
作业调度-史上最通俗易懂的Flink源代码深入分析教程
1.定义
Flink作业调度是将Flink作业提交到Flink集群上,并根据作业的执行计划和资源需求等信息对作业进行优化、调度和分配,从而实现高效、可靠的作业执行的过程
2.设计思路:
- 作业提交:Flink作业调度的第一步是将作业提交到集群上,提交方式可以通过命令行、Web界面或API等实现。
- 作业分析:在作业提交后,Flink会对作业进行分析,包括作业的执行计划、算子的依赖关系、资源需求等信息。
- 作业优化:Flink会根据作业的执行计划和资源需求等信息对作业进行优化,例如合并相邻的算子、优化任务并行度等,以提高作业的执行效率。
- 任务调度:Flink会根据作业的执行计划和资源需求等信息对任务进行调度,以便作业可以在Flink集群中高效执行。
- 资源分配:Flink会为每个任务分配所需的资源,包括CPU、内存、网络带宽等,以保证作业能够高效地执行。
- 故障恢复:Flink会根据作业的故障恢复策略,在出现故障时对作业进行恢复,例如任务重启、恢复到指定的检查点等,以保证作业的可靠性。
- 作业监控:Flink会对作业进行监控,包括任务的执行状态、作业的运行时间、数据量等信息,以便用户可以及时了解作业的执行情况。 总体而言,Flink作业调度的设计思路旨在提高作业的执行效率和可靠性,为Flink提供高性能、分布式的数据处理能力。
3.调度流程
Flink 通过 Task Slots 来定义执行资源。每个 TaskManager 有一到多个 task slot,每个 task slot 可以运行一条由多个并行 task 组成的流水线。 这样一条流水线由多个连续的 task 组成,比如并行度为 n 的 MapFunction 和 并行度为 n 的 ReduceFunction。需要注意的是 Flink 经常并发执行连续的 task,不仅在流式作业中到处都是,在批量作业中也很常见。
下图很好的阐释了这一点,一个由数据源、MapFunction 和 ReduceFunction 组成的 Flink 作业,其中数据源和 MapFunction 的并行度为 4 ,ReduceFunction 的并行度为 3 。流水线由一系列的 Source - Map - Reduce 组成,运行在 2 个 TaskManager 组成的集群上,每个 TaskManager 包含 3 个 slot,整个作业的运行如下图所示。
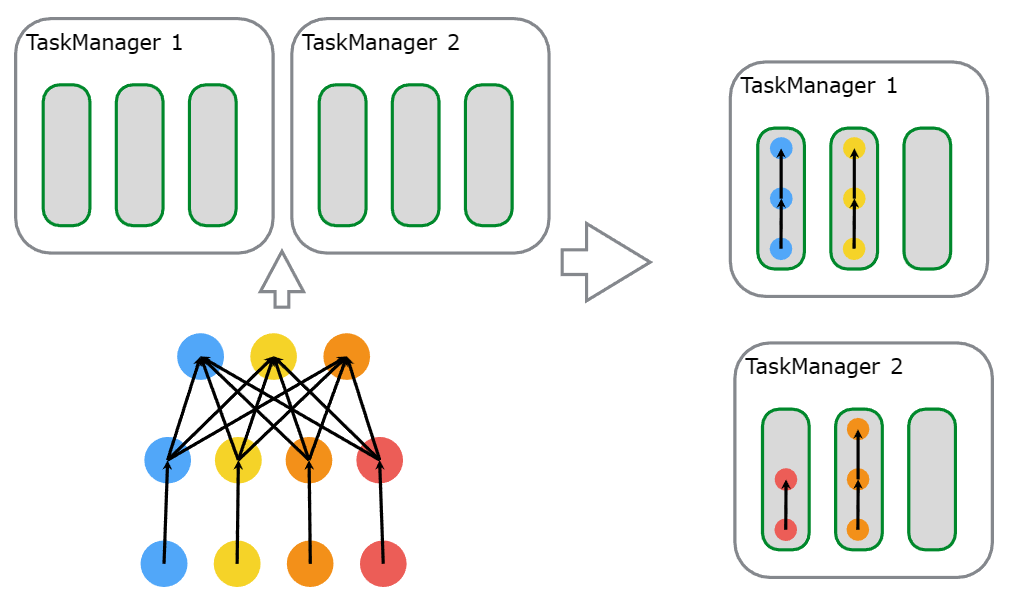
Flink 内部通过 SlotSharingGroup 和 CoLocationGroup 来定义哪些 task 可以共享一个 slot, 哪些 task 必须严格放到同一个 slot。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号