
数据结构基础面试题-2023面试题库
基本数据结构
1. 什么是数据结构?
数据结构是在程序中组织数据的一种机械或逻辑方式。数据的组织决定了程序的执行方式。有许多类型的数据结构,每种都有自己的用途。在设计代码时,我们需要特别注意数据的结构方式。如果数据存储效率不高或结构不正确,则代码的整体性能将降低。
2. 为什么要创建数据结构?
数据结构在程序中具有许多重要功能。它们确保每行代码正确有效地执行其功能,它们帮助程序员识别和修复他/她的代码问题,并帮助创建一个清晰和有组织的代码库。
3. 数据结构有哪些应用?
以下是数据结构的一些实时应用:
- 决策
- 遗传学
- 图像处理
- 区块链
- 数值和统计分析
- 编译器设计
- 数据库设计等等
4. 解释在内存中存储变量背后的过程。
- 变量根据所需的内存量存储在内存中。以下是存储变量所遵循的步骤:
- 首先分配所需的内存量。
- 然后,根据所使用的数据结构存储它。
- 使用动态分配等概念可确保高效率,并且可以根据需求实时访问存储单元。
5. 你能解释一下文件结构和存储结构之间的区别吗?
- 文件结构:将数据表示到辅助或辅助存储器中表示,任何设备(例如硬盘或笔式驱动器)存储的数据,这些数据在手动删除之前保持不变,称为文件结构表示。
- 存储结构:在这种类型中,数据存储在主存储器(即RAM)中,一旦使用此数据的功能完全执行,就会被删除。
不同之处在于存储结构将数据存储在计算机系统的内存中,而文件结构将数据存储在辅助存储器中。
6. 描述数据结构的类型?
- 线性数据结构:包含按顺序或线性排列的数据元素的数据结构称为线性数据结构,其中每个元素都连接到其上一个和下一个最近的元素。常用这类结构有数组、链表、栈、队列。
- 非线性数据结构:非线性数据结构是数据元素不线性或顺序排列的数据结构。我们不能像线性数据结构那样,在非线性数据结构中一次性遍历所有元素。常用这类结构有树、图形、表、集。
7. 什么是堆栈数据结构?堆栈有哪些应用?
堆栈是一种数据结构,用于表示应用程序在特定时间点的状态。堆栈由一系列项目组成,这些项目被添加到堆栈的顶部,然后从顶部删除。它是一种线性数据结构,遵循执行操作的特定顺序。LIFO(后进先出)或FILO(先进后出)是两种可能的顺序。堆栈由一系列项目组成。最后添加的元素将首先出现,现实生活中的例子可能是一叠(栈)衣服。
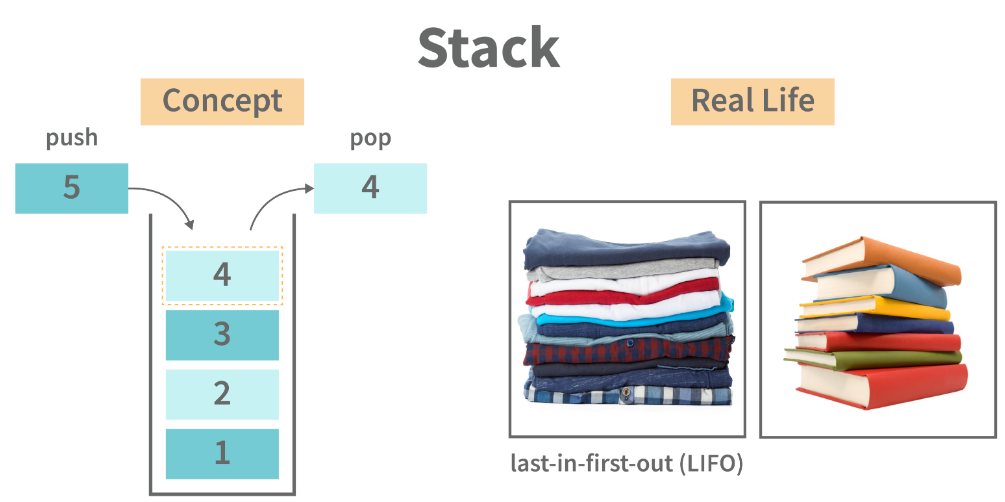
以下是堆栈数据结构的一些应用程序:
- 它在递归操作期间充当临时存储
- 文档编辑器中的重做和撤消操作
- 反转字符串
- 括号匹配
- 中缀表达式的后缀
- 函数调用顺序
8. 堆栈数据结构中有哪些不同的操作?
堆栈数据结构中提供的一些主要操作是:
- push:这会将项目添加到堆栈的顶部。如果堆栈已满,则会发生溢出情况。
- pop:这将删除堆栈的顶部项目。如果堆栈为空,则会出现下溢情况。
- top:这将返回堆栈中的顶部项。
- isEmpty:如果堆栈为空,则返回 true,否则返回 false。
- size:这将返回堆栈的大小。
9. 什么是队列数据结构?队列有哪些应用?
队列是一种线性数据结构,允许用户以系统的方式将项目存储在列表中。这些项目被添加到后端的队列中,直到它们已满,此时它们将从前面的队列中删除。队列通常用于用户希望长时间保留项目的情况,例如在结帐过程中。队列的一个很好的例子是资源的任何客户队列,其中第一个使用者首先得到服务。
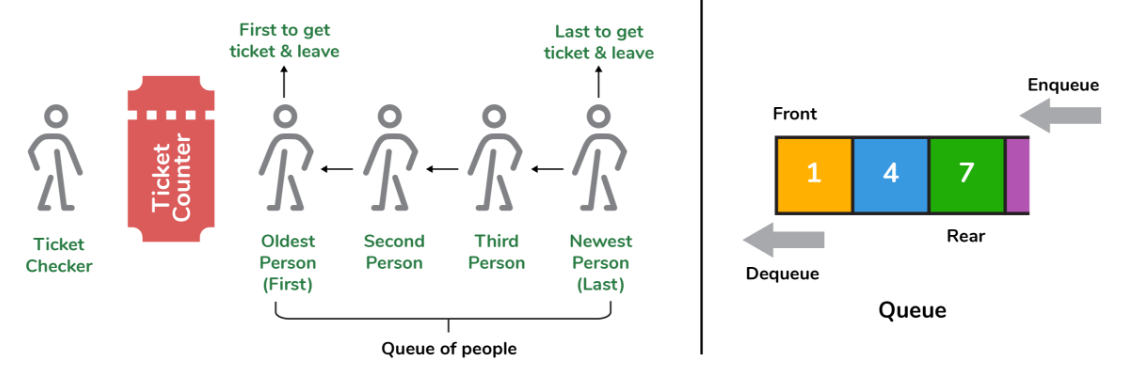
以下是队列数据结构的一些应用:
- 图中的广度优先搜索算法
- 操作系统:作业调度操作、磁盘调度、CPU调度等。
- 呼叫中心的呼叫管理
10. 队列数据结构中有哪些不同的操作?
- enqueue:这会将元素添加到队列的后端。如果队列已满,则会出现溢出情况。
- dequeue:这会从队列的前端删除元素。如果队列为空,则会出现下溢情况。
- isEmpty:如果队列为空,则返回 true,否则返回 false。
- rear:这将返回后端元素而不将其删除。
- front:这将返回前端元素而不删除它。
- size:这将返回队列的大小。
11. 区分堆栈和队列数据结构。

| 栈 | 队列 |
|---|---|
| 堆栈是一种线性数据结构,其中数据是从顶部添加和删除的。 | 队列是一种线性数据结构,其中数据在后端结束并从前端删除。 |
| 堆栈基于LIFO(后进先出)原则 | 队列基于FIFO(先进先出)原则 |
| 堆栈中的插入操作称为推送。 | 队列中的插入操作称为 eneque。 |
| 堆栈中的删除操作称为弹出。 | 队列中的删除操作称为取消排队。 |
| 只有一个指针可用于添加和删除:top() | 有两个指针可用于添加和删除:front() 和 rear() |
| 用于解决递归问题 | 用于解决顺序处理问题 |
12. 如何使用堆栈实现队列?
队列可以使用两个堆栈来实现。让我们成为队列,并成为实现的 2 个堆栈。我们知道堆栈支持推送、弹出和窥视操作,使用这些操作,我们需要模拟队列的操作 - 排队和取消排队。因此,队列可以用两种方法实现(两种方法都使用 O(n) 的辅助空间复杂度):qstack1stack2qq
1. 通过使排队操作成本高昂:
- 在这里,最旧的元素总是位于其顶部,确保取消排队操作以 O(1) 的时间复杂度发生。
stack1 - 要将元素放置在堆栈 1 的顶部,请使用堆栈 2。
- 伪代码:
- 排队:这里时间复杂度将为 O(n)
enqueue(q, data):
While stack1 is not empty:
Push everything from stack1 to stack2.
Push data to stack1
Push everything back to stack1.- 出列:这里时间复杂度为 O(1)
deQueue(q):
If stack1 is empty then error else
Pop an item from stack1 and return it2. 通过使取消排队操作的成本高昂:
- 在这里,对于排队操作,新元素被推到.此处,排队操作时间复杂度为 O(1)。
stack1 - 在取消排队中,如果为空,则所有元素都将移动到,并且顶部是结果。基本上,通过推送到堆栈并返回第一个排队的元素来反转列表。这种将所有元素推送到新堆栈的操作需要 O(n) 的复杂性。
stack2stack1stack2stack2 - 伪代码:
- 排队: 时间复杂度:O(1)
enqueue(q, data):
Push data to stack1- 出列: 时间复杂度:O(n)
dequeue(q):
If both stacks are empty then raise error.
If stack2 is empty:
While stack1 is not empty:
push everything from stack1 to stack2.
Pop the element from stack2 and return it.13. 如何使用队列实现堆栈?
- 一个堆栈可以使用两个队列来实现。我们知道队列支持排队和取消排队操作。使用这些操作,我们需要开发推送、弹出操作。
- 让堆栈为“s”,用于实现的队列为“q1”和“q2”。然后,堆栈's'可以通过两种方式实现:
1. 通过使推送操作成本高昂:
- 此方法可确保新输入的元素始终位于“q1”的前面,以便弹出操作只是从“q1”取消排队。
- “q2”用作辅助队列,将每个新元素放在“q1”前面,同时确保POP以O(1)复杂性发生。
- 伪代码:
- 将元素推送到堆栈:此处推送需要 O(n) 个时间复杂度。
push(s, data):
Enqueue data to q2
Dequeue elements one by one from q1 and enqueue to q2.
Swap the names of q1 and q2
- 堆栈 s 中的 pop 元素:需要 O(1) 时间复杂度。
pop(s):
dequeue from q1 and return it.2. 通过使流行操作成本高昂:
- 在推送操作中,元素排队到 q1。
- 在弹出操作中,如果 q1 为空,则 q2 中的所有元素(最后一个剩余元素除外)都将推送到 q1。q<> 剩余的最后一个元素被取消排队并返回。
- 伪代码:
- 将元素推送到堆栈 s:这里推送需要 O(1) 时间复杂度。
push(s,data):
Enqueue data to q1- 堆栈 s 中的 pop 元素:需要 O(n) 个时间复杂度。
pop(s):
Step1: Dequeue every elements except the last element from q1 and enqueue to q2.
Step2: Dequeue the last item of q1, the dequeued item is stored in result variable.
Step3: Swap the names of q1 and q2 (for getting updated data after dequeue)
Step4: Return the result.14. 什么是数组数据结构?阵列有哪些应用?
数组数据结构是一种数据结构,用于以高效且易于访问的方式存储数据。它类似于列表,因为它以序列存储数据。但是,数组数据结构与列表的不同之处在于,它可以容纳比列表更多的数据。数组数据结构是通过将多个数组组合在一起来创建的。然后为每个数组提供一个唯一标识符,并且每个数组的数据按其创建顺序存储。
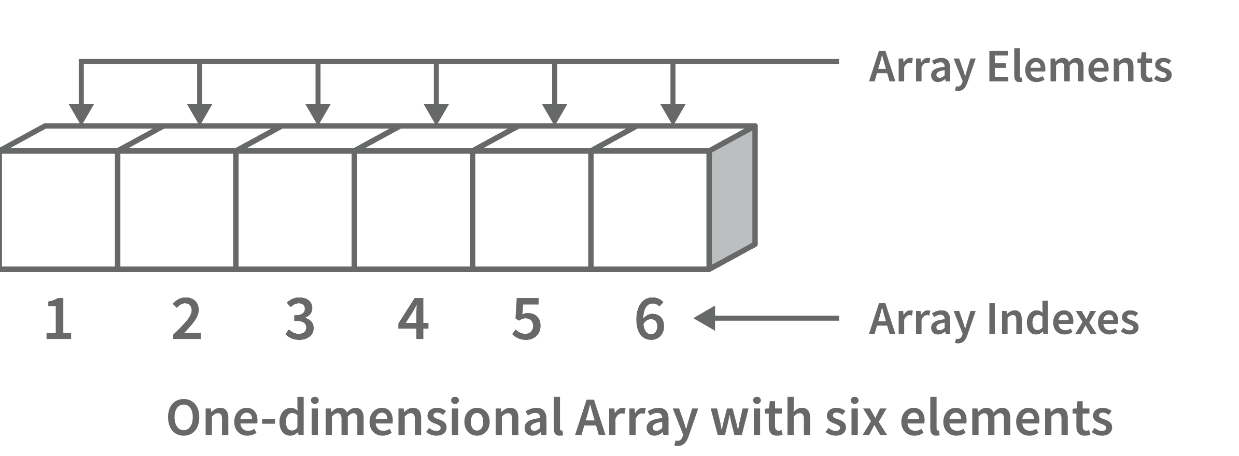
数组数据结构通常用于数据库和其他计算机系统,以有效地存储大量数据。它们对于存储经常访问的信息(如大量文本或图像)也很有用。
15. 阐述不同类型的数组数据结构
有几种不同类型的数组:
- 一维数组:一维数组将其元素存储在连续的内存位置,使用单个索引值访问它们。它是一种线性数据结构,保存序列中的所有元素。

-
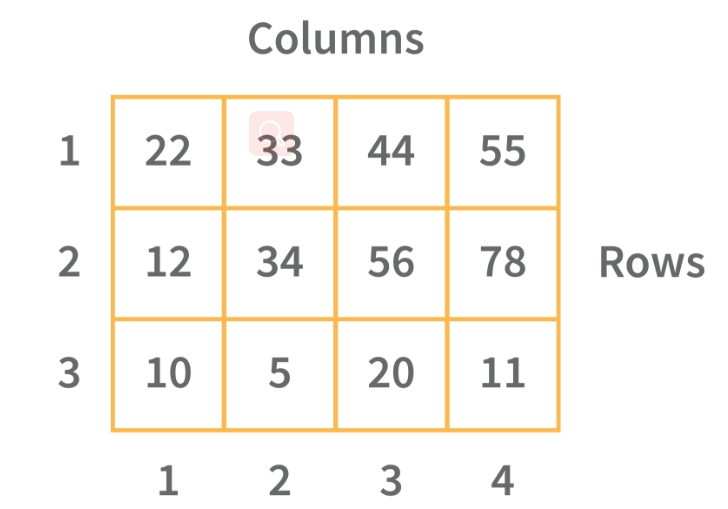
二维数组:二维数组是包含行和列并存储数据的表格数组。通过将 M 行和 N 列分组为 N 列和行来创建 M × N 个二维数组。
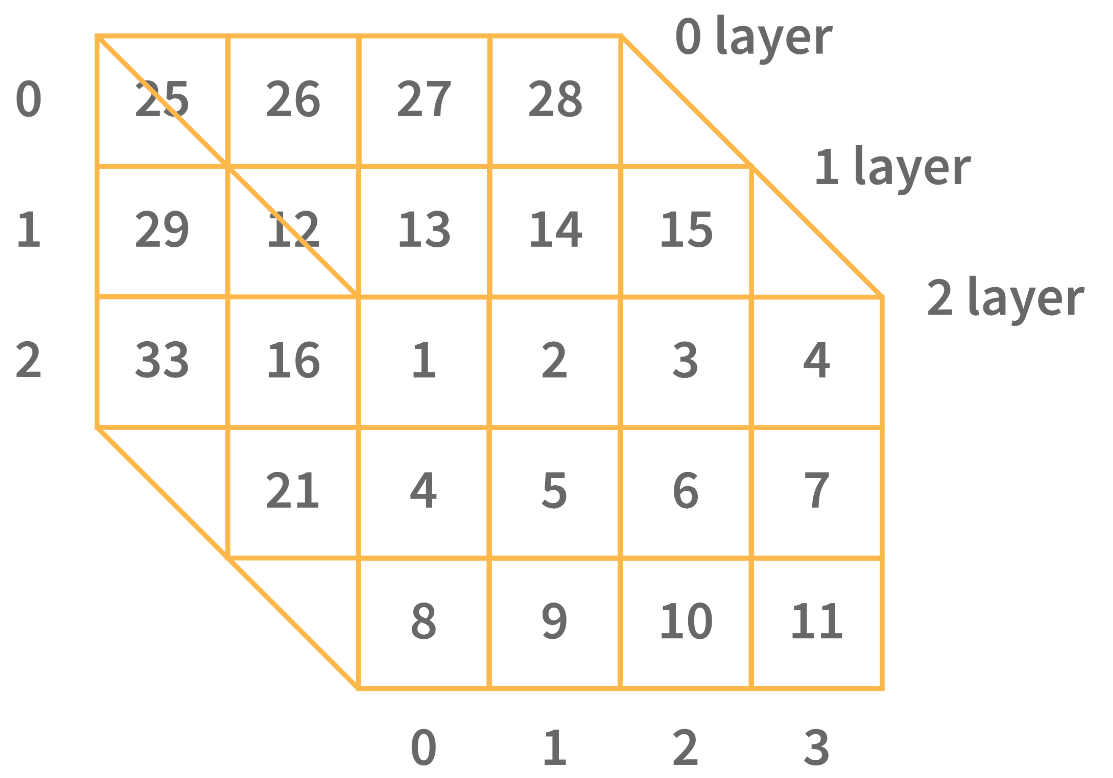
- 三维数组:三维数组是将行、列和深度作为第三维的网格。它包括一个具有行、列和深度作为第三维度的立方体。三维数组具有三个下标,分别表示特定行、列和深度中的位置。深度(维度或图层)是第一个索引,行索引是第二个索引,列索引是第三个索引。
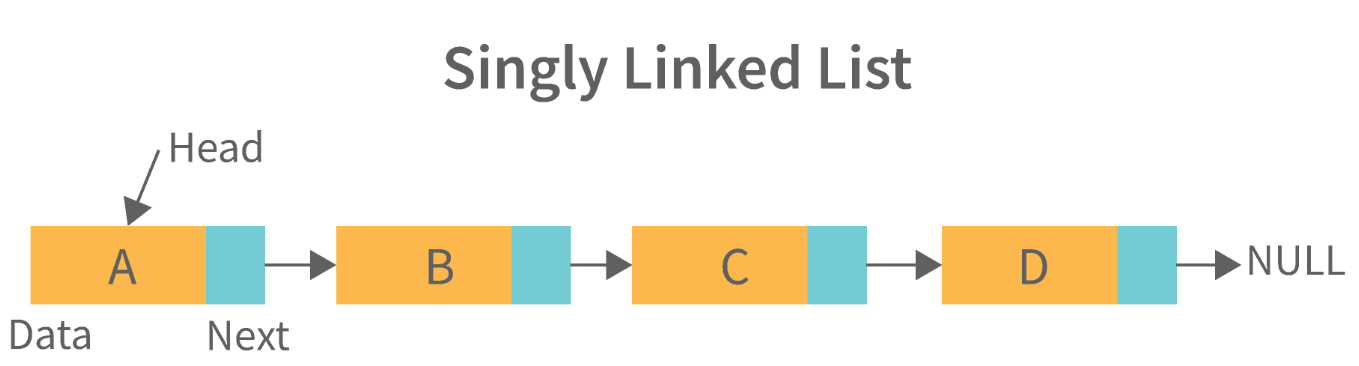
16. 什么是链表数据结构?链表有哪些应用?
链表可以被认为是一系列通过链接(或路径)连接的链接节点(或项目)。每个链接表示链表中的一个条目,每个条目指向序列中的下一个节点。节点添加到列表的顺序由节点的创建顺序决定。
以下是链表数据结构的一些应用:
- 堆栈、队列、二叉树和图形是使用链表实现的。
- 操作系统内存的动态管理。
- 操作系统任务的轮循机制计划。
- 浏览器中的前进和后退操作。
17. 详细说明不同类型的链表数据结构?
以下是不同类型的链表:
1. 单链表:单链表是一种用于存储多个项目的数据结构。这些项目使用密钥链接在一起。密钥用于标识项目,通常是唯一标识符。在单链表中,每个项目都存储在单独的节点中。节点可以是单个对象,也可以是对象的集合。将项目添加到列表时,将更新节点并将新项目添加到列表末尾。从列表中删除项目时,将删除包含已删除项目的节点,其位置将由另一个节点取代。单向链表的键可以是可用于标识对象的任何类型的数据结构。例如,它可以是一个整数、一个字符串,甚至是另一个单向链表。单向链表对于存储许多不同类型的数据非常有用。例如,它们通常用于存储诸如购物清单或患者记录之类的项目列表。它们对于存储对时间敏感的数据(如股票市场价格或航班时刻表)也很有用。
2. 双向链表:双向链表是一种数据结构,允许双向数据访问,使得列表中的每个节点都指向列表中的下一个节点,并指向其上一个节点。在双向链表中,每个节点都可以通过其地址访问,节点的内容可以通过其索引访问。它非常适合需要快速访问大量数据的应用程序。双向链表的一个缺点是它比单链表更难维护。此外,添加和删除节点比在单链表中更困难。

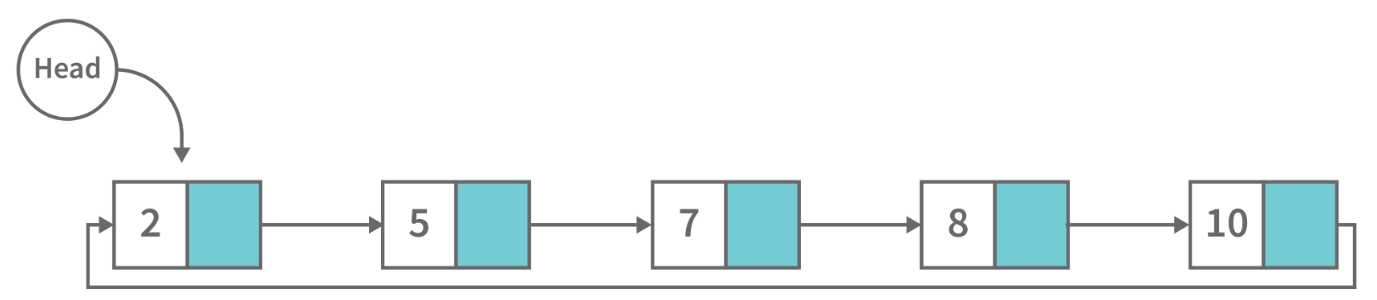
3. 循环链表:循环链表是一个单向链表,其中每个节点指向其下一个节点,最后一个节点指向第一个节点,这使得它成为循环的。
4. 双重循环链表:双循环链表是一种链表,其中每个节点指向其下一个节点及其前一个节点,最后一个节点指向第一个节点,第一个节点的先前指向最后一个节点。

5. 标头列表-Header List:在列表开头包含标头节点的列表,称为标头链接列表。这有助于计算一些重复操作,例如列表中的元素数量等。
18. 数组和链表的区别。
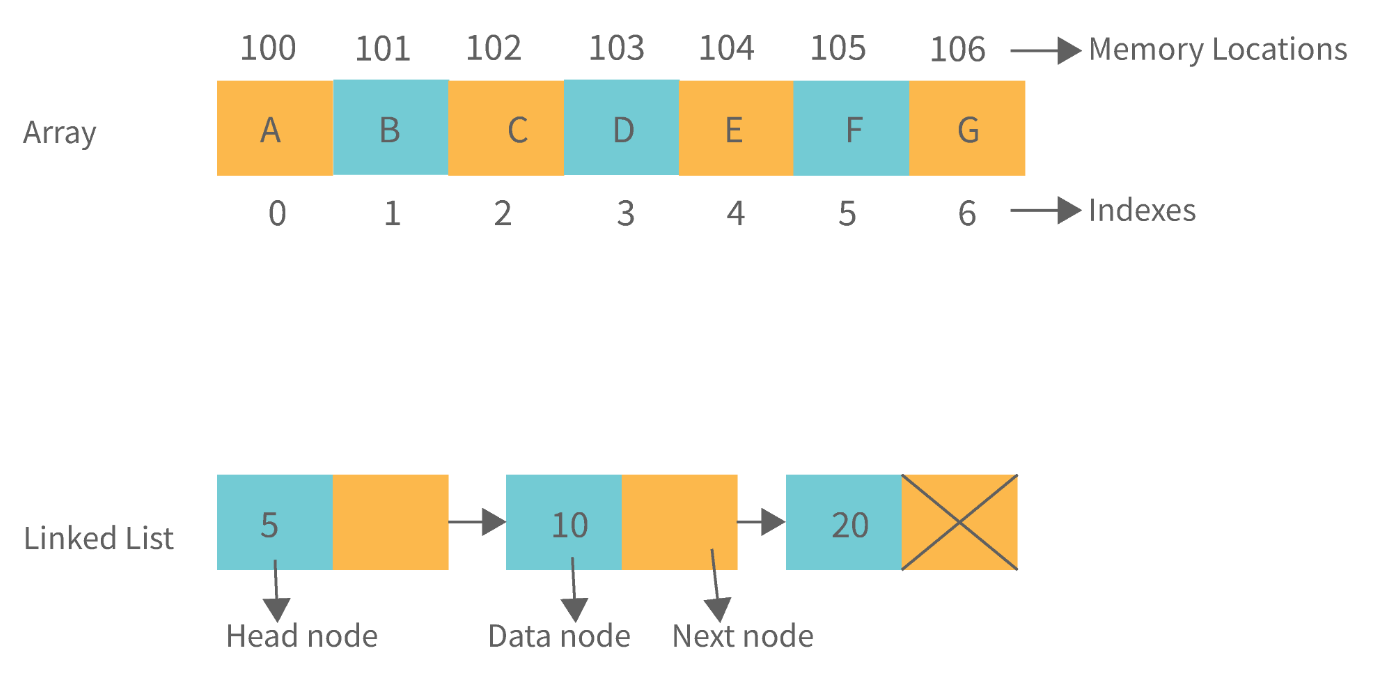
| 阵 列 | 链表 |
|---|---|
| 数组是相同类型的数据元素的集合。 | 链表是称为节点的实体集合。节点分为两部分:数据和地址。 |
| 它将数据元素保存在单个内存中。 | 它随机存储元素,或内存中的任何位置。 |
| 数组的内存大小是固定的,在运行时无法更改。 | 链表的内存大小在运行时分配。 |
| 数组的元素不相互依赖。 | 链表元素相互依赖。 |
| 访问数组中的元素更容易、更快捷。 | 在链表中,访问元素需要时间。 |
| 对于阵列,内存利用率无效。 | 对于链表,内存利用率是有效的。 |
| 插入和删除等操作在数组中需要更长的时间。 | 插入和删除等操作在链表中速度更快。 |
19. 什么是算法的渐近分析?
算法的渐近分析根据其数学边界定义运行时性能。渐近分析有助于我们阐明算法的最佳情况(Omega Notation,Ω),平均情况(Theta Notation,θ)和最坏情况(Big Oh Notation,Ο)性能。
20. 什么是数据结构中的哈希图?
Hashmap 是一种数据结构,它使用哈希表数据结构的实现,如果您有密钥,它允许以恒定时间 (O(1)) 复杂度访问数据。
21. 在HashMap中将对象用作键或值的要求是什么?
- 在哈希映射中使用的键或值对象必须实现和方法。
equals()hashcode() - 将键对象插入映射时使用哈希代码,尝试从映射中检索值时使用 equals 方法。
22. HashMap 如何处理 Java 中的冲突?
- Java 中的类使用链接方法来处理冲突。在链接中,如果尝试推送具有相同键的新值,则这些值将与现有值一起作为链存储在键的存储桶中的链表中。
java.util.HashMap - 在最坏的情况下,所有键可能具有相同的哈希代码,这将导致哈希表变成链表。在这种情况下,由于链表的性质,搜索值将花费 O(n) 的复杂性,而不是 O(1) 时间。因此,在选择哈希算法时必须小心。
23. HashMap 类中基本操作 get() 和 put() 的时间复杂度是多少?
假设哈希映射中使用的哈希函数在存储桶之间均匀分布元素情况下时间复杂度为 O(1)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号