
修正余弦相似度(Adjusted Cosine Similarity)
概述
修正余弦相似度(Adjusted Cosine Similarity)是一种在文本挖掘和信息检索中常用的相似度计算方法,它是对余弦相似度的一种改进。传统的余弦相似度在计算时,只考虑了向量中各个维度的数值,而没有考虑到可能的均值偏移(mean offset)。修正余弦相似度试图通过移除均值来修正这一点。
在修正余弦相似度中,我们首先计算每个文档(或向量)的均值,然后从每个维度的值中减去这个均值。这样做可以消除由于文档长度(或向量大小)差异导致的偏差。修正余弦相似度的计算公式如下:
详细解释
原理
修正余弦相似度是通过在用户评分数据中减去每个用户的评分平均值,再进行余弦相似度计算的方法。这种方法可以消除用户评分尺度不同的问题,使得不同用户之间的评分更具可比性。
计算公式
![]()
其中:
A 和 B 是两个文档(或向量)的向量表示。
Ai 和 Bi 分别是文档 A 和 B 在第 i 个维度上的值。
Aˉ 和 Bˉ 分别是文档 A 和 B 的所有维度值的均值。
通过从每个维度的值中减去均值,修正余弦相似度能够更好地捕捉文档之间的相似性,尤其是在文档长度差异较大的情况下。这种方法在文本挖掘、推荐系统、信息检索等领域得到了广泛应用。
特点
消除评分尺度差异:通过减去每个用户的评分平均值,修正余弦相似度能够消除用户评分尺度不同的问题,使得不同用户之间的评分更具可比性。
修正余弦相似度(Adjusted Cosine Similarity)的优缺点可以归纳如下:
优点:
-
修正偏置:修正余弦相似度通过从每个评分中减去用户的平均评分(或项目的平均评分),从而消除了用户评分偏置(bias)或项目评分偏置的影响。这使得它能够更准确地反映用户之间的真实兴趣相似性,或者项目之间的真实相关性。
-
改进传统余弦相似度:相对于传统的余弦相似度,修正余弦相似度考虑了评分偏置的问题,因此它能够在一定程度上解决传统余弦相似度在处理不同评分尺度或长度差异较大的数据时可能产生的不准确结果。
-
适应性强:修正余弦相似度不仅适用于推荐系统、电影或音乐评分网站等场景,还可以应用于其他需要计算相似度且需要考虑评分偏置或长度差异的领域,如文本相似度计算、信息检索等。
缺点:
-
计算复杂性:修正余弦相似度的计算相对于传统余弦相似度更为复杂,因为它需要计算每个用户(或项目)的平均评分,并在计算相似度时从每个评分中减去这个平均评分。这可能会增加计算的时间和资源消耗。
-
对数据的依赖性:修正余弦相似度的效果取决于数据的分布和特性。如果数据中存在大量的噪声或异常值,或者用户的评分行为不符合一般的偏置模式,那么修正余弦相似度可能无法取得理想的效果。
-
参数敏感性:在某些情况下,修正余弦相似度可能对参数的选择比较敏感。例如,在计算用户平均评分时,如果只考虑用户已经评分的项目,而不考虑用户未评分的项目,那么可能会导致对某些用户的评分偏置估计不准确。
-
可能不适用于所有场景:虽然修正余弦相似度在许多场景下都表现出色,但它并不适用于所有场景。在某些特定场景下,可能需要使用其他相似度计算方法或结合多种相似度计算方法来达到更好的效果。
修正余弦相似度通过修正偏置来提高相似度计算的准确性,但它也存在一些缺点,如计算复杂性、对数据的依赖性、参数敏感性和适用场景的限制等。因此,在选择是否使用修正余弦相似度时,需要根据具体的应用场景和数据特性进行综合考虑。
适应场景
修正余弦相似度(Adjusted Cosine Similarity)特别适用于那些需要考虑用户评分偏置(bias)或文档长度差异对相似度计算产生影响的场景。以下是几个具体的适用场景:
-
推荐系统:在推荐系统中,用户通常会对多个项目进行评分,但由于个人喜好或评分习惯的不同,用户的评分可能存在系统性的偏置。修正余弦相似度可以通过从评分中移除用户的平均评分来减少这种偏置的影响,从而更准确地计算用户之间的相似性,进而做出更精准的推荐。
-
电影或音乐评分网站:这些平台上的用户会对电影或音乐进行评分,但由于不同用户的评分尺度不同(有些人倾向于给出高分,而有些人则倾向于给出低分),直接使用原始的评分数据计算相似度可能会导致偏差。修正余弦相似度可以消除这种评分尺度的影响,更准确地衡量用户之间的兴趣相似性。
-
文本相似度计算:在文本处理中,虽然传统的余弦相似度可以用于计算文本之间的相似性,但当文本长度差异较大时,较长的文本可能会因为包含更多的信息而得到更高的相似度得分,即使它们之间的实际语义相似度并不高。修正余弦相似度通过考虑文本长度的差异,可以更准确地衡量文本之间的语义相似性。
-
信息检索:在信息检索领域,修正余弦相似度可以用于计算查询和文档之间的相似度。由于文档的长度和查询的长度通常差异很大,直接使用余弦相似度可能会导致不准确的结果。通过修正余弦相似度,可以消除这种长度差异的影响,提高检索的准确性。
使用数据一步步举例演示
使用数据一步步举例演示修正余弦相似度的计算,我们可以假设一个简化的用户评分场景。假设有两个用户A和B,他们各自对一系列电影进行了评分,评分范围为1到5。
首先,我们列出用户A和B的评分数据:
用户A的评分(电影ID: 评分):
电影1: 5 电影2: 3 电影3: 4 电影4: 5(未评分,计为0)
用户B的评分(电影ID: 评分):
电影1: 4 电影2: 3 电影3: 2 电影4: 5
注意:为了简化计算,我们假设只有前三部电影被两位用户都评分了,第四部电影只被用户B评分了。
步骤1:计算平均评分
用户A的平均评分:
![]()
用户B的平均评分:
![]()
步骤2:调整评分
从每位用户的每个评分中减去他们的平均评分:
用户A调整后的评分:
电影1: 5 - 4 = 1 电影2: 3 - 4 = -1 电影3: 4 - 4 = 0
用户B调整后的评分:
电影1: 4 - 3.5 = 0.5 电影2: 3 - 3.5 = -0.5 电影3: 2 - 3.5 = -1.5 电影4: 5 - 3.5 = 1.5 (虽然用户A未评分,但计算修正余弦相似度时仍需要包含)
步骤3:计算修正余弦相似度
修正余弦相似度的计算公式为:
![]()
其中,
![]() 、
、![]() 分别是用户A和用户B在第i个电影上的评分,
分别是用户A和用户B在第i个电影上的评分,![]() 、
、![]() 分别是用户A和用户B的平均评分。
分别是用户A和用户B的平均评分。
由于用户A没有给电影4评分,我们在计算时只考虑前三部电影。
计算分子(点积):
![]()
计算分母(用户A的调整评分的模长):
![]()
计算分母(用户B的调整评分的模长):
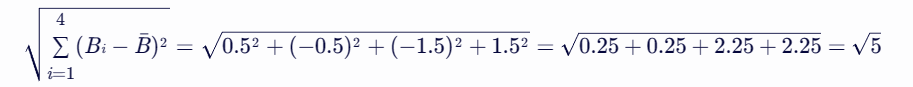
最后,计算修正余弦相似度:
![]()
这个值表示用户A和用户B在电影评分上的相似性程度,值越接近1表示越相似,越接近-1表示越不相似,接近0表示中性或没有相关性。在这个例子中,两位用户的修正余弦相似度约为0.316,表示他们有一定的相似性,但相似程度并不高。
java代码实现示例
在Java中实现修正余弦相似度的过程可以通过以下步骤来完成:
- 创建一个类来表示用户评分。
- 创建一个方法来计算用户的平均评分。
- 创建一个方法来调整用户的评分。
- 创建一个方法来计算修正余弦相似度。
下面是一个简单的Java代码示例,展示了如何实现这些步骤:
import java.util.HashMap;
import java.util.Map;
public class AdjustedCosineSimilarity {
// 用户评分表示为一个Map,其中键是电影ID,值是评分
private Map<Integer, Double> userRatings;
// 构造函数
public AdjustedCosineSimilarity(Map<Integer, Double> userRatings) {
this.userRatings = userRatings;
}
// 计算用户的平均评分
private double calculateAverageRating() {
double sum = 0.0;
int count = 0;
for (double rating : userRatings.values()) {
if (rating > 0) { // 忽略未评分的电影
sum += rating;
count++;
}
}
return sum / count;
}
// 调整用户的评分
private Map<Integer, Double> adjustRatings(double averageRating) {
Map<Integer, Double> adjustedRatings = new HashMap<>();
for (Map.Entry<Integer, Double> entry : userRatings.entrySet()) {
if (entry.getValue() > 0) { // 忽略未评分的电影
adjustedRatings.put(entry.getKey(), entry.getValue() - averageRating);
}
}
return adjustedRatings;
}
// 计算修正余弦相似度
public double calculateAdjustedCosineSimilarity(AdjustedCosineSimilarity otherUser) {
double averageRating1 = calculateAverageRating();
double averageRating2 = otherUser.calculateAverageRating();
Map<Integer, Double> adjustedRatings1 = adjustRatings(averageRating1);
Map<Integer, Double> adjustedRatings2 = otherUser.adjustRatings(averageRating2);
// 找到两位用户都评分的电影的交集
adjustedRatings1.keySet().retainAll(adjustedRatings2.keySet());
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0;
for (int movieId : adjustedRatings1.keySet()) {
double rating1 = adjustedRatings1.get(movieId);
double rating2 = adjustedRatings2.get(movieId);
dotProduct += rating1 * rating2;
norm1 += Math.pow(rating1, 2);
norm2 += Math.pow(rating2, 2);
}
if (norm1 == 0 || norm2 == 0) {
return 0.0; // 如果任一用户的评分为0,则相似度为0
}
return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
// 示例使用
public static void main(String[] args) {
Map<Integer, Double> userARatings = new HashMap<>();
userARatings.put(1, 5.0);
userARatings.put(2, 3.0);
userARatings.put(3, 4.0);
Map<Integer, Double> userBRatings = new HashMap<>();
userBRatings.put(1, 4.0);
userBRatings.put(2, 3.0);
userBRatings.put(3, 2.0);
userBRatings.put(4, 5.0); // 用户B评分的电影4对用户A来说没有评分
AdjustedCosineSimilarity userA = new AdjustedCosineSimilarity(userARatings);
AdjustedCosineSimilarity userB = new AdjustedCosineSimilarity(userBRatings);
double similarity = userA.calculateAdjustedCosineSimilarity(userB);
System.out.println("Adjusted Cosine Similarity between User A and User B: " + similarity);
}
}
这个示例中,AdjustedCosineSimilarity 类包含了计算平均评分、调整评分和计算修正余弦相似度的方法。在 main 方法中,我们创建了两个用户对象,并计算了他们之间的修正余弦相似度。这个计算仅考虑两个用户都评分的电影。
注意事项
总的来说,修正余弦相似度适用于那些需要准确计算相似度,并且需要考虑评分偏置或长度差异对相似度计算产生影响的场景。修正余弦相似度仍然是一种基于向量空间模型的相似度计算方法,它假设文档的语义可以由其包含的词汇(或特征)来表示。因此,在使用修正余弦相似度时,需要确保文档向量能够准确地表示文档的语义信息。
常见的相似度计算方法
余弦相似度(Cosine Similarity)
皮尔逊相关系数
曼哈顿距离(Manhattan Distance)
欧氏距离(Euclidean Distance)
Jaccard相似度
修正余弦相似度(Adjusted Cosine Similarity)
皮尔逊χ²检验(Pearson's Chi-squared Test)
互信息(Mutual Information, MI)
Tanimoto系数(Tanimoto Coefficient)
切比雪夫距离(Chebyshev Distance)
汉明距离(Hamming Distance)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号