爬取古诗文网的孙子兵法
网址:https://www.gushiwen.org/guwen/sunzi.aspx
访问地址:
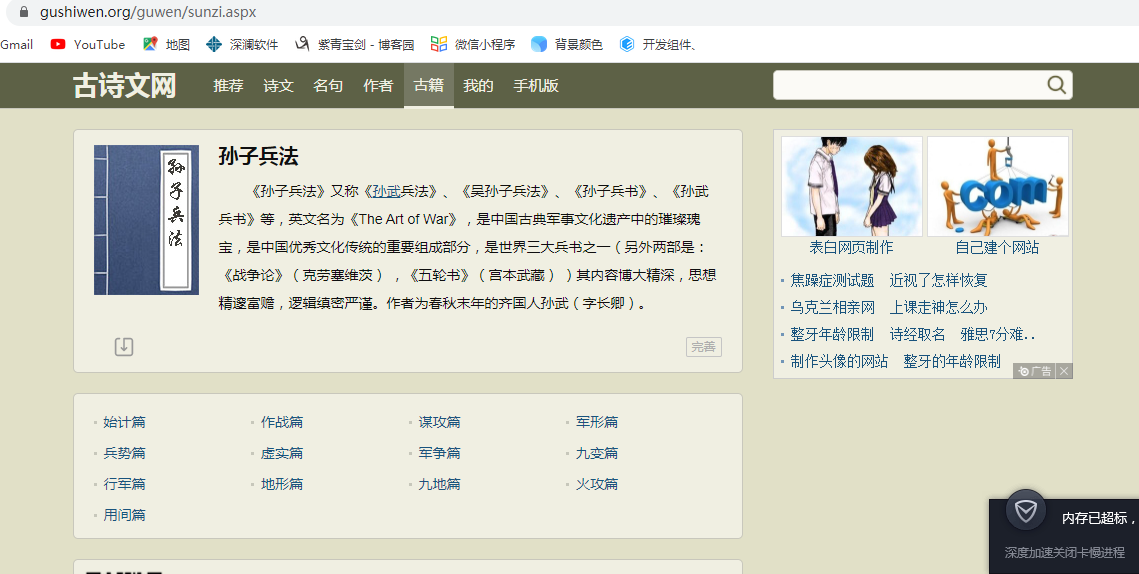
进行页面的分析:通过抓包工具进行分析
标题:
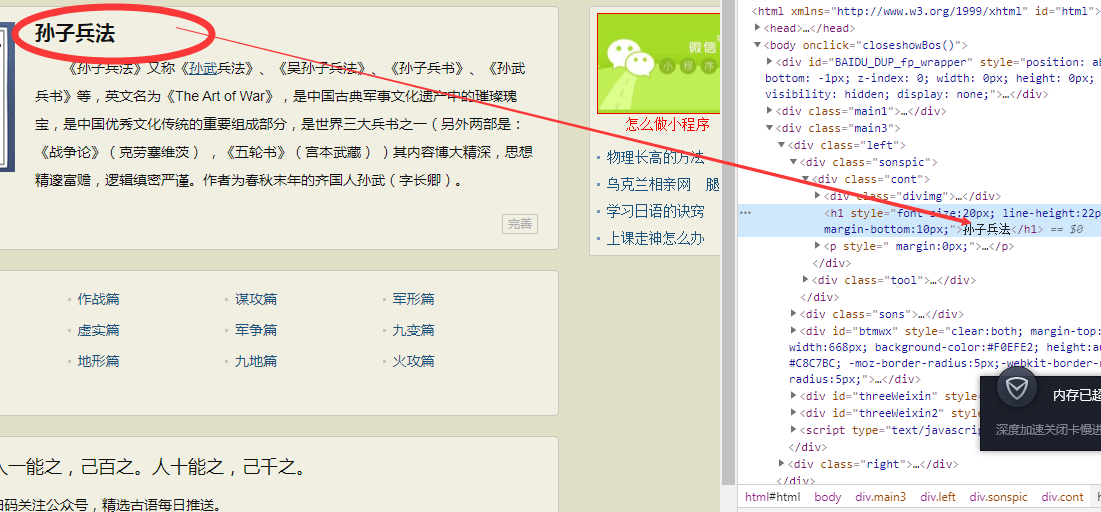
章节目录链接:

进行第一部分的代码编写:
# author:ziqingbaojian # 导入第三方模块 import requests import re from lxml import etree import os # 使用OS模块创建文件 dirName='./孙子兵法' if not os.path.exists(dirName): os.mkdir(dirName) url='https://www.gushiwen.org/guwen/sunzi.aspx' # 构造U-A伪装: headers={ 'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36' } # 请求数据 page_text=requests.get(url=url,headers=headers).text # 使用xpath解析 tree=etree.HTML(page_text) # 获取图书名称 title=tree.xpath('/html/body/div//h1/text()')[0] # 成功获取书名,进行章节url的爬取 ex='<span><a href="(.*?)">' word_url=re.findall(ex,page_text,re.S) ex2='<span><a href=".*?">(.*?)</a></span>' chapter_name=re.findall(ex2,page_text,re.S) # 创建文本,写入图书名称 word_path=dirName+'/szbf2.txt' with open(word_path,'a',encoding='utf-8')as fp: fp.write(title) fp.write('\n') fp.close()
进行详情页分析:
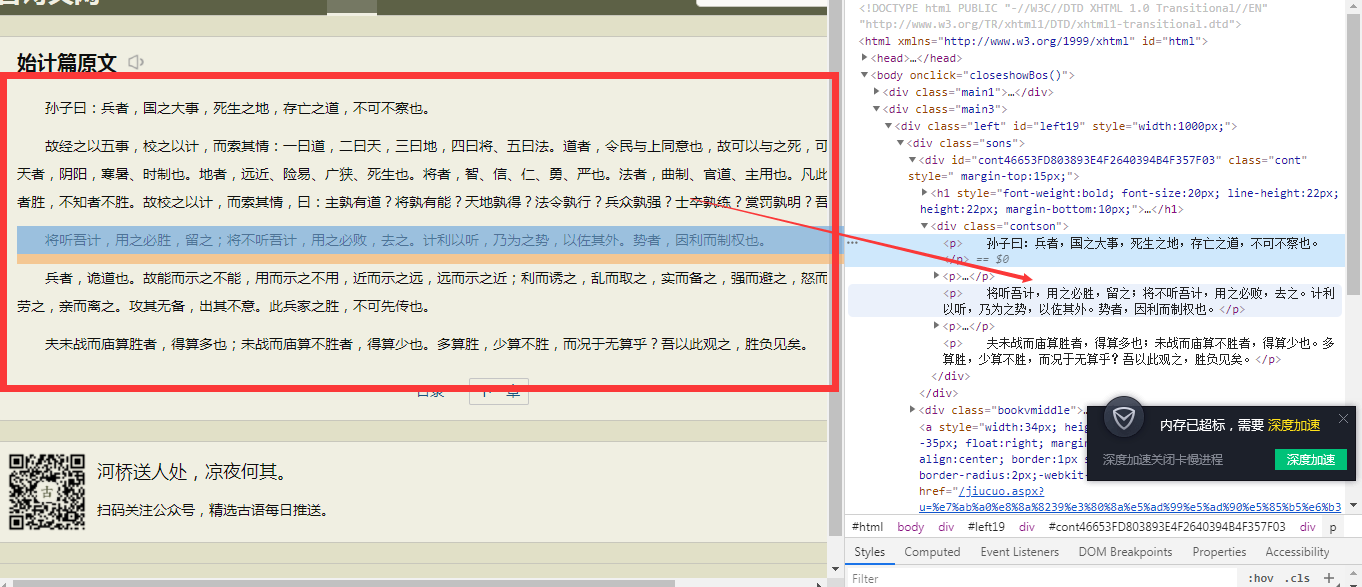
页面的内容在每一p标签下面,进行数据的额解析与存储:
count=0 for word in word_url: word_response= requests.get(url=word,headers=headers).text ex='<div class="contson">(.*?)</div>' p_list=re.findall(ex,word_response,re.S) with open(word_path, 'a', encoding='utf-8')as fp: fp.write(chapter_name[count]) fp.write('\n') fp.close() print(chapter_name[count],'正在下载!!!') count += 1 for p in p_list: ex='<p>(.*?)</p>' word_data=re.findall(ex,p,re.S) # 法一:无分段;使用join.(list)方法将列表转换成字符串 # with open(word_path, 'a', encoding='utf-8')as fp: # fp.write(''.join(word_data)) # # 使用join.(list)方法将列表转换成字符串 # fp.write('\n') for word in word_data: with open(word_path, 'a', encoding='utf-8')as fp: fp.write(word) fp.write('\n')
运行成功界面:
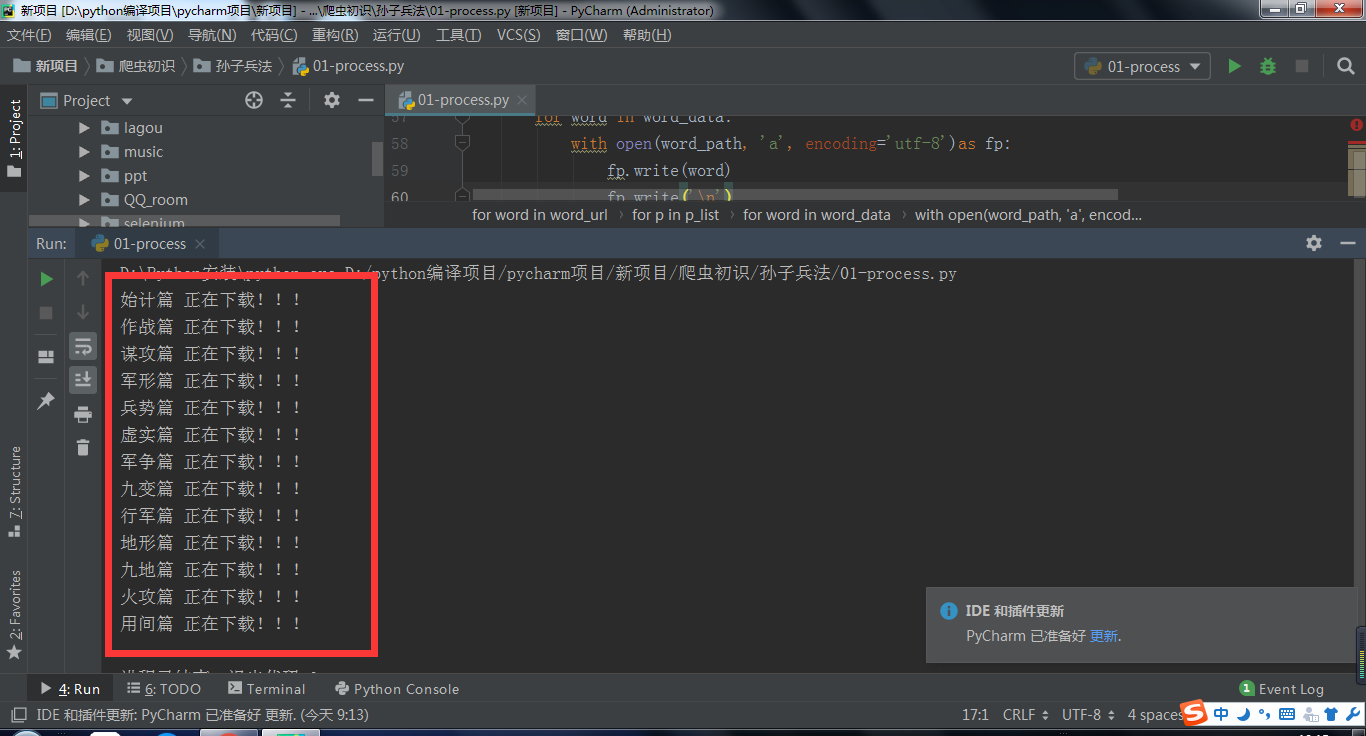
运行成功,感谢观看!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号