
requests 模块的使用与数据解析的介绍
requests 模块的使用与数据解析的介绍
提前补充:Python 中常用的发送网络信息就是requests和urllib模块。
1.介绍
requests模块:python中一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发请求。
如何使用:(requests模块的编码流程)
指定url
- UA伪装
- 请求参数的处理
发起请求
获取响应数据
持久化存储
环境安装:
pip install requests
2.实战演练
2.1 爬取搜狗首页
get 函数的源码
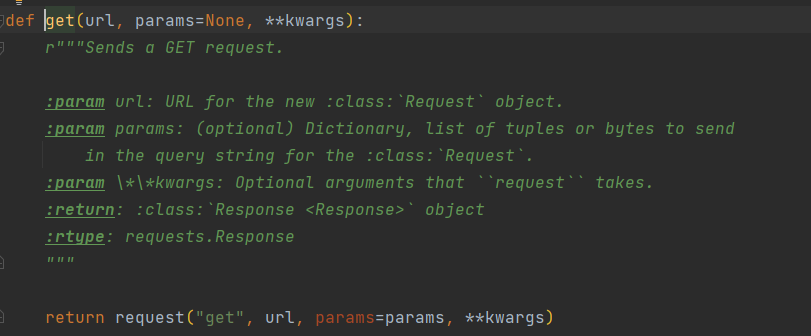
import requests
if __name__ == '__main__':
url = 'https://www.sogou.com/'
# step_2:发起请求
# get方法会返回一个响应对象
response = requests.get(url=url)
# step_3:获取响应数据.text返回的是字符串形式的响应数据
page_text = response.text
print(page_text)
# step_4:持久化存储
with open('./sogou.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
print('爬取数据结束!!!')
2.2 UA标识的使用
UA:User-Agent(请求载体的身份标识)
- UA检测:门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求。但是,如果检测到请求的载体身份标识不是基于某一款浏览器的,则表示该请求为不正常的请求(爬虫),则服务器端就很有可能拒绝该次请求。
- UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
import requests
if __name__ == "__main__":
#UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://www.sogou.com/web'
#处理url携带的参数:封装到字典中
kw = input('enter a word:')
param = {
'query':kw
}
#对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url=url,params=param,headers=headers)
page_text = response.text
fileName = kw+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'保存成功!!!')
2.3 百度翻译的抓取使用
post 函数源码
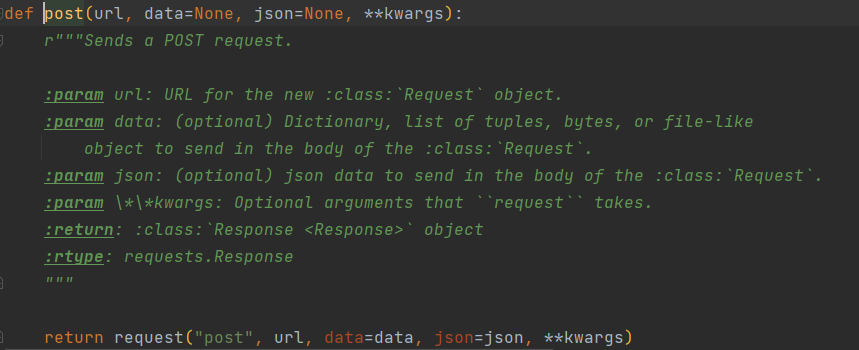
import requests
url = "https://fanyi.baidu.com/sug"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
#3.post请求参数处理(同get请求一致)
word = input('enter a word:')
data = {
'kw':word
}
#4.请求发送
response = requests.post(url=url,data=data,headers=headers)
#5.获取响应数据:json()方法返回的是obj(如果确认响应数据是json类型的,才可以使用json())
dic_obj = response.json()
print(">>>",dic_obj)
参数使用:get 请求一般是params,post 请求一般是data
3.数据解析
-
聚焦爬虫:爬取页面中指定的页面内容。
-
编码流程:
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
-
数据解析分类:
- 正则
- bs4
- xpath
3.1 正则解析
'''
<div class="thumb">
<a href="/article/121721100" target="_blank">
<img src="//pic.qiushibaike.com/system/pictures/12172/121721100/medium/DNXDX9TZ8SDU6OK2.jpg" alt="指引我有前进的方向">
</a>
</div>
'''
# 正则表达式
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
3.2 BS4 解析
数据解析的原理:
- 1.标签定位
- 2.提取标签、标签属性中存储的数据值
bs4数据解析的原理:
- 1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
- 2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
环境安装
pip install bs4
pip install lxml
如何实例化BeautifulSoup对象:
- from bs4 import BeautifulSoup
- 对象的实例化:
# 1.将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
# 2.将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeatifulSoup(page_text,'lxml')
- 提供的用于数据解析的方法和属性:
- soup.tagName:返回的是文档中第一次出现的tagName对应的标签
- soup.find():
- find('tagName'):等同于soup.div
- 属性定位:
- soup.find('div',class_/id/attr='song')
- soup.find_all('tagName'):返回符合要求的所有标签(列表)
- select:
- select('某种选择器(id,class,标签...选择器)'),返回的是一个列表。
- 层级选择器:
- soup.select('.tang > ul > li > a'):>表示的是一个层级
- oup.select('.tang > ul a'):空格表示的多个层级
- 获取标签之间的文本数据:
- soup.a.text/string/get_text()
- text/get_text():可以获取某一个标签中所有的文本内容
- string:只可以获取该标签下面直系的文本内容
- 获取标签中属性值:
- soup.a['href']
注:本人通常不使用该方法解析,本部分内容较少。
3.3 XPath 解析
xpath解析:最常用且最便捷高效的一种解析方式。通用性。
-
xpath解析原理:
- 1.实例化一个 etree 的对象,且需要将被解析的页面源码数据加载到该对象中。
- 2.调用etree对象中的 xpath 方法结合着xpath表达式实现标签的定位和内容的捕获。
-
环境的安装:
-
pip install lxml
-
-
如何实例化一个etree对象:
from lxml import etree-
1.将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath) -
2.可以将从互联网上获取的源码数据加载到该对象中:
etree.HTML('page_text') -
xpath('xpath表达式')
-
-
xpath表达式:
-
/:表示的是从根节点开始定位。表示的是一个层级。 -
//:表示的是多个层级。可以表示从任意位置开始定位。 -
属性定位://div[@class='song'] tag[@attrName="attrValue"]
-
索引定位://div[@class="song"]/p[3] 索引是从1开始的。
-
取文本:
/text():获取的是标签中直系的文本内容//text():标签中非直系的文本内容(所有的文本内容)
-
取属性:
/@attrName==>img/srcDIV/IMG/@src # 获得照片的连接地址
-
注:XPath 解析式可以从浏览器中进行获取,但是,当选择的元素是存在表格(tbody)中的话,需要进行手动输入,因为极容易检测不到元素;另一种情况则是使用了<iframe>标签引用的第三方网页,使用浏览器的获取,不会获取到外层的XPath值。
说明:本部分的代码示例,暂时不在此处进行演示,将在后面的实战案例中进行演示;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号