drf(七)—序列化
drf(七)—序列化
说明:由于序列化涉及内容较多且关系到数据库(ORM),本次先说明使用方式,随后再进行部分源码的剖析;
1. 简单使用
1.1 Serializer使用
# 编写序列化类
class RoleSerializer(serializers.Serializer):
# 其中的变量名应该是数据库中应该存在的值。
id=serializers.IntegerField()
title=serializers.CharField()
class RoleView(APIView):
authentication_classes = []
permission_classes = []
throttle_classes = []
def get(self,*args,**kwargs):
role=models.Role.objects.all()
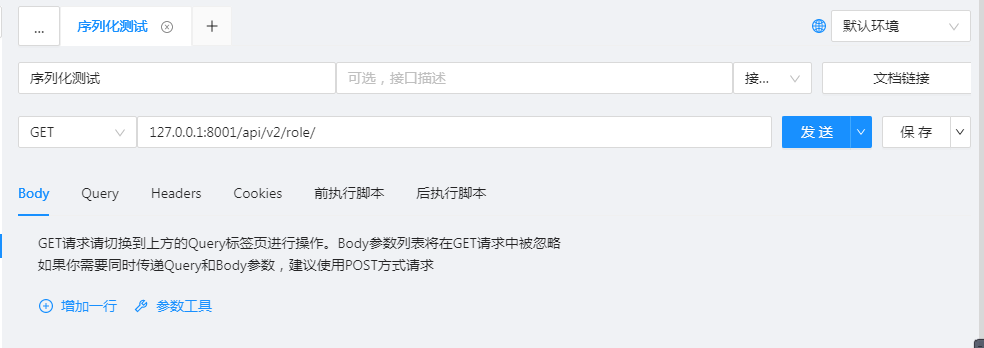
ser=RoleSerializer(instance=role,many=True) #many =True表示多条信息。
data=json.dumps(ser.data)
return HttpResponse(data)
1.2 自定义字段
class RoleSerializer(serializers.Serializer):
# id=serializers.IntegerField()
# 自定义变量的名称,但是需要指定数据库中字段的参数,使用source进行传参。
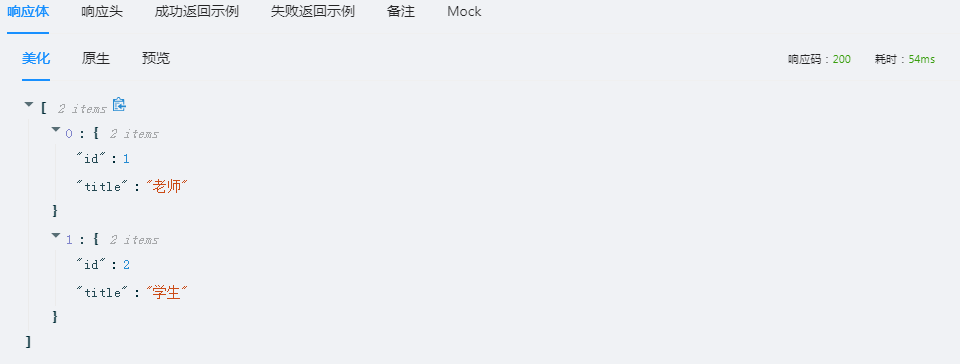
idd=serializers.CharField(source="id")
title=serializers.CharField()
- 自定义变量的名称,但是需要指定数据库中字段的参数,使用
source进行传参。
import json
from django.shortcuts import render,HttpResponse
from rest_framework.views import APIView
from rest_framework import serializers
from api import models
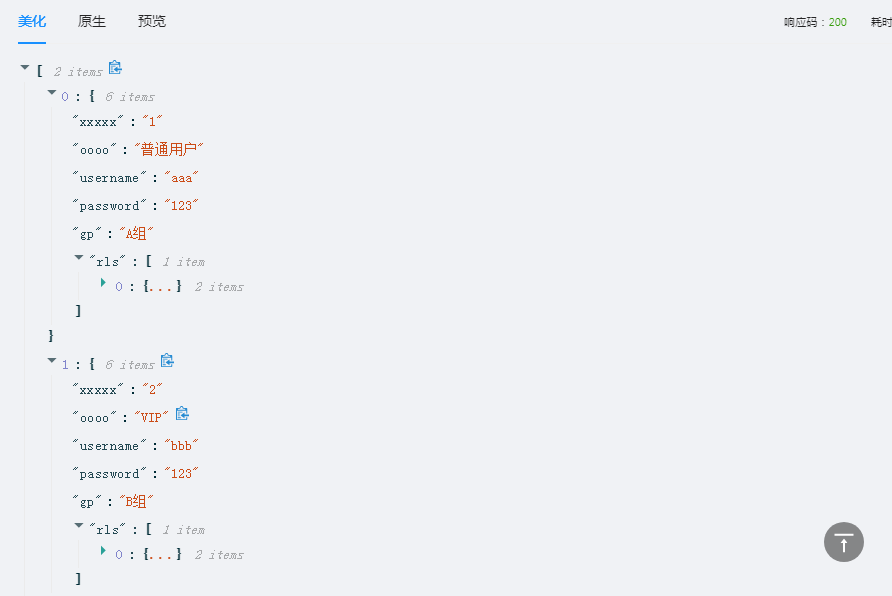
class UserInfoSerializer(serializers.Serializer):
xxxxx = serializers.CharField(source="user_type")
oooo = serializers.CharField(source="get_user_type_display")
username = serializers.CharField()
password = serializers.CharField()
gp = serializers.CharField(source="group.title")
rls=serializers.SerializerMethodField()
def get_rls(self,row):
role_obj_list=row.roles.all()
ret=[]
for item in role_obj_list:
ret.append({'id':item.id,'title':item.title})
return ret
class UserInfoView(APIView):
authentication_classes = []
throttle_classes = []
permission_classes = []
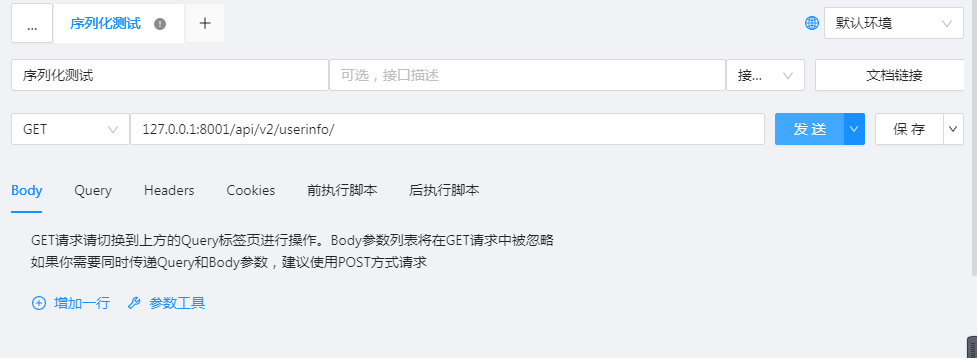
def get(self,request,*args,**kwargs):
users = models.UserInfo.objects.all() # 查询所有对象
ser=UserInfoSerializer(instance=users,many=True,context={"request":request}) # 将对象序列化
ret=json.dumps(ser.data)
return HttpResponse(ret)
补充:
class MyField(serializers.CharField):
def to_representation(self, value):
print(value)
return "xxxxx"
# 继承基本字段得到自定义的字段类型,使得定义的序列化类中存在自定义的类型,
1.3 ModelSerializer使用
说明:本内容的知识与django的form(ModelForm)知识高度相似,可以对比学习。
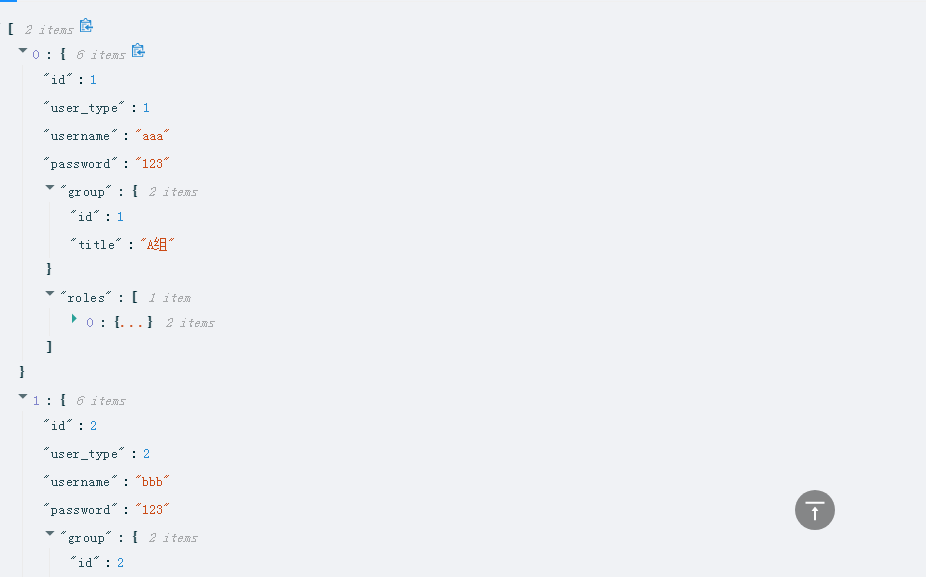
class UserInfoSerializer(serializers.ModelSerializer):
class Meta:
model=models.UserInfo
fields='__all__'
depth=1 # 取到外键关联一般设置为0到3
# 该类也可以想modelform的类一样编写钩子函数,进行验证
-
生成url
使用较少,一般只返回数据不拼url。
# re_path(r'^api/(?P<version>[v1|v2]+)/group/(?P<xxx>\d+)$', views.GroupView.as_view(),name='gp'), class UserInfoSerializer(serializers.ModelSerializer): # group = serializers.HyperlinkedIdentityField(view_name="gp", lookup_field='group_id', lookup_url_kwarg='xxx') group = serializers.HyperlinkedIdentityField(view_name='gp', lookup_field='group_id', lookup_url_kwarg='xxx') class Meta: model=models.UserInfo # fields='__all__' fields = ['id', 'username', 'password', 'group', 'roles'] depth=0 # 取到外键关联一般设置为0到3 class UserInfoView(APIView): authentication_classes = [] throttle_classes = [] permission_classes = [] def get(self,request,*args,**kwargs): users = models.UserInfo.objects.all() # 查询所有对象 ser=UserInfoSerializer(instance=users,many=True,context={"request":request}) # 将对象序列化 ret=json.dumps(ser.data) return HttpResponse(ret)
1.4 序列化验证的使用
自定义验证类使用较少,不做过多的解释。
# 自定义验证类
class XXValidator(object):
def __init__(self, base):
self.base = base
def __call__(self, value):
if not value.startswith(self.base):
message = '标题必须以 %s 为开头。' % self.base
raise serializers.ValidationError(message)
def set_context(self, serializer_field):
"""
This hook is called by the serializer instance,
prior to the validation call being made.
"""
# 执行验证之前调用,serializer_fields是当前字段对象
pass
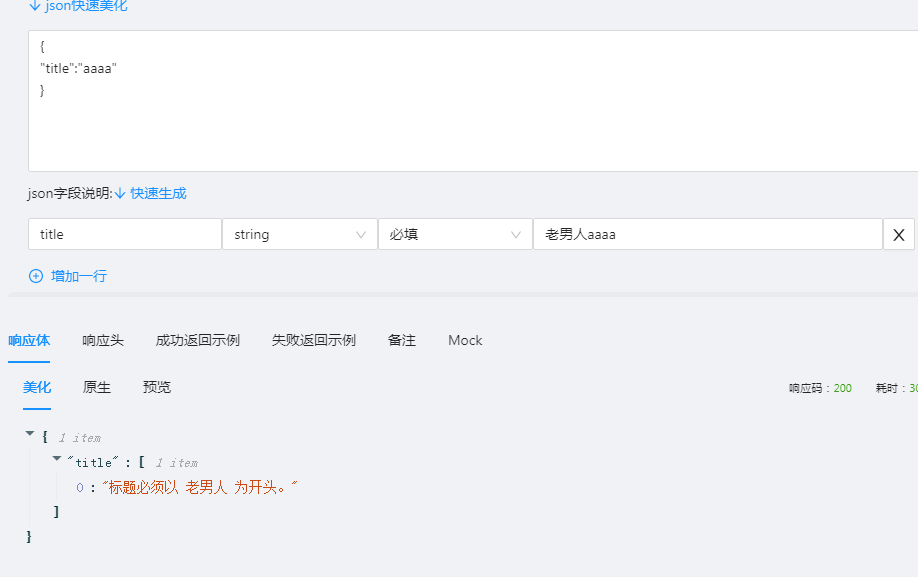
class UserGroupSerializer(serializers.Serializer):
title=serializers.CharField(error_messages={"required":'标题不能为空'},validators=[XXValidator('老男人')])
class UserGroupView(APIView):
authentication_classes = []
permission_classes = []
throttle_classes = []
def post(self,request,*args,**kwargs):
ser=UserInfoSerializer(data=request.data)
if ser.is_valid():
print(ser.validated_data['title'])
return HttpResponse("提交数据")
else:
print(ser.errors)
return HttpResponse("错误")
钩子函数的使用
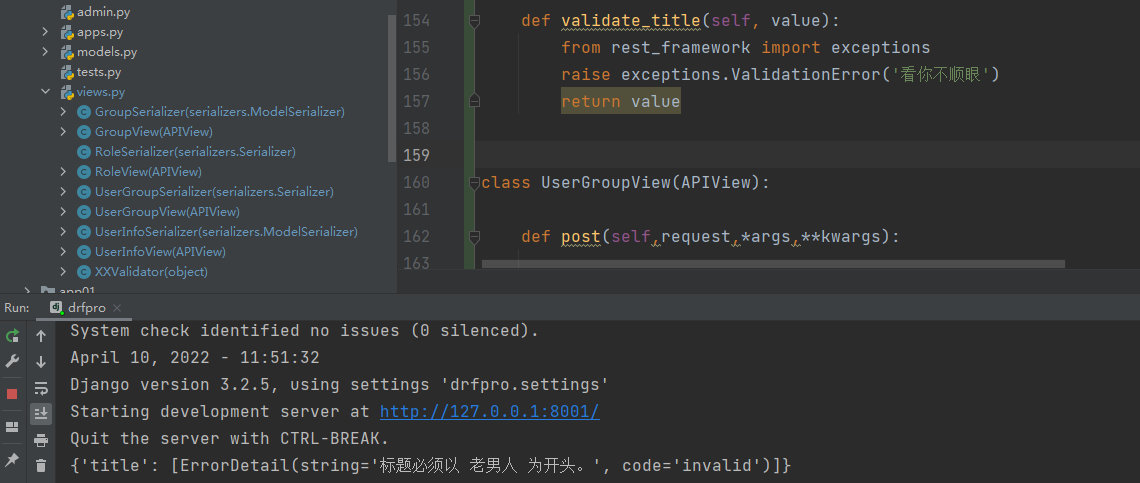
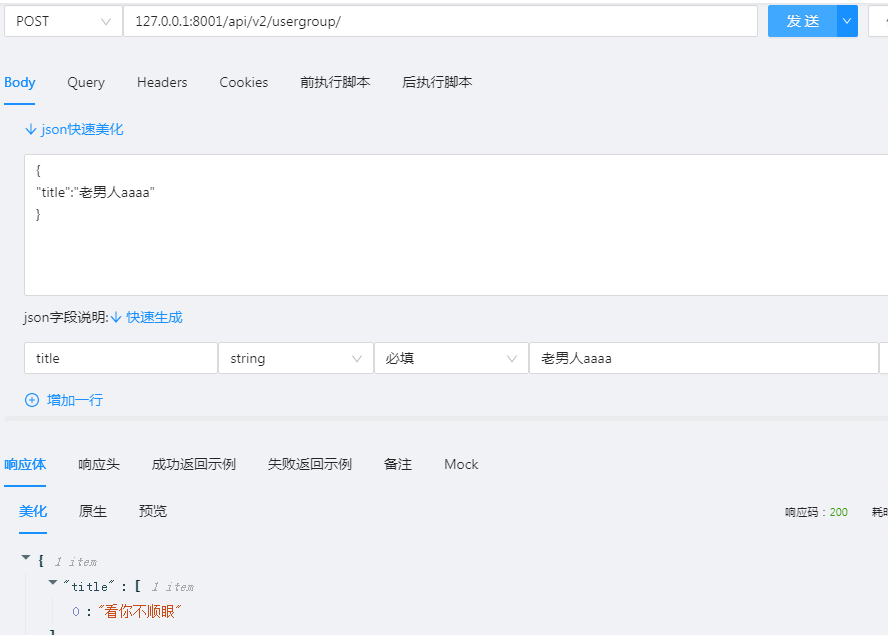
class UserGroupSerializer(serializers.Serializer):
title = serializers.CharField(error_messages={'required':'标题不能为空'},validators=[XXValidator('老男人'),])
def validate_title(self, value): #使用 钩子函数进行验证。
from rest_framework import exceptions
raise exceptions.ValidationError('看你不顺眼')
return value
2. 源码剖析
个人使用的时候
class RoleSerializer(serializers.Serializer):
# id=serializers.IntegerField()
idd=serializers.CharField(source="id")
title=serializers.CharField()
# 自定义的没有构造方法去父类中去找
class RoleView(APIView):
authentication_classes = []
permission_classes = []
throttle_classes = []
def get(self,*args,**kwargs):
role=models.Role.objects.all()
ser=RoleSerializer(instance=role,many=True) #many =True表示多条信息。
# 实例化对象,实例化的时候执行__new__和__init__方法。
data=json.dumps(ser.data) #执行ser.data
return HttpResponse(data)
源码:
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
@property
def data(self):
ret = super().data
return ReturnDict(ret, serializer=self) #将结果返回为字典的数据类型。
pass #继续继承父类,接着找
class BaseSerializer(Field):
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
if data is not empty:
self.initial_data = data
self.partial = kwargs.pop('partial', False)
self._context = kwargs.pop('context', {})
kwargs.pop('many', None)
super().__init__(**kwargs)
def __new__(cls, *args, **kwargs):
# We override this method in order to automatically create
# `ListSerializer` classes instead when `many=True` is set.
if kwargs.pop('many', False): #当 many 不存在时默认执行False
return cls.many_init(*args, **kwargs)
return super().__new__(cls, *args, **kwargs)# 执行父类的new方法
@property
many_init
@classmethod
def many_init(cls, *args, **kwargs):
allow_empty = kwargs.pop('allow_empty', None)
max_length = kwargs.pop('max_length', None)
min_length = kwargs.pop('min_length', None)
child_serializer = cls(*args, **kwargs)
list_kwargs = {
'child': child_serializer,
}
if allow_empty is not None:
list_kwargs['allow_empty'] = allow_empty
if max_length is not None:
list_kwargs['max_length'] = max_length
if min_length is not None:
list_kwargs['min_length'] = min_length
list_kwargs.update({
key: value for key, value in kwargs.items()
if key in LIST_SERIALIZER_KWARGS
})
meta = getattr(cls, 'Meta', None)
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
# 使用反射获取ListSerializer的属性,进而使得多条数据时返回的是列表形式。
# 返回的是不同的对象。
return list_serializer_class(*args, **list_kwargs)
查看 ser.data的方法
@property
def data(self):
ret = super().data #获取父类中的data属性
return ReturnDict(ret, serializer=self) #将结果返回为字典的数据类型。
父类中的data属性
@property
def data(self):
if hasattr(self, 'initial_data') and not hasattr(self, '_validated_data'):
msg = (
'When a serializer is passed a `data` keyword argument you '
'must call `.is_valid()` before attempting to access the '
'serialized `.data` representation.\n'
'You should either call `.is_valid()` first, '
'or access `.initial_data` instead.'
)
# 使用反射查看,当前对象是否包含`initial_data` 或者不包含 `_validated_data`的时候 抛出该异常。
raise AssertionError(msg)
if not hasattr(self, '_data'): #
# 不存在时执行to_representation方法
if self.instance is not None and not getattr(self, '_errors', None):
self._data = self.to_representation(self.instance)
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else:
self._data = self.get_initial()
return self._data
listserlizer中的to_representation
def to_representation(self, data):
"""
List of object instances -> List of dicts of primitive datatypes.
"""
# Dealing with nested relationships, data can be a Manager,
# so, first get a queryset from the Manager if needed
iterable = data.all() if isinstance(data, models.Manager) else data
return [
# 循环可迭代对象(数据库中查到的结果)并生成结果,返回类型。
self.child.to_representation(item) for item in iterable
]
生成url的类及每个字段的类型处理
说明:每个字段在序列化类中都是对象,而每个对象在执行data的时候要执行to_representation方法;
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
def to_representation(self, instance):
ret = OrderedDict() # 使用有序字典
fields = self._readable_fields
for field in fields:
try:
# 循环每一个对象并过获取其
# 去数据库过去对相应的值。
# HyperlinkedIdentityField取到的是对象。
attribute = field.get_attribute(instance)
except SkipField:
continue
check_for_none = attribute.pk if isinstance(attribute, PKOnlyObject) else attribute
if check_for_none is None:
ret[field.field_name] = None
else:
'''
{
id:1 ,Charfiled
group:2, HyperlinkedIdentityField
}
'''
# 执行每一个字段的`to_representation`方法,如果是对象则执行
ret[field.field_name] = field.to_representation(attribute)
return ret
# CharField中的to_representation方法。
class CharField(Field):
def to_representation(self, value):
return str(value) # 将对象以字符串返回。
url生成类中
class HyperlinkedIdentityField(HyperlinkedRelatedField):
"""
A read-only field that represents the identity URL for an object, itself.
This is in contrast to `HyperlinkedRelatedField` which represents the
URL of relationships to other objects.
"""
def __init__(self, view_name=None, **kwargs):
assert view_name is not None, 'The `view_name` argument is required.'
kwargs['read_only'] = True
kwargs['source'] = '*'
super().__init__(view_name, **kwargs) # 寻找父类的方法
def use_pk_only_optimization(self):
# We have the complete object instance already. We don't need
# to run the 'only get the pk for this relationship' code.
return False
HyperlinkedRelatedField 父类代码
class HyperlinkedRelatedField(RelatedField):
def __init__(self, view_name=None, **kwargs):
if view_name is not None:
self.view_name = view_name
assert self.view_name is not None, 'The `view_name` argument is required.'
# 接收我们设置的lookup_field参数。
self.lookup_field = kwargs.pop('lookup_field', self.lookup_field)
self.lookup_url_kwarg = kwargs.pop('lookup_url_kwarg', self.lookup_field)
self.format = kwargs.pop('format', None)
# We include this simply for dependency injection in tests.
# We can't add it as a class attributes or it would expect an
# implicit `self` argument to be passed.
self.reverse = reverse # 进行反向生url.
super().__init__(**kwargs)
def to_representation(self, value):
assert 'request' in self.context, (
"`%s` requires the request in the serializer"
" context. Add `context={'request': request}` when instantiating "
"the serializer." % self.__class__.__name__
)
request = self.context['request']
format = self.context.get('format')
# By default use whatever format is given for the current context
# unless the target is a different type to the source.
#
# Eg. Consider a HyperlinkedIdentityField pointing from a json
# representation to an html property of that representation...
#
# '/snippets/1/' should link to '/snippets/1/highlight/'
# ...but...
# '/snippets/1/.json' should link to '/snippets/1/highlight/.html'
if format and self.format and self.format != format:
format = self.format
# Return the hyperlink, or error if incorrectly configured.
try:
# 执行get_url方法。
url = self.get_url(value, self.view_name, request, format)
except NoReverseMatch:
msg = (
'Could not resolve URL for hyperlinked relationship using '
'view name "%s". You may have failed to include the related '
'model in your API, or incorrectly configured the '
'`lookup_field` attribute on this field.'
)
if value in ('', None):
value_string = {'': 'the empty string', None: 'None'}[value]
msg += (
" WARNING: The value of the field on the model instance "
"was %s, which may be why it didn't match any "
"entries in your URL conf." % value_string
)
raise ImproperlyConfigured(msg % self.view_name)
if url is None:
return None
return Hyperlink(url, value)
get_url()方法
def get_url(self, obj, view_name, request, format):
if hasattr(obj, 'pk') and obj.pk in (None, ''):# 获取对象中是否存在参数
return None
lookup_value = getattr(obj, self.lookup_field)
# 使用反射根据lookup_field传入只去数据库中查询
kwargs = {self.lookup_url_kwarg: lookup_value}
return self.reverse(view_name, kwargs=kwargs, request=request, format=format)
验证源码
class UserGroupView(APIView):
authentication_classes = []
permission_classes = []
throttle_classes = []
def post(self,request,*args,**kwargs):
ser=UserInfoSerializer(data=request.data)
if ser.is_valid():
print(ser.validated_data['title'])
return HttpResponse("提交数据")
else:
print(ser.errors)
return HttpResponse("错误")
查看is_valid()函数
def is_valid(self, raise_exception=False):
assert hasattr(self, 'initial_data'), (
'Cannot call `.is_valid()` as no `data=` keyword argument was '
'passed when instantiating the serializer instance.'
)
if not hasattr(self, '_validated_data'):
try:
self._validated_data = self.run_validation(self.initial_data)
# 执行当前对象的`run_validation`
except ValidationError as exc:
self._validated_data = {}
self._errors = exc.detail
else:
self._errors = {}
if self._errors and raise_exception:
raise ValidationError(self.errors)
return not bool(self._errors) #有错误不通过
run_validation()
def run_validation(self, data=empty):
(is_empty_value, data) = self.validate_empty_values(data)
if is_empty_value: # 检查字段是否为空
return data
value = self.to_internal_value(data) #执行本方法
try:
self.run_validators(value)
value = self.validate(value)
assert value is not None, '.validate() should return the validated data'
except (ValidationError, DjangoValidationError) as exc:
raise ValidationError(detail=as_serializer_error(exc))
return value
to_internal_value方法
def to_internal_value(self, data):
"""
Dict of native values <- Dict of primitive datatypes.
"""
if not isinstance(data, Mapping):
message = self.error_messages['invalid'].format(
datatype=type(data).__name__
)
raise ValidationError({
api_settings.NON_FIELD_ERRORS_KEY: [message]
}, code='invalid')
ret = OrderedDict()
errors = OrderedDict()
fields = self._writable_fields
for field in fields:
# 使用反射获取对象中是否存在`validate_filed`的方法,不存在则返回为None
validate_method = getattr(self, 'validate_' + field.field_name, None)
primitive_value = field.get_value(data)
try:
# 首先执行紫衫参数中的正则验证
validated_value = field.run_validation(primitive_value)
if validate_method is not None: # 执行定义的钩子函数。
validated_value = validate_method(validated_value)
except ValidationError as exc:
# 此处在处理异常说明不通过验证的时候可以触发本异常
errors[field.field_name] = exc.detail
except DjangoValidationError as exc:
errors[field.field_name] = get_error_detail(exc)
except SkipField:
pass
else:
set_value(ret, field.source_attrs, validated_value)
if errors:
raise ValidationError(errors)
return ret
通过本部分源码可知:
自定义的钩子方法应该是以validate_开头加上字段名称进行结尾。也可以进行异常的处理。处理后需要返回的时候在视图函数中进行json处理。用法参考上面的部分。
3. 内容总结
- 序列化部分源码比较混乱,读源码较为困难。
- 深刻体会,反射是框架的灵魂
- 序列化是drf中与数据库关联较深的部分,自己编写的代码主要集中在本部分。
- 本章重点主要在于使用。
- 序列化的知识与 django 中的 form 相似,可以对比学习
接着加油干!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号