
HBase 架构:HBase 数据模型和 HBase 读/写机制
HBase 架构:HBase 数据模型
众所周知,HBase是一个面向列的NoSQL数据库。虽然它看起来类似于包含行和列的关系数据库,但它不是关系数据库。关系数据库是面向行的,而 HBase 是面向列的。因此,让我们首先了解面向列的数据库和面向行的数据库之间的区别:
面向行的数据库与面向列的数据库:
- 面向行的数据库将表记录存储在一系列行中。而面向列的数据库将表记录存储在列序列中,即列中的条目存储在磁盘上的连续位置。
为了更好地理解它,让我们举一个例子并考虑下表。
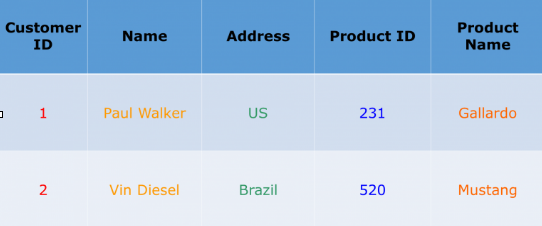
如果此表存储在面向行的数据库中。它将存储如下所示的记录:
1, 保罗·沃克, 美国, 231, 加利亚多,
2, 温·迪索, 巴西, 520, 野马
在面向行的数据库中,数据基于行或元组存储,如上所示。
而面向列的数据库将此数据存储为:
1,2, 保罗·沃克, 温·迪索, 美国, 巴西, 231, 520, 加拉多, 野马
在面向列的数据库中,所有相同类型列值存储在一起,先把第一列值存储在一起,然后再把第二列值将存储在一起,其他列中的数据也以类似的方式存储。
- 当数据量非常巨大时,例如 PB 或 EB,我们使用面向列的方法,因为单个列的数据存储在一起并且可以更快地访问。
- 虽然面向行的方法相对有效地处理较少的行和列数,但面向行的数据库存储数据是一种结构化格式。
- 当我们需要处理和分析大量半结构化或非结构化数据时,我们使用面向列的方法。例如处理在线分析处理的应用程序,如数据挖掘、数据仓库、包括分析在内的应用程序等。
- 而在线事务处理(例如处理结构化数据并需要事务属性(ACID 属性)的银行和金融域)使用面向行的方法。
HBase 表具有以下组件,如下图所示:
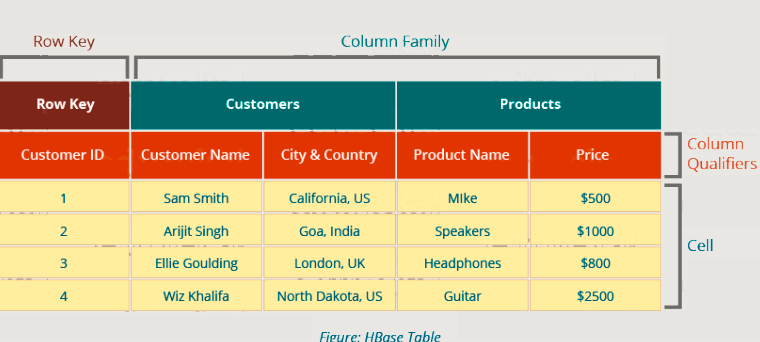
- 表:数据以表格式存储在 HBase 中。但这里的表格是面向列的格式。
- 行键:行键用于搜索记录,使搜索速度更快。你会很好奇怎么做?我将在本博客的架构部分解释它。
- 列系列:各种列组合在一个列系列中。这些列系列存储在一起,这使得搜索过程更快,因为属于同一列系列的数据可以在单个查找中一起访问。
- 列限定符:每个列的名称称为其列限定符。
- 单元格:数据存储在单元格中。数据被转储到由行键和列限定符专门标识的单元格中。
- 时间戳:时间戳是日期和时间的组合。无论何时存储数据,都会存储其时间戳。这使得搜索特定版本的数据变得容易。
以更简单和更易于理解的方式,我们可以说HBase包括:
- 一套表
- 每个表包含列系列和行
- 行键充当 HBase 中的主键。
- 对 HBase 表的任何访问都使用此主键
- HBase 中存在的每个列限定符表示与驻留在单元格中的对象对应的属性。
现在您已经了解了 HBase 数据模型,让我们看看此数据模型如何符合 HBase 体系结构并使其适用于大型存储和更快的处理。
HBase 体系结构:HBase 体系结构的组件
HBase有三个主要组件,即HMaster Server,HBase区域服务器,区域和Zookeeper。
下图说明了 HBase 体系结构的层次结构。我们将分别讨论它们中的每一个。
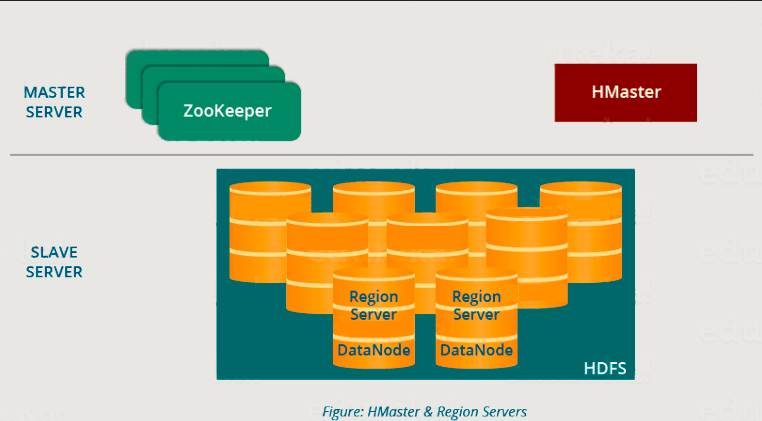
现在在进入HMaster之前,我们将了解区域,因为所有这些服务器(HMaster,区域服务器,Zookeeper)都被放置在协调和管理区域并在区域内执行各种操作。因此,您会很想知道什么是区域以及为什么它们如此重要?
HBase 体系结构:区域
区域包含分配给该区域的开始键和结束键之间的所有行。HBase 表可以划分为多个区域,这样列系列的所有列都存储在一个区域中。每个区域都按排序顺序包含行。
许多区域被分配给区域服务器,该服务器负责处理、管理、执行对这组区域的读取和写入操作。
因此,以更简单的方式得出结论:
- 一个表可以分为多个区域。区域是存储开始键和结束键之间数据的行的排序范围。
- 区域的默认大小为 256MB,可以根据需要进行配置。
- 一组区域由区域服务器提供给客户端。
- 区域服务器可以为客户端提供大约 1000 个区域。
现在从层次结构的顶部开始,我想首先向您解释一下HMaster Server,它的作用类似于HDFS中的NameNode。然后,在层次结构中向下移动,我将带您了解ZooKeeper和区域服务器。
HBase 架构:HMaster
如下图所示,您可以看到 HMaster 处理驻留在 DataNode 上的区域服务器集合。让我们了解HMaster是如何做到这一点的。
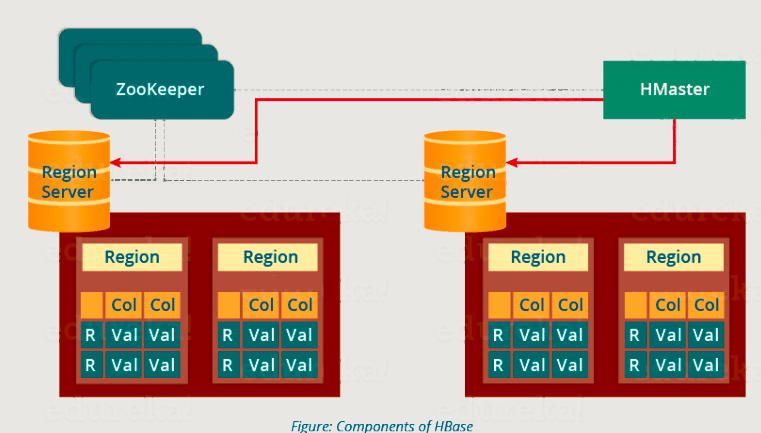
- HBase HMaster 执行 DDL 操作(创建和删除表)并将区域分配给区域服务器,如上图所示。
- 它协调和管理区域服务器(类似于 NameNode 管理 HDFS 中的数据节点)。
- 它在启动时将区域分配给区域服务器,并在恢复和负载平衡期间将区域重新分配给区域服务器。
- 它监控集群中区域服务器的所有实例(在 Zookeeper 的帮助下),并在任何区域服务器关闭时执行恢复活动。
- 它提供了用于创建、删除和更新表的界面。
HBase 有一个分布式和庞大的环境,仅靠 HMaster 不足以管理所有内容。所以,你会想知道是什么帮助HMaster管理这个巨大的环境?这就是ZooKeeper出现的地方。在我们了解了HMaster如何管理HBase环境之后,我们将了解Zookeeper如何帮助HMaster管理环境。
HBase 架构:ZooKeeper – 协调器
下图解释了ZooKeeper的协调机制。
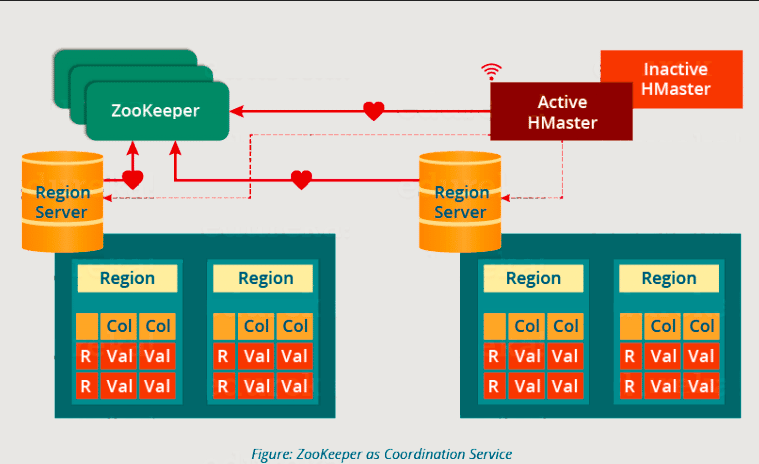
- Zookeeper 就像 HBase 分布式环境中的协调器。它通过会话进行通信来帮助维护群集内的服务器状态。
- 每个区域服务器以及HMaster服务器定期向Zookeeper发送连续的心跳,并检查哪个服务器处于活动状态且可用,如上图所述。它还提供服务器故障通知,以便可以执行恢复措施。
- 从上图中您可以看到,有一个非活动服务器,它充当活动服务器的备份。如果活动服务器发生故障,它会来救援。
- 活动的 HMaster 向 Zookeeper 发送检测信号,而非活动的 HMaster 侦听活动 HMaster 发送的通知。如果活动的 HMaster 无法发送检测信号,会话将被删除,非活动的 HMaster 将变为活动状态。
- 如果区域服务器无法发送检测信号,会话将过期,并且所有侦听器都会收到通知。然后HMaster执行适当的恢复操作,我们将在本博客后面讨论。
- 动物园管理员还维护 .META 服务器的路径,可帮助任何客户端搜索任何区域。客户端首先必须与 核对。区域所属的区域服务器的 META 服务器,它获取该区域服务器的路径。
正如我所说.META服务器,让我先向您解释一下什么是。元服务器?因此,您可以轻松地将ZooKeeper的工作与.元服务器一起。稍后,当我在本博客中向您解释HBase搜索机制时,我将解释这两者如何协同工作。
HBase 体系结构:元表

- META 表是一个特殊的 HBase 目录表。它维护 HBase 存储系统中所有区域服务器的列表,如上图所示。
- 看图你可以看到,.META文件以键和值的形式维护表。键表示区域的开始键及其 id,而值包含区域服务器的路径。
正如我已经讨论过的,区域服务器及其功能,同时我向您解释区域,因此,现在我们正在向下移动层次结构,我将专注于区域服务器的组件及其功能。稍后我将讨论搜索、阅读、写作的机制,并了解所有这些组件如何协同工作。
HBase 体系结构:区域服务器的组件
下图显示了区域服务器的组件。现在,我将分别讨论它们。
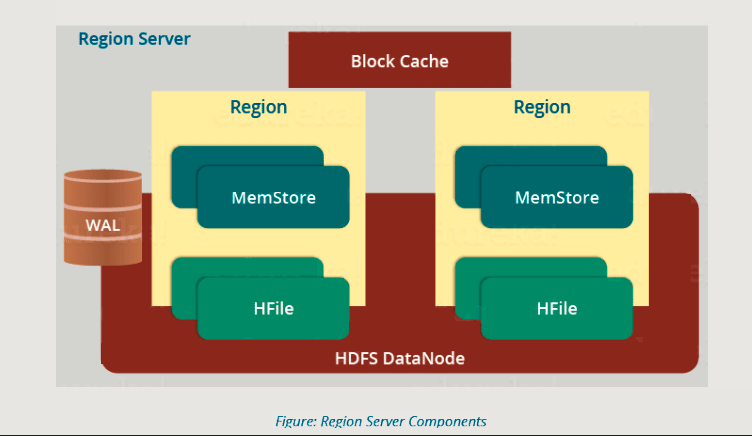
区域服务器维护在 HDFS 上运行的各种区域。区域服务器的组件包括:
- 沃尔玛:从上图中可以得出结论,预写日志(WAL)是附加到分布式环境中每个区域服务器的文件。WAL 存储尚未持久化或提交到永久存储的新数据。它用于恢复数据集失败的情况。
- 块缓存: 从上图中可以清楚地看到块缓存位于区域服务器的顶部。它将经常读取的数据存储在内存中。如果 BlockCache 中的数据最近最少使用,则该数据将从 BlockCache 中删除。
- 内存商店: 它是写缓存。它在将传入数据提交到磁盘或永久内存之前存储所有传入数据。一个区域中的每个列系列都有一个内存存储。如图所示,一个区域有多个 MemStore,因为每个区域都包含多个列系列。数据在提交到磁盘之前按字典顺序排序。
- HFile: 从上图中你可以看到HFile存储在HDFS上。因此,它将实际的单元格存储在磁盘上。当MemStore的大小超过时,MemStore将数据提交到HFile。
现在我们知道了 HBase 体系结构的主要和次要组件,我将解释其机制及其在这方面的协作努力。无论是读取还是写入,首先我们需要搜索从哪里读取或在哪里写入文件。因此,让我们了解一下这个搜索过程,因为这是使HBase非常受欢迎的机制之一。
HBase 体系结构:如何在 HBase 中初始化搜索?
如您所知,Zookeeper存储META表位置。每当客户端接近读取或写入对 HBase 的请求时,都会发生以下操作:
- 客户端从 ZooKeeper 检索 META 表的位置。
- 然后,客户端从 META 表中请求相应行键的区域服务器的位置以访问它。客户端将此信息与 META 表的位置一起缓存。
- 然后,它将通过从相应的区域服务器请求来获取行位置。
为了将来引用,客户端使用其缓存来检索 META 表的位置和以前读取的行键的区域服务器。然后,客户端将不会引用 META 表,直到并且除非由于区域被移动或移动而未命中。然后它将再次向 META 服务器请求并更新缓存。
与每次一样,客户端不会浪费时间从META服务器检索区域服务器的位置,因此,这可以节省时间并使搜索过程更快。现在,让我告诉你写作是如何在HBase中进行的。其中涉及哪些组件,它们是如何参与的?
HBase 架构:HBase 写入机制
下图说明了 HBase 中的写入机制。
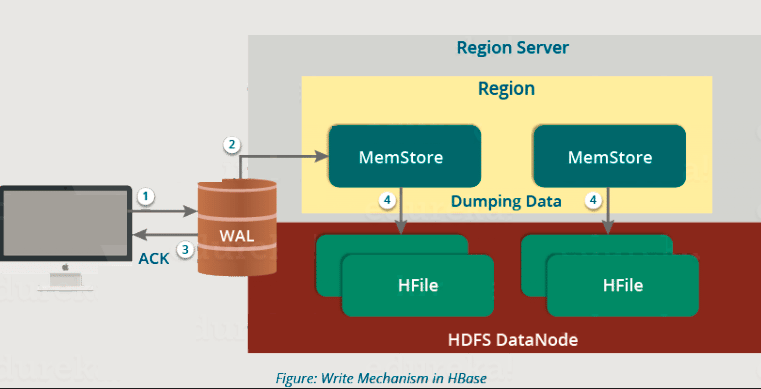
写入机制按顺序执行以下过程(请参阅上图):
第 1 步:每当客户端有写入请求时,客户端都会将数据写入 WAL(预写日志)。
- 然后将编辑内容追加到 WAL 文件的末尾。
- 这个WAL文件在每个区域服务器中都维护,区域服务器使用它来恢复未提交到磁盘的数据。
第 2 步:一旦数据被写入 WAL,它就会被复制到 MemStore。
第 3 步:将数据放置在 MemStore 中后,客户端将收到确认。
第 4 步:当 MemStore 达到阈值时,它会将数据转储或提交到 HFile 中。
现在让我们深入了解一下 MemStore 在写作过程中的贡献以及它的功能是什么?
HBase 写入机制 - 内存存储
- MemStore 始终以字典顺序(以字典方式按顺序)将存储在其中的数据更新为排序的键值。每个列系列都有一个 MemStore,因此每个列系列的更新以排序方式存储。
- 当 MemStore 达到阈值时,它会以排序方式将所有数据转储到新的 HFile 中。这个HFile存储在HDFS中。HBase 为每个色谱柱系列包含多个 HFile。
- 随着时间的推移,HFile 的数量会随着 MemStore 转储数据而增长。
- MemStore 还保存了最后写入的序列号,因此 Master Server 和 MemStore 都知道到目前为止提交的内容以及从哪里开始。当区域启动时,将读取最后一个序列号,并从该编号开始新的编辑。
正如我多次讨论的那样,HFile 是 HBase 架构中的主要持久存储。最后,所有数据都提交到HFile,这是HBase的永久存储。因此,让我们看看 HFile 的特性,它使读取和写入时的搜索速度更快。
HBase 架构:HBase 写入机制 - HFile
- 写入操作按顺序放置在磁盘上。因此,磁盘读写磁头的移动非常小。这使得写入和搜索机制非常快。
- 每当打开 HFile 时,HFile 索引都会加载到内存中。这有助于在单个查找中查找记录。
- 拖车是一个指向 HFile 元块的指针。它写在提交文件的末尾。它包含有关时间戳和布隆过滤器的信息。
- 布隆过滤器有助于搜索键值对,它会跳过不包含所需行键的文件。时间戳还有助于搜索文件的版本,它有助于跳过数据。
了解了写入机制以及各种组件在加快写入和搜索速度方面的作用之后。我将向您解释读取机制在 HBase 架构中的工作原理?然后,我们将讨论提高HBase性能的机制,如压缩,区域拆分和恢复。
HBase 架构:读取机制
如我们的搜索机制中所述,客户端首先从 检索区域服务器的位置。META 服务器(如果客户端的缓存中没有它)。然后,它按如下顺序执行步骤:
- 为了读取数据,扫描程序首先在块缓存中查找行单元格。这里存储了所有最近读取的键值对。
- 如果扫描仪找不到所需的结果,它会移动到MemStore,因为我们知道这是写缓存内存。在那里,它搜索最近写入的文件,这些文件尚未在 HFile 中转储。
- 最后,它将使用布隆过滤器和块缓存从HFile加载数据。
到目前为止,我已经讨论了HBase的搜索,读取和写入机制。现在我们将看看HBase机制,它使HBase中的搜索,读取和写入变得快速。首先,我们将了解压缩,这是这些机制之一。
HBase 体系结构:压缩
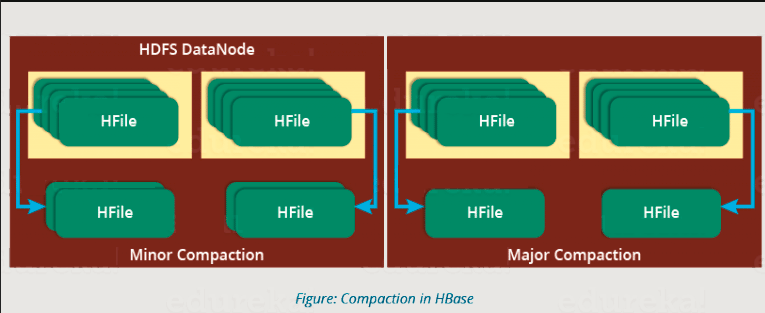
HBase 组合了 HFiles 以减少存储并减少读取所需的磁盘寻道数。此过程称为压缩。压缩从某个区域中选择一些 HFile 并将它们组合在一起。如上图所示,有两种类型的压缩。
- 次要压缩:HBase 自动选取较小的 HFile 并将它们重新提交到较大的 HFile,如上图所示。这称为小压实。它执行合并排序,以将较小的 HFile 提交到较大的 HFile。这有助于优化存储空间。
- 主要压实:如上图所示,在主要压缩中,HBase 合并并将区域中较小的 HFile 重新提交到新的 HFile。在此过程中,相同的色谱柱系列被放置在新的HFile中。在此过程中,它会删除已删除和过期的单元格。它提高了读取性能。
但在此过程中,输入输出磁盘和网络流量可能会拥塞。这称为写入放大。因此,它通常安排在低峰值负载时间。
现在,我将讨论的另一个性能优化过程是区域拆分。这对于负载平衡非常重要。
HBase 体系结构:区域拆分
下图说明了区域拆分机制。
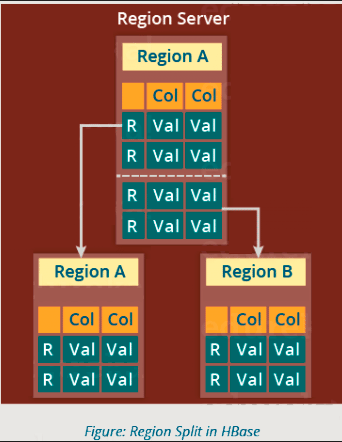
每当一个区域变大时,它就会被划分为两个子区域,如上图所示。每个区域正好代表父区域的一半。然后将此拆分报告给 HMaster。这由同一区域服务器处理,直到 HMaster 将它们分配给新的区域服务器进行负载平衡。
最后但并非最不重要的一点是,我将向您解释HBase如何在发生故障后恢复数据。众所周知,故障恢复是HBase的一个非常重要的功能,因此让我们知道HBase如何在故障后恢复数据。
HBase 架构:HBase 崩溃和数据恢复
- 每当区域服务器发生故障时,ZooKeeper 都会通知 HMaster 有关故障的信息。
- 然后,HMaster 将崩溃的区域服务器的区域分发并分配给许多活动区域服务器。为了恢复故障区域服务器的内存存储的数据,HMaster 将 WAL 分发到所有区域服务器。
- 每个区域服务器重新执行 WAL 以构建该故障区域的列系列的 MemStore。
- 数据按时间顺序(按时间顺序)写入 WAL 中。因此,重新执行该 WAL 意味着进行所有更改并存储在 MemStore 文件中。
- 因此,在所有区域服务器执行 WAL 后,将恢复所有列系列的 MemStore 数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号