
ChatGPT与openai
ChatGPT是openai推荐的优化对话的语言模型,是openai使用来自人类反馈的强化学习(RLHF)训练了这个模型,使用与InstructGPT相同的方法,但在数据收集设置上略有不同。
1)使用监督微调训练了一个初始模型:人类人工智能训练师提供对话,他们在其中扮演双方——用户和人工智能助手。
2)让培训师可以访问模型编写的建议,以帮助他们撰写答案。
3)将这个新的对话数据集与 InstructGPT 数据集混合,并将其转换为对话格式。
4)为了创建强化学习的奖励模型,openai需要收集比较数据,其中包括两个或多个按质量排名的模型响应。为了收集这些数据,openai进行了人工智能培训师与聊天机器人的对话。openai随机选择了一个模型编写的消息,抽样了几个替代完成,并让AI培训师对它们进行排名。使用这些奖励模型,openai可以使用近端策略优化来微调模型。openai执行了此过程的多次迭代。
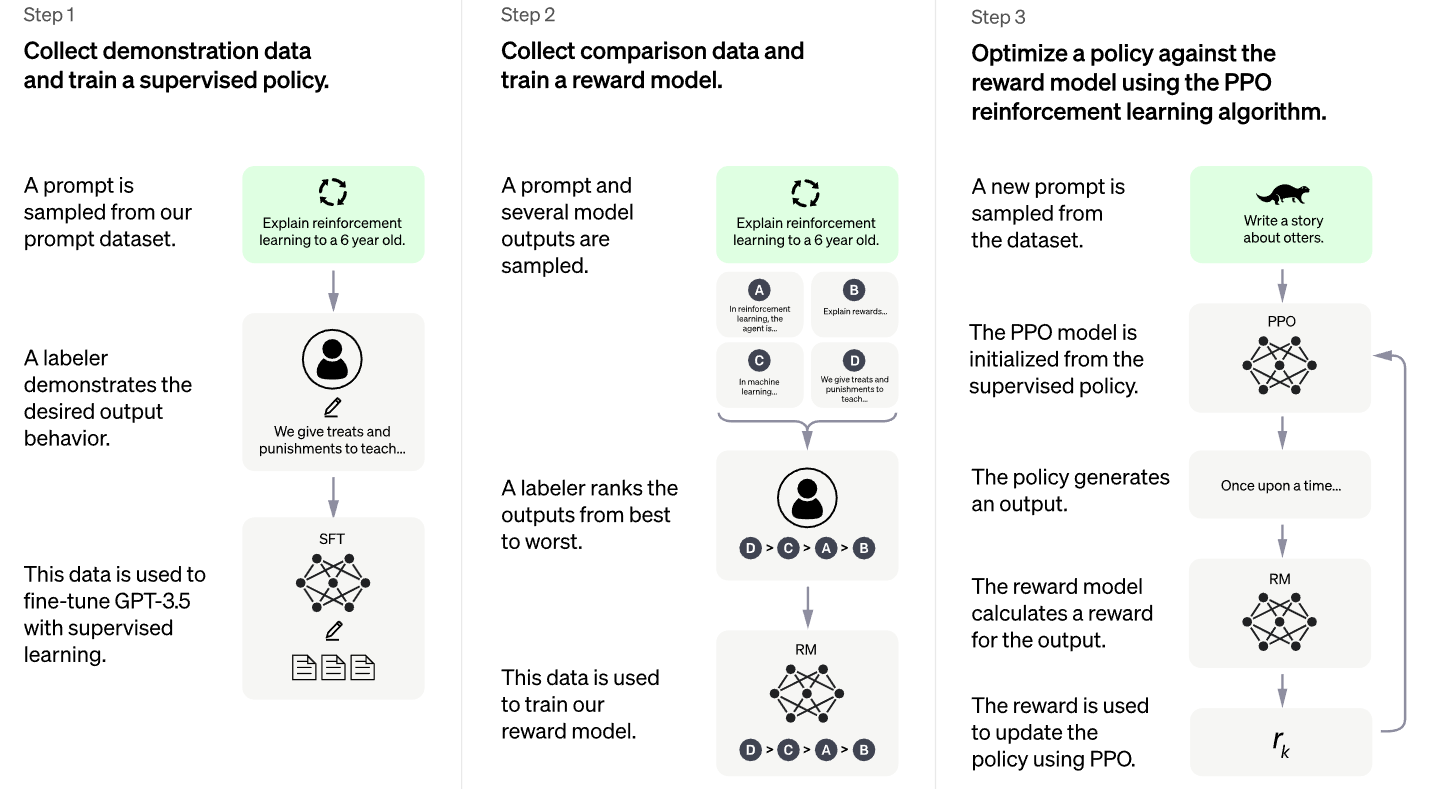
ChatGPT 是从 GPT-3.5 系列中的模型进行微调的,该模型于 2022 年初完成训练。您可以在此处了解有关 3.5 系列的更多信息。ChatGPT 和 GPT 3.5 在 Azure AI 超级计算基础架构上进行了训练。
局限性
- ChatGPT 有时会写出听起来似是而非但不正确或荒谬的答案。解决此问题具有挑战性,因为:(1) 在 RL 培训期间,目前没有事实来源;(2)训练模型更加谨慎,导致它拒绝可以正确回答的问题;(3)监督训练误导了模型,因为理想的答案取决于模型知道什么,而不是人类演示者知道什么。
- ChatGPT 对调整输入措辞或多次尝试相同的提示很敏感。例如,给定一个问题的措辞,模型可以声称不知道答案,但稍微改写一下,就可以正确回答。
- 该模型通常过于冗长,并且过度使用某些短语,例如重申它是由OpenAI训练的语言模型。这些问题源于训练数据中的偏差(培训师更喜欢看起来更全面的更长的答案)和众所周知的过度优化问题。12
- 理想情况下,当用户提供不明确的查询时,模型会提出澄清问题。相反,我们目前的模型通常会猜测用户的意图。
- 虽然我们努力使模型拒绝不适当的请求,但它有时会响应有害指令或表现出有偏见的行为。我们正在使用审核 API来警告或阻止某些类型的不安全内容,但我们希望它目前会出现一些漏报和误报。我们渴望收集用户反馈,以帮助我们正在进行的改进此系统的工作。
迭代部署
今天发布的ChatGPT研究版是OpenAI迭代部署越来越安全和有用的AI系统的最新一步。部署 GPT-3 和 Codex 等早期模型的许多经验教训为本次发布提供了安全缓解措施,包括通过使用人类反馈强化学习 (RLHF) 大幅减少有害和不真实的输出。
以下示例将 ChatGPT 与InstructGPT进行了比较,并演示了ChatGPT的安全缓解措施。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号