
数据科学与机器学习-大数据及人工智能快速入门
在2010年大数据时代出现在数据空间行业之后,组织必须处理PB级和EB级的数据,因此,行业存储和管理数据变得非常困难。在Hadoop和其他人解决存储问题之后,重点现在转移到处理数据上,其中机器学习和深度学习发挥着重要作用。数据科学和机器学习的概念都属于技术范畴,可用于进一步创造和创新产品、服务、基础设施系统等。两者都是高收入和需求的职业,追求其中任何一个都是有益的。
数据科学是一门研究如何清理、准备和分析数据的学科。此外,机器学习被认为是人工智能的一个分支,同时也是数据科学的子领域。数据科学与机器学习密切相关,但它们具有不同的功能和目标。了解这两个流行语以及人工智能和深度学习彼此差异的重要性至关重要。具体来说,在本文中,我们将研究数据科学和机器学习之间的差异以及它们之间的关系。
什么是数据科学?

顾名思义,数据科学与数据收集和分析有关。因此,我们可以将其描述为“一个深入研究数据的领域,涉及从数据中提取有价值的见解并使用各种工具(如Jupyter,MATLAB,BigML,Apache Spark等),统计模型和机器学习算法(如线性回归,逻辑回归,决策树等)处理该信息,”维基百科。它是一个研究概念领域,用于管理大量数据,涉及数据清理、数据准备、数据分析和数据可视化。
数据科学家从各种来源收集原始数据,准备和预处理数据,然后使用机器学习算法和预测分析从收集和存储的数据中获得有价值的见解。
数据协同过滤,数据科学家使用的一种技术,用于根据从不同用户收集的数据自动预测用户的兴趣。例如,Netflix 使用此技术根据用户之前观看的内容和其他用户正在观看的内容为搜索结果提供更好的推荐。
数据科学家必须具备各种能力,例如:
- 编程语言的技能,如Python,R,SAS,Scala和其他编程语言。
- 在SQL,MongoDB和Cassandra等数据库方面的专业知识。
- 需要了解机器学习算法。
- 以及统计学、微积分和线性代数等数学主题。
- 需要数据挖掘、数据清理和可视化功能。
- 使用大数据技术的能力,如Hadoop,Apache Spark,Tensor Flow,Data Lakes等。
什么是机器学习?
在人工智能(AI)中,机器学习允许系统自动从数据中学习并自行预测发展,而无需事先明确设计。创建虚拟个人助理、GPS 导航服务、社交媒体服务、欺诈检测服务、聊天机器人等。是大量学习研究和开发的科目。
我们从观察或数据(例如示例,第一手经验或教学)开始学习过程,以识别数据中的模式,并根据我们给出的示例在未来做出更好的选择。主要目标是使计算机能够自己学习,而无需人类参与或帮助,并适当地修改其行为。
另一方面,在使用传统的机器学习算法时,文本被视为一系列关键字;另一方面,语义分析方法复制了人类理解文本含义的能力。
以下是机器学习工程师所需的技能:
- 理解机器学习算法并将其付诸行动是两项重要技能。
- 并对多元微积分、统计学、离散数学和线性代数等数学主题有很好的理解。
- 了解各种库和框架,如自然语言处理,TensorFlow,Sci-Kit Learn,Theano,Torch等。
- 需要出色的Python或R编程技能。
- 详细了解统计和概率原理
- 需要数据建模和数据评估技能。
数据科学家和机器学习所需的技能
数据科学领域侧重于研究数据并确定其含义,而机器学习领域侧重于理解和开发提高性能或预测机器行为的方法。机器学习属于人工智能的保护伞。
数据科学家和机器学习科学家所需的技能包括全面的数据分析知识和出色的编程能力。此外,他们根据业务需求使用各种技能。
使这个职业具有吸引力的能力可以分为两类:
技术能力:
要成为一名成功的数据科学家,您必须具有强大的数学、计算机科学和统计学背景。
所需的其他技术技能如下:
- 机器语言和编程语言以及其他编程语言方面的专业知识
- 了解分析工具 - SAS,Hadoop,Spark和R是数据科学家最常用的分析工具。
- 非结构化数据的可操作性 – 处理从各种来源收集的非结构化数据的能力。
非技术能力:
在大多数情况下,个人的技能被归类为技术或非技术。它们的名称如下:
- 首屈一指的商业头脑
- 与他人沟通的能力 关于数据的直觉
现在有必要讨论机器学习,以继续讨论数据科学和机器学习之间的差异。机器学习专家应该牢牢掌握几个基本概念和能力。让我们来看看你需要的一些最重要的能力。
概率与统计:
你的理论知识与你理解算法结构的能力有很大关系。隐马尔可夫模板、朴素贝叶斯和高斯混合只是机器学习技术的几个例子。如果你不熟悉数字和机会,理解这些算法结构并不容易。
数据评估和建模:
对于ML,定期评估不同模型的有效性以保持测量技术的可靠性至关重要。为了评估模型的不准确性或一致性,可以采用各种方法,例如回归和分类。您还需要一个评估策略来配合它。
机器学习算法的各个方面:
为了针对特定情况选择最佳的机器学习算法,了解不同的机器学习算法的工作原理至关重要。因此,在开始您的研究之前,请自行阅读偏微分方程、梯度下降、二次规划、凸优化和其他相关主题文章。
编程语言:
如果你想从事机器学习工作,你仍然需要知道如何用Java,R,Python和C++等语言进行编程。这些编程语言可用于在机器学习项目的不同阶段为您提供帮助。
信号处理技术:
特征提取过程对机器学习至关重要。在学习过程中,您将需要许多不同的信号处理方法,例如带状带、剪切带、轮廓和曲线。
数据科学和机器学习的区别
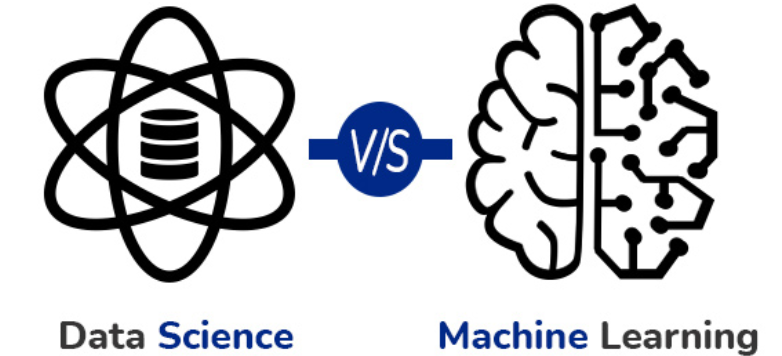
| 数据科学 | 机器学习 |
| 它关注破译和识别数据中隐藏的模式或有价值的见解,这些模式或见解可用于将来做出更明智的业务选择。 | 它是数据科学的一个分支,它自动允许计算机通过观察数据中的模式并做出决策来从数据中学习数据,而无需明确编程,并且它正变得越来越流行。 |
| 它用于从数据中提取见解。 | 为了对新数据点的结果进行预测和分类,有必要利用此功能。 |
| 在数据科学中,创建模型所涉及的主要步骤包括提取数据、清理数据、使用各种工具(如 Tableau、Micro Strategy)等。分析所涉及的基本模式,并使用监督学习、无监督学习等算法制作可行的模型,评估和部署模型。 | 在整个数据科学的背景下,创建机器学习模型涉及的主要步骤包括收集数据、可视化数据、使用各种机器学习模型(如逻辑回归、贝叶斯分类器、随机森林等)、训练数据集、评估数据集和参数调优。 |
| 数据科学家必须了解大数据技术的使用,如Hadoop,Hive和Pig,以及Python,R或Scala的统计和编程。 | 机器学习工程师要取得成功,需要具备计算机科学基础知识、Python 或 R 编程技能、统计和概率思想等能力。 |
| 它可以处理各种类型的数据,包括原始数据、结构化数据和非结构化数据。 | 机器学习主要依靠结构化数据来执行其功能。 |
| 数据科学家在管理数据、清理数据和识别数据中的模式方面投入了大量精力。 | ML 工程师投入了大量精力来处理算法实施过程中出现的复杂性以及支撑它们的数学思想。 |
| 数据科学的一个更通用的短语是“数据处理”,它不仅包括算法和统计数据,还包括数据的实际处理。 | 但是,它只关注算法统计。 |
| 这是一个通用词,可以指代各种领域。 | 它属于数据科学的范畴。 |
| 大量的数据科学活动,如数据收集、数据清洗、数据处理等。 | 无监督学习、强化学习和监督学习是三种学习。 |
| 例如,Netflix利用了数据科学技术。 | 例如,Facebook利用机器学习技术。 |
| Pokémon Go是一款使用数据科学和虚拟现实构建的游戏,使用Ingress中的数据,Ingress是同一家公司开发的先前应用程序,用于选择神奇宝贝的位置。 | Pinterest是一个用户上传内容的平台,它使用机器学习为用户提供准确的结果。 |
| DHL 和 FedEx 等物流公司使用数据科学通过计算合适的递送时间、最佳递送路线和选择具有成本效益的运输方式来优化递送流程。 | Twitter 使用机器学习算法,根据用户的个人兴趣和用户偏好,做出在用户时间线上显示推文的决定。 |
| 数据科学涉及许多操作,例如数据的收集、清理、操作和分析。 | 有三种类型的机器学习:无监督、强化和监督。 |
结论
数据科学是一个广泛的多学科领域,它使用可用的大量数据和计算能力来获得新的理解。机器学习是当前数据科学中最有趣的突破之一,它有可能彻底改变这个领域。机器学习是允许计算机根据提供的大量数据自行学习的过程。
这些系统具有广泛的应用,但它们的功能并非取之不尽,用之不竭。虽然数据科学有很多优点,但只有拥有训练有素的员工和高质量的数据,才能成功利用数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号