
微服务架构中的数据库设计
1. 简介
微服务架构在不断发展。它带来了很多好处,尤其是相对于过时的单体架构。另一方面,使用微服务开发项目时存在多种挑战。最重要的问题之一是数据库设计。在数据设计方面,有两个关键问题。如何组织数据以及在哪里存储数据?
在本教程中,我们将尝试回答它们。
2. 每个服务的数据库
使用微服务体系结构时,有两个主要选项可用于组织数据库:
- 每个服务的数据库
- 共享数据库
在本节中,我们将介绍第一个。
2.1. 基础知识
根据定义,微服务在开发和部署方面应该是松散耦合、可扩展和独立的。因此,每个服务的数据库是首选方法,因为它完全满足这些要求。让我们看看它的外观:
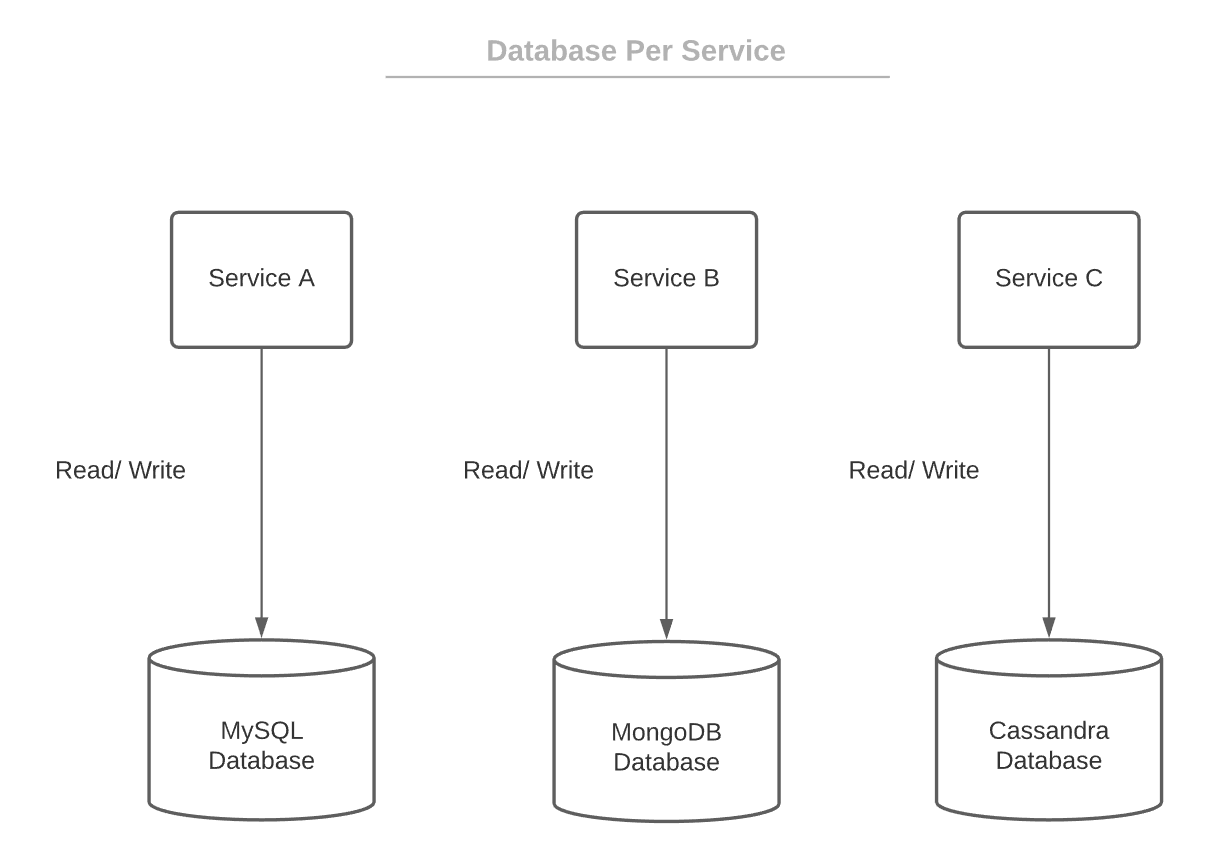
这个想法很简单。每个微服务都有自己的数据存储(整个架构或表)。其他服务无法访问它们不拥有的数据存储。这样的解决方案带来了很多好处。
首先,对单个数据库的更改不会影响其他服务。因此,应用程序中不存在单点故障。可以这么说,该应用程序更具弹性。
其次,单个数据存储更易于扩展。此外,域的数据封装在微服务中。因此,从整体上理解服务及其数据更容易。这对于开发团队的新成员尤其重要。他们将花费更少的时间和精力来完全了解他们负责的领域。
最后,对于每个服务的数据库,我们能够使用多语言持久性。这意味着我们可以对不同的微服务使用不同的数据库技术。因此,一个服务可能使用 SQL 数据库,另一个服务使用NoSQL数据库。该功能允许根据服务要求和功能使用最有效的数据库。
2.2. 缺点
尽管有所有这些好处,但每个服务方法的数据库也存在一些严重的缺点和挑战。如前所述,每个微服务只能直接访问自己的数据存储。因此,服务需要一种通信方法来交换数据。因此,每个服务都必须提供清晰的 API。
因此,需要一种故障保护机制,以防通信失败。假设我们将付款请求从服务 A 发送到服务 B。服务 A 等待响应以根据结果执行适当的操作。在此期间,服务 B 将脱机。我们需要处理这种情况,并在 B 重新联机时通知服务 A 结果。断路器机制可以在这里提供帮助。
下一个重要问题是交易。跨微服务跨越事务可能会对一致性和原子性产生负面影响。类似的缺点与复杂查询有关。没有一种简单的方法可以在多个数据存储上执行联接查询。
最后,如果出现任何问题,跨微服务的数据相关操作可能难以调试。
3. 共享数据库
共享数据库被视为反模式。虽然,这是值得商榷的。关键是,使用共享数据库时,微服务会失去其核心属性:可伸缩性、弹性和独立性。因此,共享数据库很少与微服务一起使用。
当共享数据库似乎是微服务项目的最佳选择时,我们应该重新考虑是否真的需要微服务。也许巨石会是更好的选择。让我们看看共享数据库方法是什么样子的:
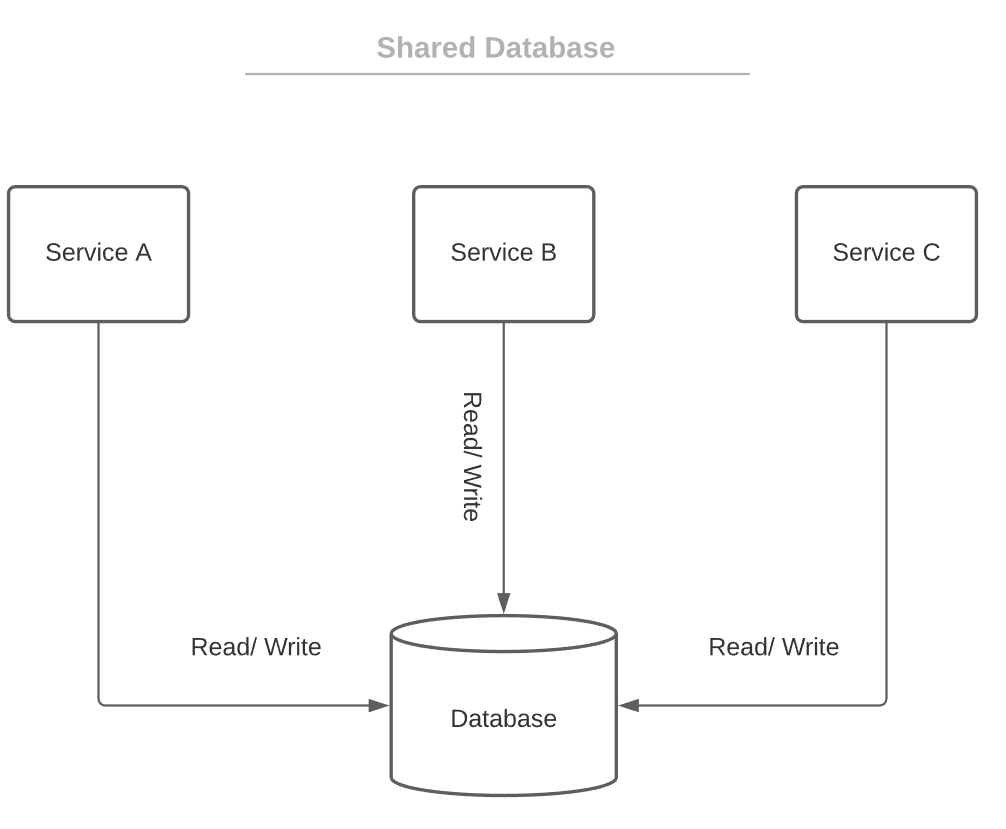
将共享数据库与微服务一起使用的用例并不常见。例如,将整体架构迁移到微服务时的临时状态。共享数据库相对于每个服务的主要优点是事务管理。无需跨越服务上的事务。
此外,数据完全受限,并保留适当的辐射。随后,冗余减少。我们可以轻松地使用连接执行复杂的查询。
另一个重要的事情是无需在微服务之间交换存储的数据。因此,API 得到了简化,并且在通信失败的情况下数据和状态的一致性没有问题。不过也有一些严重的缺点。
具有共享数据库的微服务无法轻松扩展。更重要的是,数据库将是单点故障。与数据库相关的更改可能会影响多个服务。此外,微服务在开发和部署方面不会独立,因为它们连接到同一数据库并在同一数据库上运行。
在以下情况下可以考虑此模式:
- 应保留现有数据存储
- 不应更改现有数据层代码库
- 事务对应用程序至关重要
4. 数据相关模式
有多种模式可用于管理微服务体系结构中的数据。在本节中,我们将简要介绍基本内容。
4.1. Saga模式
我们之前提到过,跨微服务的事务可能会有问题。简单来说,只有当所有相关服务都成功执行自己的部分时,事务才会成功。如果一个服务出现故障,整个事务应失败。此外,在这种情况下,已经尽其所能的服务应该回滚更改。
一般来说,这就是传奇模式的原因。Saga 模式是表示单个分布式事务的一系列本地事务。每个服务执行一个本地事务。如果本地事务成功结束,则会发布触发序列中下一个本地事务的事件或消息。如果发生故障,saga 会提供回滚更改的补偿事务。
有两种类型的实现 saga 模式:
- 编排 – 中央控制器(编排器)管理微服务之间的所有交互
- 编舞 – 广播活动的分散技术
4.2. CQRS
CQRS(命令查询责任分离)有助于实现另一个重要功能:从多个数据存储查询相关数据。此外,它通过分离关注点来简化业务逻辑的复杂性。此外,它还有助于微服务的可伸缩性。
这个想法很简单。我们将数据层与业务逻辑层分开。此外,类只能写入数据库(命令)或从中读取(查询)。因此,单个类不能同时做到这两点。这种方法带来了许多好处。代码更清晰,更易于维护或扩展。不同的组件可以单独优化、开发,尤其重要的是,可以扩展。
随后,组件松散耦合,工作可以在开发人员或团队之间有效地分配。最后,划分为组件的应用程序更易于测试。没有一种正确的方法来实现CQRS模式。实现可以基于领域、需求、框架、项目的实际状态等。CQRS 通常与事件溯源模式一起使用。让我们描述一下那个。
4.3. 事件溯源
许多现代应用程序出于各种目的依赖于事件。例如,如前所述,saga 序列中的服务以原子方式更新数据库并发布事件或消息。事件溯源利用应用程序事件。
事件溯源是一种通过持久化状态更改事件来表示状态的技术。每次业务实体更改时,事件都会保留在事件存储中。
顾名思义,事件站点是事件的数据库。它可以是SQL,NoSQL或任何其他适合项目的方式。此外,事件存储可以充当消息代理。所有感兴趣的组件都订阅它。持久保存事件时,事件存储会将信息传递给所有订阅者。发布事件是单个原子操作。因此,它提供了跨微服务的数据库操作的可靠性和原子性。
此外,它还会创建一个完整的审核日志。如果出现任何问题或错误,可以轻松研究状态更改并最终恢复有效状态。因此,调试不太复杂。此外,事件溯源可以避免面向对象数据和关系数据之间的阻抗不匹配。总而言之,事件溯源在微服务架构或任何事件驱动的应用程序中都有很大的帮助。
5. 如何选择数据库?
在微服务中规划数据库设计的第一步是选择模型。我们已经提到了每个服务的数据库和共享数据库模型。此外,我们还考虑了它们的优缺点和常见用例。
第二步是选择对项目或服务最有效的特定数据库技术(或技术)。为此,我们需要考虑一些属性。
第一个重要参数是读取性能。读取性能可以是每秒的操作数或提取查询的速度。与电子商务,CRM,银行软件相关的应用程序或服务通常包含需要快速,经常获取数据的功能。
第二个重要属性是写入性能。它与前一个相似。只是,在这种情况下,我们是在写入数据库,而不是从中读取。如果服务需要保留大量数据,甚至存储大型 blob,这可能是一个核心参数。
下一个是延迟。这是用户操作和服务器响应之间的延迟。这在与用户体验相关的组件中尤其重要。很好的例子是实时流媒体应用程序或实时游戏。
另一个重要属性是资源效率。通常,消耗的资源越少越好。这可能会导致更快的执行速度、减少主机负载和最终成本,具体取决于平台。
最后但并非最不重要的一点是,我们应该考虑配置效率。通常,它是数据库如何影响微服务的开发、部署和测试。正如我们之前已经提到的,微服务在这些方面的独立性非常重要。
5.1.SQL vs. NoSQL
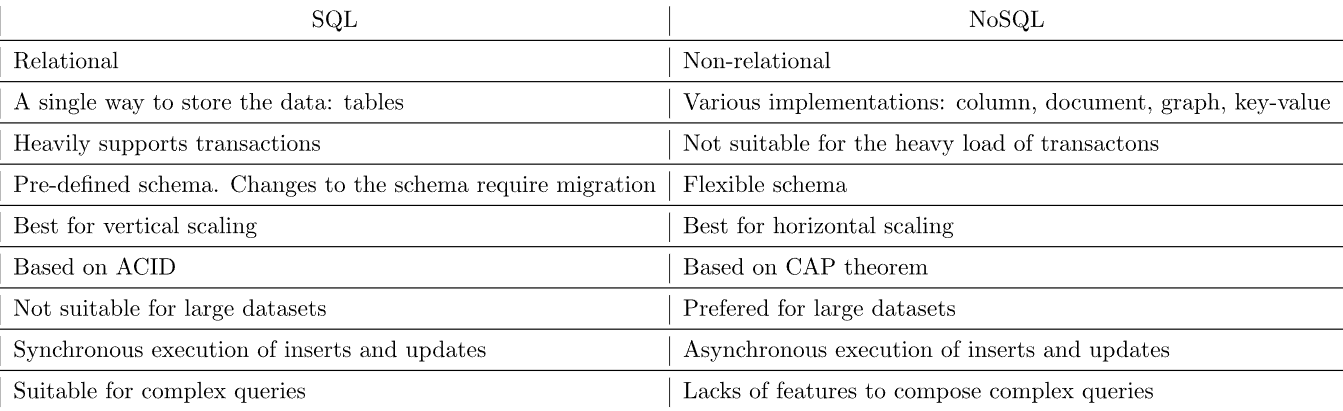
大多数情况下,项目或服务会考虑两种技术:SQL 和 NoSQL。基本上,它更复杂,特别是当涉及到NoSQL时。有各种各样的NoSQL数据库实现,即。虽然,在本文中,我们不会详细说明数据库的低级实现。让我们比较一下SQL和NoSQL。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号