
正则
---恢复内容开始---
正则:检测字符串的一条规则。
json的本质还是字符串
一、正则的定义 简写/规则/ 比如/454589/;检测字符串中必须有454589
二、字符串和正则有关的方法
(1)match() 查找到一个或多个正则表达式的匹配。有就返回查找的结果,没有就是null
语法:string.match(reg)
(2)search()查找与正则表达式相匹配的值 检索不到返回-1,检索到了返回查找的字符首次在字符串中的位置
语法 string.search(reg)
(3)replace() 在字符串中查找匹配的子串,并替换与正则表达式匹配的子串
如果检索到 返回替换后的新字符串 如果没有检索到返回原字符串
语法 string.replace(reg,newstring)
字面意思 参数 返回值
三、注意的
- 字符串中的 . 在正则中如果就代表一个 . 需要转义 \.
/./代表任意一个字符 /\./ 代表一个 .
2. 正则对象的两个方法
text() 检索字符串中指定的值 返回true或false
语法 reg.test(string)
exec() 检索字符串中指定的值 返回的是一个数组,有找到的值并确定其位置找不到返回null
语法 reg.exec(string),
四、正则的性质
- 正则的懒惰性
正则在捕获的时候当第一次捕获成功了就直接返回不再向下捕获 这就叫做正则的懒惰性。
解决正则的懒惰性 在正则的后面加上修饰符/g
2. 正则的贪婪性
/\d+/去捕获一个字符串中的数字 他会尽可能多的捕获全部符合条件的 这叫正则的贪婪性

解决正则的贪婪性/\d+/ +代表1个或多个数字 ?代表0个或1个
在+后面跟一个?/\d+?/ +?代表1个
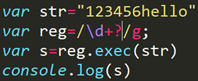
五、字符串检索 分两种结果
第一种是查找型 查找到就终止 不会向下继续查找
第二种是捕获型 分两种 第一是捕获首次出现的 第二种是捕获所有的 /g
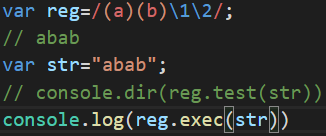
六、分组捕获()这是分组捕获的标志
将大正则分组成几个小正则 在正则中 \1代表第一个分组 \2代表第二个分组
比如 /(a)(b)\1\2/ 代表的abab这个规则
在分组捕获中结果既返回了大正则的捕获结果,也返回了小正则的捕获结果
如果不行捕获某一个分组中的内容在对应的分组中的前面加上?:就可以了同时分组引用(\1\2)也失效
 一旦分组捕获成功 在正则的类上会给$1,$2等赋值,RegExp.$1也是分组引用 在正则外起作用
一旦分组捕获成功 在正则的类上会给$1,$2等赋值,RegExp.$1也是分组引用 在正则外起作用
\1 也是分组引用 只能在正则中起作用
七、hph的正则方法
(1)preg_match()执行一个正则表达式匹配
参数 1 是 reg 参数 2 是 string 返回值是0或1 查到就是1 查不到就是0
(2)preg_match_all()执行一个全局正则表达式匹配
参数 1 是 reg 参数 2 是 string 返回值是0和 nn 是查找到的总次数0 是没有查到
(3)preg_replace()指向一个正则表达式的搜索和替换
参数 1 是 reg 参数 2 是newstring 参数 3 是检索的 string 返回值是替换后的新的字符串
第三个参数还可以是数组 返回值也是数组
(4)Preg_split通过一个正则表达式分隔字符串
参数 1 是 reg 参数 2 是 string
---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号