
随机森林与极度随机化树-AI快速进阶系列
1. 简介
在本教程中,我们将回顾随机森林 (RF) 和极端随机树 (ET):它们是什么、它们的结构以及它们有何不同。
2. 定义
随机森林和极端随机树属于一类称为集成学习算法的算法。集成学习算法利用许多学习算法的强大功能来执行任务。例如,在分类任务中,集成学习算法可以聚合来自多个不同分类器的预测以进行最终预测。
这个概念是基于这样一种观念,即使用多种学习算法可以导致更好的最终预测。接下来,让我们详细看看随机森林和极端随机树。
3. 随机森林
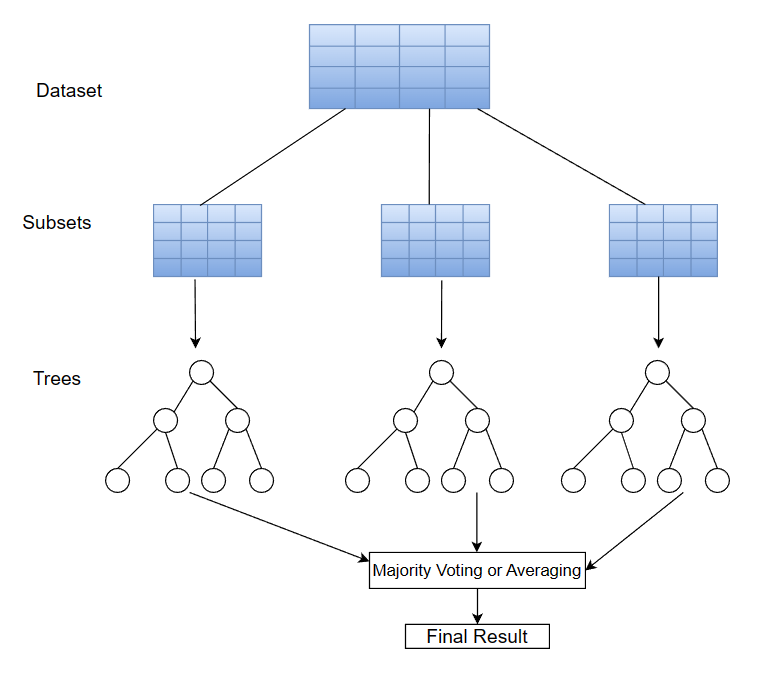
当我们谈论随机森林时,我们指的是由多个决策树组成的学习算法。随机森林在训练期间针对训练数据的不同子集构建多个决策树(一个森林)。同样,想法仍然是一样的,几个组合树的结果可能比单个树的结果更好。
给定具有多个特征的数据集,RF 算法将从数据集中对具有不同特征的观测值子集进行采样。在此子集上构造决策树。这种使用替换对子集进行采样的过程称为引导。
请注意,在构建决策树时,RF 将在每个节点上选择最佳拆分。接下来,对具有不同特征的不同数据子集重复此过程,直到构建了指定数量的树。
从所有树中获得结果后,将通过多数投票进行分类或平均回归获得最终预测。例如,让我们考虑一个包含六棵树的 RF 分类任务。假设其中五棵树预测类 0。根据多数投票,最终类被分配为 0:
3.1. 优点和缺点
随机森林是健壮的,在回归和分类任务上都运行良好。此外,RF 算法适用于大型数据集和不同的数据类型,例如数字、二进制和分类。
但是,当树的数量较多时,复杂度和计算时间相对较高,导致训练时间较长。此外,子集的抽样可能会引入一些偏差。
3.2. 应用程序
射频几乎可以应用于任何分类或回归任务。但是,常见的应用领域是遥感、股票市场预测、欺诈预测、情绪分析和产品推荐。
4. 极度随机的树
极端随机树,也称为额外树,在整个数据集的训练期间构建多个树,如射频算法。在训练期间,ET 将在数据集中的每个观测值上构建树,但具有不同的特征子集。
需要注意的是,虽然 ET 的原始结构中没有实现引导,但我们可以在一些实现中添加它。此外,在构建每个决策树时,ET算法随机拆分节点。
4.1. 优点和缺点
额外树的主要优点是减少了偏差。这是在树的构建过程中从整个数据集中采样。数据的不同子集可能会在获得的结果中引入不同的偏差,因此额外树通过对整个数据集进行采样来防止这种情况。
额外树的另一个优点是它们减少了方差。这是决策树中节点随机拆分的结果,因此算法不受数据集中某些特征或模式的严重影响。
4.2. 应用程序
同样,我们可以将额外树应用于分类和回归任务,如随机森林。在某些情况下,额外树也用于功能选择。在这里,额外树分类器用于选择最重要的特征。
5. 异同
RF和ET的相似之处在于它们都构建了多个决策树以用于手头的任务,无论是分类还是回归。但是,两者之间存在细微的区别。
让我们看看这些:

6. 结论
在本教程中,我们回顾了随机森林和极端随机树。随机森林在数据的自举子集上构建多个决策树,而额外树算法在整个数据集上构建多个决策树。此外,RF 选择要拆分的最佳节点,而 ET 随机化节点拆分。
最重要的是,选择使用哪一个始终取决于可用的数据集和手头的任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号