resp.json()['data']['data']
if __name__ == '__main__':
Y = YdmVerify()
with open("../1.png", 'rb') as f:
img_content = f.read()
Y.common_verify(img_content)
2.古诗文网的验证码识别
# -*- coding: utf-8 -*-
import requests
from lxml import etree
from code_result import YdmVerify
url = "https://so.gushiwen.cn/user/login.aspx"
# UA 伪装
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
# 请求界面
response = requests.get(url=url,headers=headers).text
tree = etree.HTML(response) # 实例化xpath解析对象
# 使用XPath 表达式进行数据解析,获取相关的数据
img_code = "https://so.gushiwen.cn"+tree.xpath('//*[@id="imgCode"]/@src')[0]
# 请求图片保存到本地(二进制)
image_byte = requests.get(url=img_code,headers=headers).content
# 写入文件
with open('code.png','wb') as fp:
fp.write(image_byte)
# 使用打码平台进行打码
Y = YdmVerify()
with open("code.png", 'rb') as f:
img_content = f.read()
resp = Y.common_verify(img_content)
print(resp)
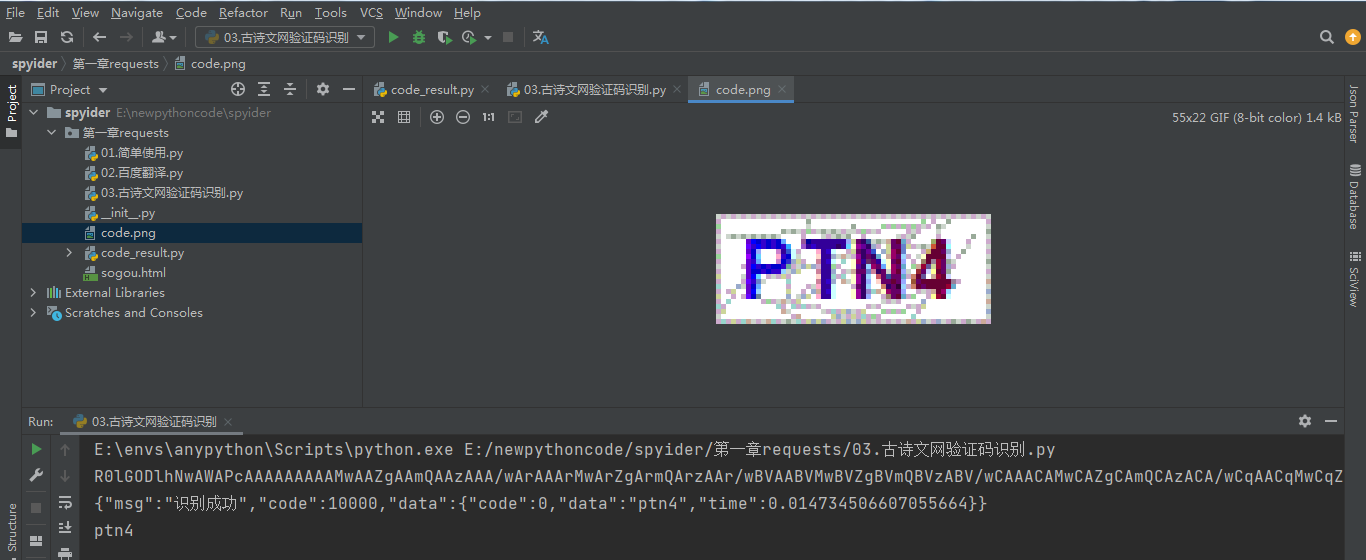
其他类型的验证码可以参考平台对应的打码接口。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号