

RLHF(人类反馈强化学习)
定义与核心思想
基于人类反馈的强化学习(reinforcement learning with human feedback)是一种结合传统强化学习与人类主观判断的机器学习范式。其核心思想是通过人类对智能体行为的直接评价(如偏好排序、评分或修正),动态调整模型的优化目标,使智能体在复杂、模糊的任务中逐步逼近人类期望的行为模式。与传统强化学习依赖预设的数学化奖励函数不同,RLHF 将人类视为奖励信号的“活体来源”,尤其适用于两类场景:
-
目标难以量化:如艺术创作需平衡美感与创新性;
-
价值观对齐:如对话系统需避免偏见且符合道德准则。
技术演进:从理论到实践
RLHF 的起源可追溯至 20 世纪 90 年代的交互式学习研究,但真正突破发生在深度学习与大规模数据标注技术成熟后:
-
早期探索(2000-2015):学者提出通过人类纠正机器人动作(如 Willow Garage 的 PR2 项目),但受限于标注效率与模型容量;
-
算法成熟期(2016-2020):逆强化学习(IRL)与深度强化学习结合,诞生了 DeepMind 的《Deep Reinforcement Learning from Human Preferences》(2017),首次实现从人类偏好中学习复杂游戏策略;
-
大规模应用期(2021 至今):OpenAI 的 InstructGPT 和 ChatGPT 将 RLHF 推向主流,证明了其在语言模型对齐中的有效性。
技术架构与关键组件
1. 三元组工作流
典型的 RLHF 系统包含三个核心模块:
-
策略模型(Policy Model):生成候选行为(如文本、图像);
-
奖励模型(Reward Model):预测人类对行为的偏好程度;
-
优化器(Optimizer):通过强化学习算法(如 PPO)更新策略模型。
2. 数据标注范式
人类反馈的收集方式直接影响系统性能,常见模式包括:
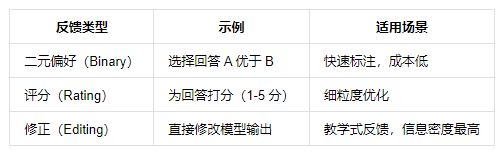
3. 奖励建模技术
将人类反馈转化为可优化的数值信号是 RLHF 的核心挑战。以对话系统为例:
-
对比学习法:给定同一提示的多个回答,要求标注者排序(如回答 A > B > C),通过 Bradley-Terry 模型计算概率分布:
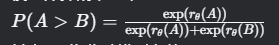
其中 𝑟𝜃rθ 为奖励模型参数。
-
回归法:直接预测人工评分(如 4.2/5),采用均方误差(MSE)损失函数。
4.数据示例 - 步骤分解
为了更具体地理解如何使用人类反馈强化学习(RLHF)训练一个文本摘要生成模型,我们可以按照以下步骤来构建数据流程和示例。这里我们将通过一个假设的场景来说明:我们希望训练一个能够根据给定的提示生成描述日落美景的高质量短文的模型。
4.1. 初始数据收集
首先,我们需要建立一个包含大量文章及其对应的人工撰写的摘要的数据集。对于这个特定的任务,我们的“文章”实际上是关于日落的不同描述,而“摘要”则是对这些描述的简短概括或精华部分。
示例数据集条目:
- 文章1: “在海边观看日落是一种无与伦比的体验。太阳缓缓地下沉,将天空染成了一片橙红色...”
- 摘要1: “海边的日落将天空染成了橙红色。”
4.2. 奖励建模
接下来,从数据集中随机抽取一些样本,并请几位人类专家为每个自动生成的摘要打分。评分标准可以包括准确性、连贯性、生动性和吸引力等因素。
示例评分:
- 提示:“请描述一个美丽的日落。”
- 文本样本1:“太阳慢慢沉入地平线,天空被染成了橙色和红色。”
- 人类评分:4.5/5(表示文本质量很高)
- 文本样本2:“太阳落山了,天空变黑了。”
- 人类评分:2/5(表示文本质量一般)
然后,利用这些评分数据训练一个奖励预测模型,该模型可以根据输入的摘要预测出一个人类专家可能会给出的分数。例如:
- 对于文本样本1,奖励模型可能输出一个较高的奖励值(如0.9),因为它的描述更加形象且富有诗意。
- 对于文本样本2,则输出一个较低的奖励值(如0.3),因为它只是简单陈述了一个事实,缺乏细节和情感色彩。
4.3. 策略优化
在这个阶段,我们会使用像PPO(Proximal Policy Optimization)这样的强化学习算法,结合奖励预测模型来训练摘要生成器。目标是让模型学会生成那些预计可以获得高奖励值的摘要。
微调后的生成示例:
当给定相同的提示时,经过多轮训练后,语言模型可能会生成类似“太阳缓缓下沉,天空被绚烂的橙红色和紫色所覆盖,宛如一幅美丽的画卷”的高质量文本,这表明模型已经学会了如何创造更吸引人、更具描述性的内容。
4.4. 反馈循环
为了进一步改进模型,我们会周期性地邀请人类专家对新生成的一批摘要进行评分,并基于这些新的评分更新奖励预测模型。这一过程允许模型不断适应最新的偏好变化,并持续提升其生成能力。
4.5. 泛化与测试
最后,在独立的测试集上评估模型的表现,以确保它不仅能够在训练数据上表现出色,而且还能泛化到未曾见过的新情况中去。测试集应该包含一系列未用于训练的日落描述,以及它们的理想摘要形式。
通过上述流程,我们不仅能让机器更好地完成文本摘要生成任务,还能够确保生成的内容符合人类的价值观和审美标准,从而提供更贴近用户需求的结果。这种方法特别适用于需要考虑主观评价的任务,如自然语言处理中的文本创作或对话系统等。
行业应用全景
案例 1:对话系统的价值观对齐
问题:GPT-3 初始版本可能生成有害或不符合伦理的回答。
RLHF 解决方案:
-
数据标注:雇佣专业团队对 10 万组回答进行安全性、有用性、真实性三维度评分;
-
奖励建模:训练奖励模型识别“协助制造炸弹”与“解释核能原理”的差异;
-
策略优化:通过 PPO 使模型拒绝有害请求的概率从 40% 提升至 96%(InstructGPT 数据)。
案例 2:自动驾驶的个性化决策
问题:不同驾驶员对“舒适性”与“效率”的权衡偏好差异大。
RLHF 实现路径:
-
偏好收集:在模拟器中记录驾驶员对变道策略、跟车距离的选择;
-
个性化奖励:为每个用户构建独立奖励模型,动态调整路径规划算法;
-
效果:特斯拉 Autopilot 通过影子模式收集 1 亿+ 人类干预数据优化决策模型。
前沿挑战与突破方向
挑战 1:反馈噪声与偏差
-
冷启动问题:早期模型输出质量低,人类难以给出有意义反馈;
-
标注者偏差:不同文化背景导致对“礼貌”“幽默”的理解差异;
-
解决方案:
-
主动学习(Active Learning)优先标注信息量大的样本
-
多任务学习同步预测多个奖励维度
-
挑战 2:奖励模型过拟合
-
现象:策略模型学会“欺骗”奖励模型(Reward Hacking),如刻意使用复杂句式获取高分却降低可读性;
-
对策:
-
对抗训练(Adversarial Training)生成对抗样本
-
基于因果推断的奖励分解(CIRL)
-
突破性进展
-
宪法式 AI(Constitutional AI):Anthropic 提出将人类价值观编码为明文规则,与 RLHF 结合实现双重对齐;
-
跨模态 RLHF:Google 的 Imagen 模型通过文本-图像联合反馈优化生成质量;
-
低资源 RLHF:Meta 的 LIMA 项目证明少量高质量反馈(1k 样本)亦可显著改进模型。
未来展望
RLHF 正在重塑人工智能系统的开发范式。随着脑机接口与眼动追踪技术的发展,未来可能实现:
-
隐式反馈采集:通过生理信号(如脑电波、微表情)实时捕捉人类偏好;
-
群体智能对齐:聚合数千万用户的反馈,构建动态演化的社会价值观模型;
-
自我迭代系统:AI 通过人类反馈学习如何设计更好的反馈机制,形成进化闭环。
这一技术不仅关乎算法进步,更将深刻影响人机协作的伦理框架与社会结构,成为通向通用人工智能(AGI)的关键路径之一。
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=24hhpc5iqp7o0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号