

线性回归与逻辑回归-AI快速进阶系列
1. 概述
在本教程中,我们将研究线性回归和逻辑回归之间的异同。
我们将首先研究回归的概念。通过这种方式,我们将看到回归与科学中的还原论方法的关系。
然后,我们将按顺序研究线性回归和逻辑回归。我们还将提出两种回归方法在特征向量和目标变量方面的形式化。
最后,我们将研究对可观察量执行回归的两种方法之间的主要区别。在本教程结束时,我们将了解我们更喜欢一种方法而不是另一种方法的条件。
2. 统计学回归的概念
2.1. 还原论和统计推断
在科学哲学中有一种观点,说世界遵循精确和数学性质的规则。这个想法与哲学和科学一样古老,可以追溯到毕达哥拉斯,他试图将世界的复杂性简化为数字之间的关系。在现代,这个想法被称为还原论,并表示试图提取将观察相互联系起来的规则和模式。
还原论下的隐含假设是,可以独立于整个更广泛的系统的整体行为来研究系统的子系统的行为:
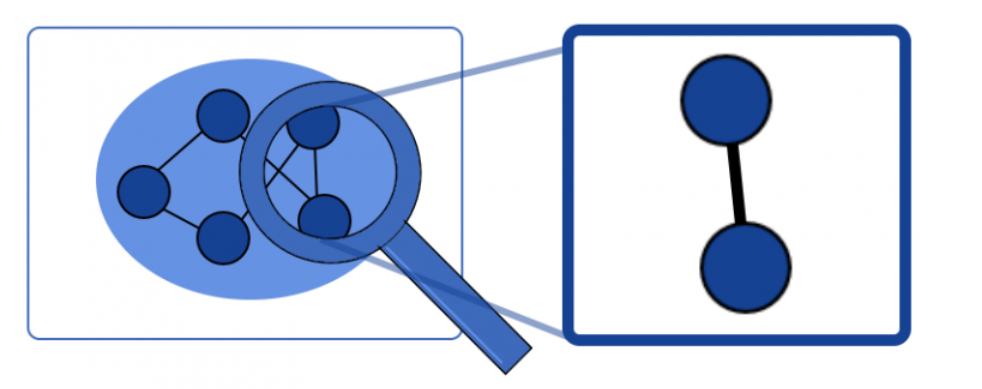
与还原论相反的观点被称为涌现和状态,相反,我们只能从整体上研究一个给定的系统。这意味着,无论我们在总结和独立分析系统组件的行为方面有多准确,我们都永远无法理解系统的整体:

还原论是一种强大的认识论工具,适用于药物发现、统计力学和生物学某些分支的研究应用。还原论不适合研究复杂系统,例如社会,用于知识推理的贝叶斯网络,生物学的其他分支。
我们可以在回归分析下的方法论下处理我们可以在还原论下构建的任何问题,但如果我们不能做后者,那么我们也不能做前者。
2.2. 什么是回归?
在讨论了回归分析的认识论先决条件之后,我们现在可以看到为什么我们这样称呼它了。回归这个词,就其一般意义而言,表示一个系统下降到比以前更简单的状态。由此,我们可以得到第一种直觉,即将回归定义为将系统的复杂性降低为更简单的形式。
第二种直觉可能来自于研究这个术语的起源,或者更确切地说是在统计分析中的第一次使用。在研究高个子家庭的身高时,高尔顿注意到,这些人的侄子通常都是平均身高,而不是更高。这导致了这样一种观点,即当给予足够的时间时,身高等变量倾向于向平均水平回归。
直到今天,回归分析是统计分析的一个适当的分支。这门学科关注的是从分布集合中提取简化关系的模型的研究。线性回归和逻辑回归,本教程的两个主题,就是回归分析的两个这样的模型。
2.3. 回归模型的组成部分
我们可以对任何两组或更多组变量进行回归分析,无论这些变量的分布方式如何。回归分析的变量必须包含相同数量的观测值,但可以具有任何大小或内容。也就是说,我们不仅限于对标量进行回归分析,但我们也可以使用有序变量或分类变量。
我们选择使用的特定类型的模型受到我们正在处理的变量类型的影响,我们将在后面看到。但无论如何,如果我们有两个或更多变量,回归分析总是可能的。
2.4. 因变量、自变量和误差
在这些变量中,有一个被称为因变量。我们假设所有其他变量都被称为“自变量”,自变量和因变量之间存在因果关系。或者至少我们怀疑这种关系的存在,我们想要验证我们的怀疑。
换句话说,如果y描述了一个因变量,而X是一个包含数据集特征的向量,我们假设这两者之间存在y = f(X)的关系。回归分析让我们检验这个假设是否正确。
我们也可以把这种关系想象成参数关系,也就是说它还依赖于x以外的项。在这种情况下,我们可以将这些项表示为 或A,并称它们为回归的“参数”。在这种情况下,函数f则采用y=f(X)的形式。
或A,并称它们为回归的“参数”。在这种情况下,函数f则采用y=f(X)的形式。
最后,我们还可以想象,我们从中得出y和X值的测量是有测量误差的。我们在关于神经网络偏差的文章中讨论了测量中的系统误差问题;但这里我们指的是随机错误,而不是系统错误。我们可以称这个误差为e,并认为它与我们观察到的变量无关。
2.5. 回归的一般模型
我们最终可以为我们在回归分析下研究的变量之间的关系构建一个基本模型。因此,我们可以定义:
- i,指的是数据集中的第 1 个观测值
- y,指的是因变量
- X,其中包含自变量
- a,其中包含模型的一组参数
- 最后,e指示与给定观测值相关的随机误差
根据这些定义,回归分析可以识别这样的函数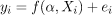 。
。
2.6. 回归极限
回归分析可以告诉我们两个或多个变量是否在数值上彼此相关。然而,它并没有说明我们假设它们之间存在的因果关系的有效性。简而言之,我们在进行回归分析之前就假设因果关系的假设。
如果我们找到一个好的回归模型,这有时是支持因果关系的证据。在这种情况下,我们可以说,也许我们研究的变量彼此有因果关系。
如果我们没有找到一个拟合良好的模型,我们通常假设它们之间不存在因果关系。然而,科学文献中充满了变量的例子,这些变量被认为是因果相关的,而实际上并非如此,反之亦然。
因此,牢记以下几点非常重要。对某些变量拥有良好的回归模型并不一定保证这两个变量具有因果关系。如果我们不牢记这一点,我们就有可能将因果关系分配给明显无关的现象:
3. 线性回归
3.1. 简单线性模型的公式
假设我们研究的两个变量x和y维数相等,即|x| = |y|。现在让我们假设x和y之间存在线性关系,这意味着存在两个参数a,b,使得y = ax + b。如果对于变量x中的任意元素xi,那么yi = axi + b,则这种关系是完全线性的。
我们可以通过说模型是线性的来形式化前面的陈述,如果:
![]()
请注意,如果a = 0,这意味着y=b独立于x的任何值,那么y=b是真还是假的问题与x无关,这意味着对于a = 0,我们不再讨论两个变量,而是只有一个变量。
因此,我们可以说,对于参数a=0,模型是未定义的,但对于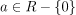 中a的所有其他值,模型是另有定义的。以下是线性模型的所有有效示例,其一个和b参数值不同:
中a的所有其他值,模型是另有定义的。以下是线性模型的所有有效示例,其一个和b参数值不同:
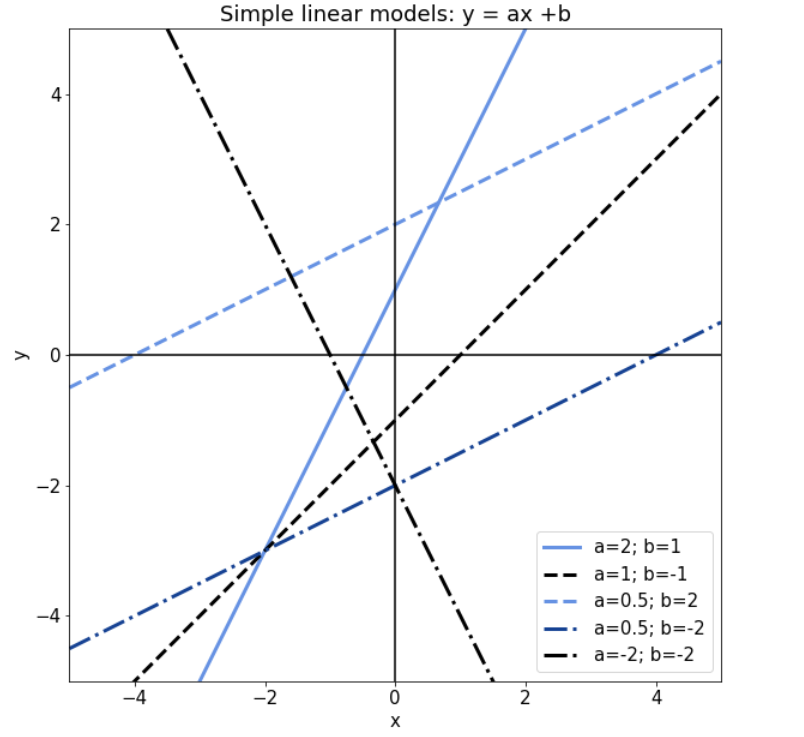
3.2. 从线性模型到线性回归
现在让我们假设这个模型并不完美。这意味着,如果我们计算给定xi的线性配对值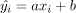 ,那么至少有一个xi满足
,那么至少有一个xi满足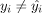 。
。
在这种情况下,我们可以计算出变量的观测值( )的和线性模型的预测(
)的和线性模型的预测(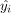 )间的差为
)间的差为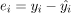 。
。
确定一个简单线性回归模型的问题在于确定一个线性函数的两个参数a, b,使得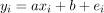 。附加的约束条件是,根据某种误差度量,我们希望误差项e尽可能小。
。附加的约束条件是,根据某种误差度量,我们希望误差项e尽可能小。
线性回归中使用的典型误差度量是误差平方和,计算方法如下:
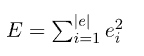
因此,确定两个变量x, y的线性回归模型的问题可以重新表述为寻找参数甲,乙,使误差平方和最小化。换句话说,问题变成了确定以下问题的解决方案:
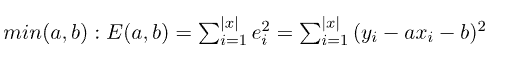
3.3. 计算线性回归的解
这个问题的解决方案很容易找到。我们可以先计算参数a,如:

其中 和
和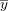 是变量x和y的平均值。在我们找到a之后,我们可以简单地将b标识为
是变量x和y的平均值。在我们找到a之后,我们可以简单地将b标识为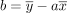 。我们由此计算的两个参数a,b对应于最小化平方误差总和的模型
。我们由此计算的两个参数a,b对应于最小化平方误差总和的模型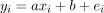
还有一个直观的理解,我们把两个参a,b分配给它们。考虑到它们是线性模型,在回归相关的线性模型中a,b分别指直线的斜率及其截距:
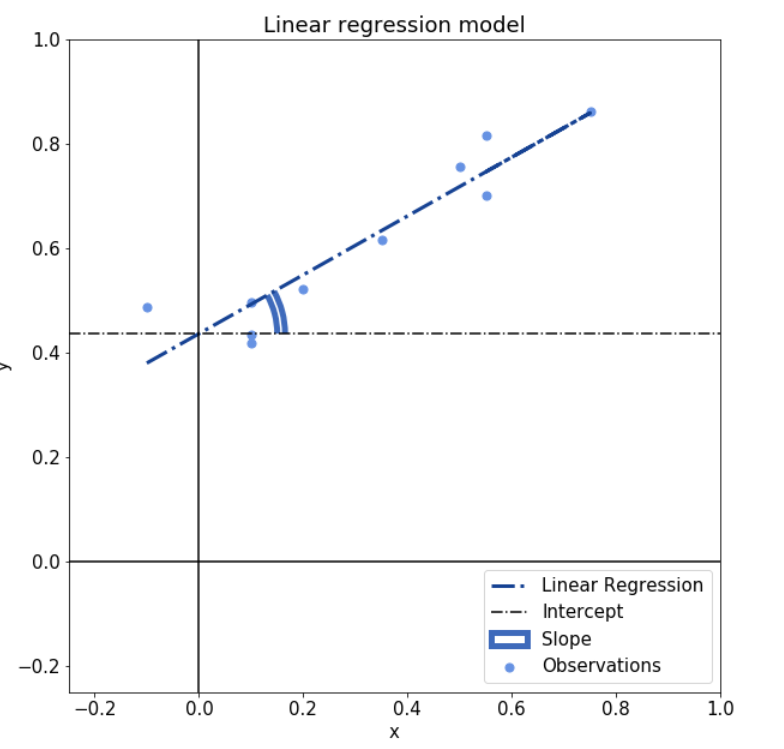
最后,在回归分析的具体情况下,我们还可以根据公式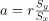 ,将参数一个想象为与分布x和y的相关系数r相关。在这个公式中,Sy和Sx分别表示y和x的未校正标准差。相关性实际上是指线性回归模型在两个标准化分布上的斜率的另一种方式。
,将参数一个想象为与分布x和y的相关系数r相关。在这个公式中,Sy和Sx分别表示y和x的未校正标准差。相关性实际上是指线性回归模型在两个标准化分布上的斜率的另一种方式。
4. 逻辑回归
4.1. 逻辑函数的公式
我们现在可以陈述逻辑函数的公式,就像我们之前对线性函数所做的那样,然后看看如何扩展它以进行回归分析。正如线性回归的情况一样,逻辑回归实际上是试图为一个模型找到参数,这个模型将两个变量之间的关系映射到一个逻辑函数。逻辑函数的形式是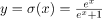 ,其中e表示欧拉数,x与线性模型之前一样,是一个自变量。这个函数允许将R中的任意连续分布变量
,其中e表示欧拉数,x与线性模型之前一样,是一个自变量。这个函数允许将R中的任意连续分布变量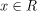 映射到开放区间(0,1)。与logistic函数相关的图如下:
映射到开放区间(0,1)。与logistic函数相关的图如下:
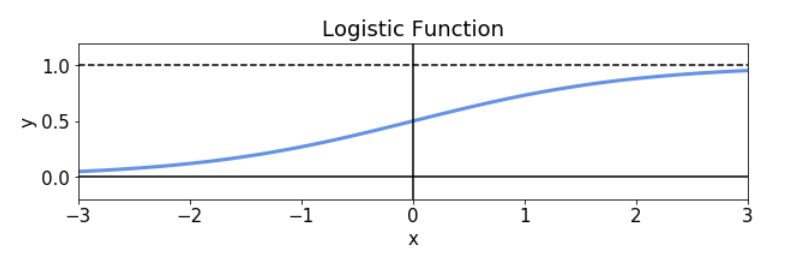
我们展示的逻辑函数是一种S 形函数。后者在神经网络的非线性激活函数的上下文中尤为重要。然而,它也是定义 Logit模型的基础,这是我们在进行逻辑回归时尝试学习的模型,我们稍后会看到。
4.2. Logistic函数的特征
由于logistic函数的上域是区间(0,1),这使得logistic函数特别适合表示概率。虽然也存在逻辑函数的其他用途,但该函数通常用于将实数映射到伯努利分布变量。
如果一个因变量是伯努利分布的,这意味着它可以假设两个值之一,通常是0和1。逻辑函数的输入可以是任何实数。这使得逻辑函数特别适合于我们需要将具有域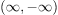 的变量压缩到有限区间的应用程序。
的变量压缩到有限区间的应用程序。
因为我们可以假设逻辑模型中的因变量是伯努利分布的,这意味着该模型特别适合于分类任务。在这种情况下,1的值对应于积极的阶级归属。对称地说,0的值对应不正确的分类。反过来,这使得逻辑模型适合于执行涉及无序分类变量的机器学习任务。
4.3. Logit 模型
![]()
Logit模型是伯努利分布变量和广义线性模型之间的链接模型。广义线性模型的形式是y = ax + b。这在很大程度上对应于我们上面研究的线性模型。
在这个模型中,如这里,一个是一个参数向量,X包含自变量。然后,一个链接函数(如Logit)将一个分布(在本例中是二项分布)与广义线性模型联系起来。
在使用Logit模型时,我们接收到一个实值,该实值返回一个大于模型输入阈值的正输出。这反过来又触发了分类:

4.4. 逻辑上的回归
现在的问题是,我们如何学习广义线性模型的参数A?在逻辑回归的情况下,这通常是通过最大似然估计来完成的。我们可以通过梯度下降来进行处理。
我们通过扩展上面的逻辑函数公式来定义函数L(A | y, x)。如果一个是包含函数参数的向量,那么:
![]()
然后,我们可以通过最大化该函数的对数来继续回归。原因与对数函数的单调性有关。事实上,这种单调性意味着它的最大值位于该对数参数的相同值处:
![]()
该函数![]() 还采用对数似然的名称。现在,我们可以通过一步一步的回溯过程将这个最大值识别到任意程度的精度。这是因为,与对数似然的最大值相对应,梯度为零。这意味着可以通过反复回溯找到满足此条件的参数值,直到我们对近似值感到满意。
还采用对数似然的名称。现在,我们可以通过一步一步的回溯过程将这个最大值识别到任意程度的精度。这是因为,与对数似然的最大值相对应,梯度为零。这意味着可以通过反复回溯找到满足此条件的参数值,直到我们对近似值感到满意。
5. 线性回归和逻辑回归之间的差异
我们现在可以总结一下本文所考虑的问题。这让我们可以识别两种类型的回归之间的主要差异。具体来说,两种模型的主要区别是:
1. 公式不同,回归的函数也不同。线性回归隐含函数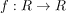 ,逻辑回归隐含函数
,逻辑回归隐含函数
2. 类似地,因变量的分布也不同。线性回归的上域是R,而逻辑回归的上域是(0,1)
3. 误差的测量方法和回归的测量方法是不同的。线性回归通常使用误差平方和,而逻辑回归使用maximum (log)。
4. 这些函数的典型用法也不同。我们通常在假设检验和相关分析中使用线性回归。相反,逻辑回归有利于概率的表示和分类任务的进行。
相反,相似之处是这两个回归模型与一般回归分析模型的共同之处。我们在前面详细讨论过这些,我们可以根据我们的新知识来参考它们。
6. 结论
在本文中,我们研究了线性回归和逻辑回归之间的主要异同。
我们首先分析了所有回归模型的特征,并进行了一般的回归分析。
然后,我们定义了线性模型和线性回归,以及学习与之相关的参数的方法。我们通过最小化平方误差的总和来做到这一点。
以类似的方式,我们还定义了逻辑函数、Logit 模型和逻辑回归。我们还了解了最大似然法以及通过梯度下降估计逻辑回归参数的方法。
最后,我们以简短的形式确定了两种模型之间的主要区别。这些差异与它们的特殊特征和不同的用法有关。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号