
反向传播神经网络中的非线性激活函数-AI快速进阶系列
1.简介
在本教程中,我们将研究反向传播算法和其他学习过程中最常用的非线性激活函数。
导致使用非线性函数的原因已在上一篇文章中进行了分析。
2.前馈神经网络
反向传播算法在完全互连的前馈神经网络(FFNN)中运行:
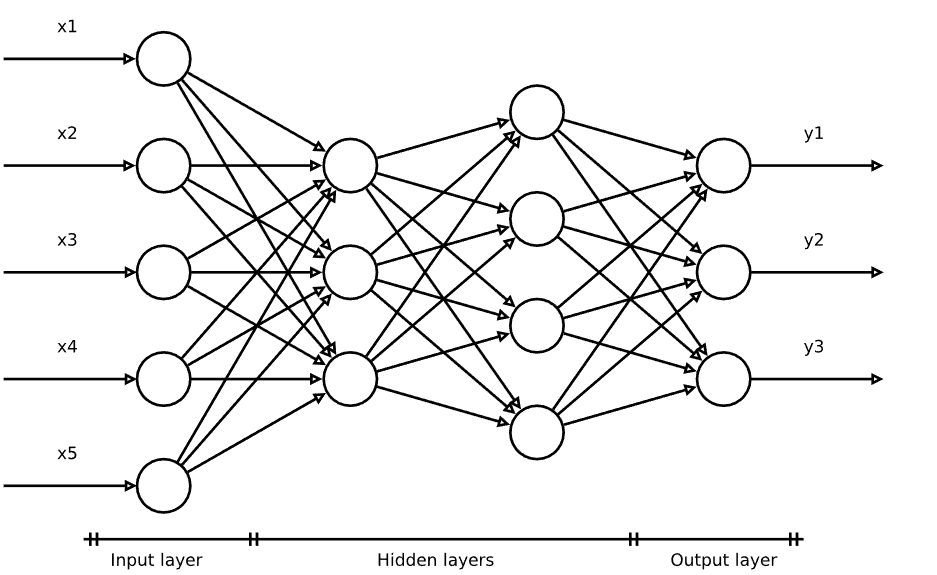
具有以下结构的单元:

该![]() 函数执行输入加权和的转换:
函数执行输入加权和的转换:
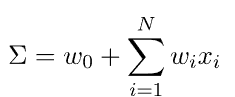
我们将在线性模型文章中更详细地讨论FFNN。
3.激活函数族指南
让我们以以下非线性函数为例:
从我们关于线性函数的文章中所做的考虑,很明显,平面(线性模型)不能近似于图的函数。
在引言中,我们使用了术语“单位”而不是“神经元”。在许多情况下,生物学类比具有误导性。
神经网络是数学和统计过程,与生物神经网络的相似性有限。然而,这种类比在某些情况下可能很有用,我们将讨论神经元的输出,以证明选择某些非线性函数家族作为激活函数的合理性。
生物神经元传递电信号。它通过细胞膜通过轴突传播到下游神经元。当离子K^+和Na^+(动作电位)的浓度发生变化时,神经元试图重新建立电平衡,电位差和电信号就产生了。
霍奇金和赫胥黎在1952年解释了这种机制的特征和随时间的变化,他们因这项工作于1963年获得了诺贝尔医学奖。
3.1. 突触
信号从一个神经元到另一个神经元的传递是通过突触传递进行的,可以有两种类型。如果两个神经元相互接触,则存在电信号(电突触)的直接通过。如果两个神经元不接触,信号通过使用化学神经递质(化学突触)传播。
鉴于两个细胞之间的物理接触,电突触通常更快,并且是双向的,传统上与反射反应有关。但是,这种类型的信号不会被调制,无法适应环境条件的变化。
因此,进化产生了化学突触,通常在高等动物中,具有单向性质,允许信号被增强或抑制。
化学突触的传输速率低于电突触,但允许可塑性和适应导致学习的环境条件,即神经元连接的校准。
如果我们想强制类比,人工神经网络中的可调权重是一个类似于生物化学突触的数学模型。
3.2. 阶跃函数
生物神经元的输出是数字的,无论是否被激发。
膜电位在非常有限的时间内达到最大值。在人工神经网络中单位信号的建模中包含时间概念导致了尖峰神经网络,这是一个非常活跃的研究领域。当信号值超过阈值时,就会产生信号,因此具有不连续性。
下面我们说明这种行为,或者换句话说,阶跃函数,我们可以将其视为生物神经元中的激活函数的等价物:

4.反向传播
现在让我们简要介绍一下反向传播背后的理论。优秀的参考资料是经典的Krose和Van der Smagt论文以及Bishop的书。
4.1.通用逼近定理
反向传播是我们开发的一种用于训练多层神经网络的算法。
然而,对这种类型的网络的需求似乎与通用近似定理相矛盾。这一结果表明,具有单个隐藏层和非线性激活函数的网络几乎可以逼近每个连续函数。第一个版本由Cybenko在1989年演示,用于sigmoid激活函数。
不幸的是,理论结果是一回事,应用是另一回事:
- 可以显示具有单层的网络中的单元数量如何随着问题的大小呈指数增长,在某些情况下不适用或无法进行学习,获得较差的泛化技能
- 此外,通用近似定理没有告诉我们任何关于学习过程的信息。
进一步的研究已经完善了原始的Cybenko结果。
1991年,Hornik表明,这不是激活函数的具体选择,而是多层前馈架构本身,它使神经网络具有成为通用逼近器的潜力。这些考虑因素证明了搜索适用于多层神经网络的算法(例如反向传播)的合理性。
4.2.学习规则
在监督神经网络中,目标的测量数据可用于校准给定特定输入的网络输出。
学习过程包括网络权重的变化,从而可以对该目标进行最佳预测。这种变化是通过应用规则来实现的。
实际上,这种类型的模型的所有学习规则都是Hebb在1949年提出的Hebbian学习规则的变体。一些例子是:
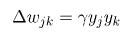
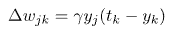
其中重量wjk是指单位j和k之间的连接。 请注意,输出层之前层的单位输出将成为当前单位的输入(yj = xk)。 ![]() 是一个称为学习率的比例常数,它是网络要优化的参数之一。 tk是输出单位k测量的目标。 最后一条规则特别直观,因为它实现了权重的变化,这取决于输出与期望值之间的差异,并且可以使用线性激活函数通过一点微积分获得。
是一个称为学习率的比例常数,它是网络要优化的参数之一。 tk是输出单位k测量的目标。 最后一条规则特别直观,因为它实现了权重的变化,这取决于输出与期望值之间的差异,并且可以使用线性激活函数通过一点微积分获得。
4.3.增量规则
假设一个具有单层的网络,该网络使用网络输出和目标之间的二次误差作为预测优度的度量,使用测量数据数据集的P记录:
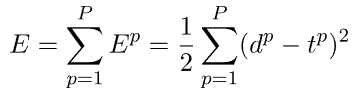
使用由线性加权和的激活函数给出的网络输出:
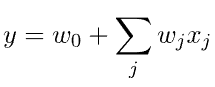
误差表达式中的因子1/2是任意的,用于在微分过程中获得单位系数。
对于模式p,Delta规则将权重变化与误差梯度连接起来:

改变权重来最小化误差,因此,它也被称为梯度下降法。
导数可以用链式法则计算:
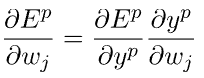
从前面的错误和输出表达式中,我们有:
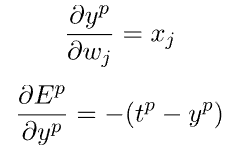
这导致了最终的表达式:
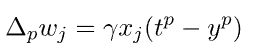
4.4.信用分配问题
在上面提到的上一篇文章中,我们已经看到具有线性激活函数的多层网络简化为具有包含线性激活函数的单元的单层网络。在这种情况下,上一节中派生的增量规则是适当的学习规则。
如果我们想使用多层和非线性激活函数来提高网络的表达能力,我们需要为连接两个任意层的权重找到一个学习规则。对于连接到输出权重的权重,原则上可以假设类似于上一节的过程。
单位输出和目标之间的比较可以允许获得学习规则。但是,对于预输出层,我们如何改变权重以最小化误差?
在这种情况下,我们没有目标的帮助作为指导搜索的指南。此外,隐藏层中权重的变化会导致输出成为下游层的输入,依此类推,直到输出层。这是有问题的,因为输出层是我们可以使用目标来了解所有权重的整体变化是否产生了小误差的唯一层。
这种困难被称为信用分配问题,它对我们现在所说的深度学习的发展构成了主要障碍。直到1986年,Rumelhart,Hinton和Williams发表了一篇现在经典的文章,其中他们描述了反向传播算法。自 1970 年代以来,人们已经知道类似的算法,但作者展示了如何将其用作学习过程。
4.5.广义增量规则
这个想法是概括 Delta 规则并使用链式规则来获得隐藏层权重变化的表达式:
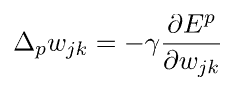
对于两个相互连接的层,j加kk>j权和概括为:

对网络单元使用通用非线性激活函数:
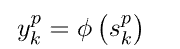
链式规则允许获取输出层和隐藏层oh单位的以下表达式:
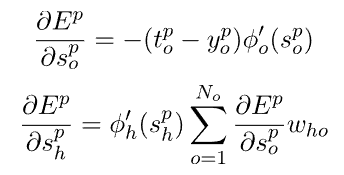
上述表达式涉及激活函数的导数,因此需要连续函数![]() 。
。
4.6.从生物神经元到非线性人工神经网络
到目前为止,我们所做的考虑为我们提供了一个选择非线性数学函数作为激活函数的标准。它们必须是连续的和可微分的,正如反向传播所要求的那样,并再现生物神经元输出的趋势。
我们将研究两个可能的类别:sigmoid 函数和 ReLU 系列。
5. Sigmoid激活函数
Sigmoid 函数是为所有实输入值定义的有界、可微实数函数,并且每个点都有一个非负导数。以下是一些重要的 sigmoid 函数及其主要功能。
5.1. Logistic
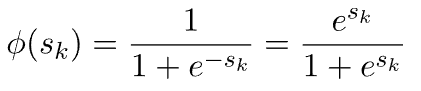
它的优点是梯度平滑,但缺点是计算成本高。
5.2. 双曲正切
![]()
5.3. Softmax
我们可以在分类问题中使用 Softmax,通常在输出层:
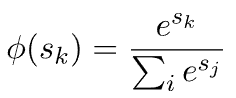
5.4. 反双曲正切(反弧)
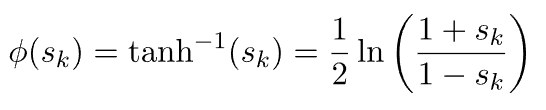
5.5. 古德曼函数,古得曼行列式
古德曼函数将循环函数和双曲函数联系起来,而不显式使用复数:
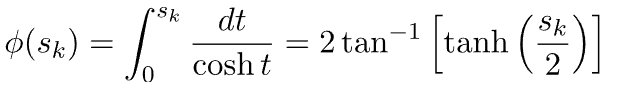
5.6. 误差函数
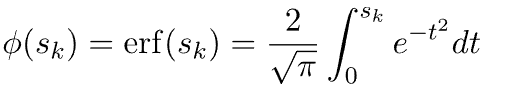
5.7. 广义logistic
将广义logistic函数简化为a=1时的logistic函数:
![]()
5.8. 库马拉斯瓦米(Kumaraswamy )函数
库马拉斯瓦米函数是逻辑函数的另一种推广。它简化为a=b=1物流功能:
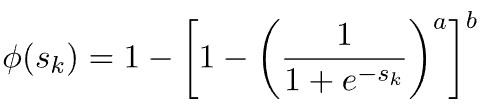
5.9. Smoothstep函数
平滑步函数为:
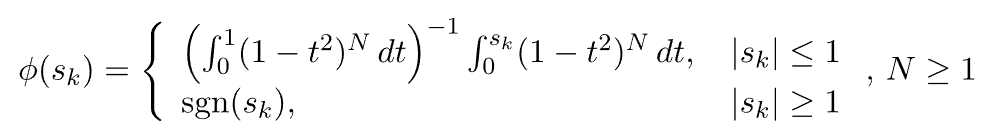
5.10. 代数函数
最后是代数函数:
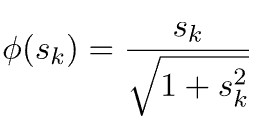
5.11. Sigmoid 激活函数的问题
应用作为激活函数列出的函数通常需要重新缩放所考虑问题的数据集。
例如,如果我们使用逻辑函数,我们的目标必须在[0:1]范围内标准化,以便函数的值可以近似于它。这是所有激活函数都需要的,而不仅仅是sigmoid激活函数。
然而,这些函数对于s_k的大值和小值都有饱和效应,这降低了网络的分辨率:
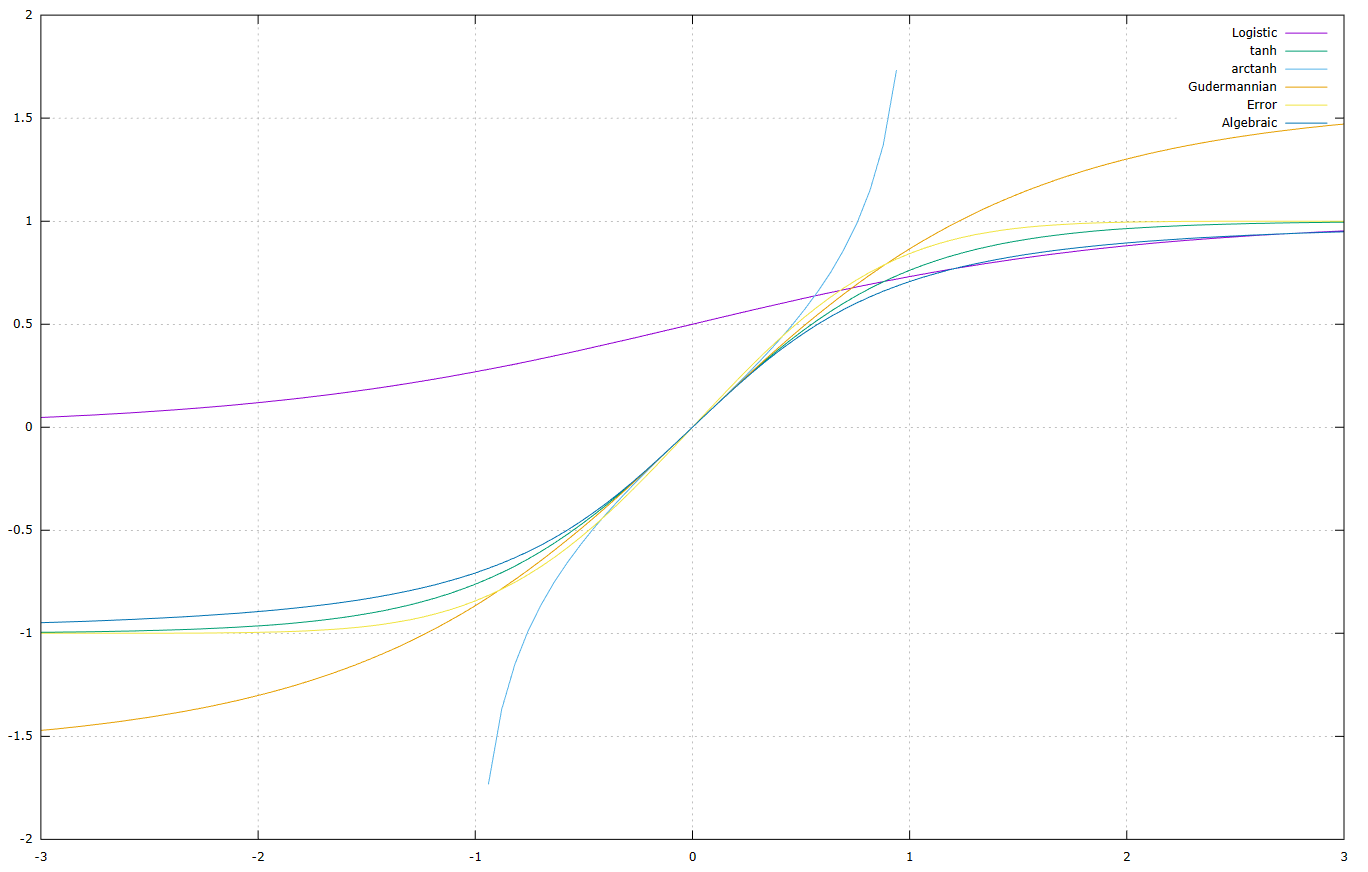
这种机制导致了所谓的梯度消失问题。这是在一定条件下梯度的取消,这可以阻止学习过程。这个缺点可以通过使用更窄的归一化区间来缓解,例如对于logistic函数[0.1:0.9],或者对于tanh函数[-0.9:0.9]。
此外,一般来说,s型函数是计算量大的。
6.整流线性单元-ReLU系列
6.1. 一般特性
ReLU系列具有许多优点:
- 生物学合理性
- 更好的梯度传播:与在两个方向上饱和的 S 形激活函数相比,梯度消失问题更少
- 计算效率高:仅比较、加法和乘法
- 尺度不变
下图显示了下面提到的一些函数的图形表示:

6.2. ReLU
虽然它看起来像一个线性函数,但ReLU有一个导数函数,并允许反向传播:
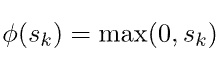
然而,它也存在一些问题。首先,垂死的ReLU问题。当输入趋近于零或为负时,函数的梯度变为零,网络无法进行反向传播,无法学习。这是梯度消失问题的一种形式。
在某些情况下,网络中的大量神经元可能会陷入死亡状态,从而有效地降低模型的容量。当学习率设置得太高时,通常会出现这个问题。它可以通过使用Leaky ReLU来缓解,它为x<0分配了一个小的正斜率。
而且,它是一个无界函数,这意味着它没有最大值或最小值。
6.3. Leaky ReLU
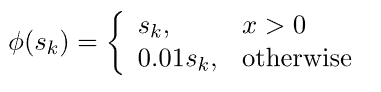
但是,它不允许对sk < 0进行一致的预测。
6.4. 参数化 ReLU
参数化 ReLU 允许将参数a插入到学习过程中,而不是定义像 Leaky ReLU 这样的任意值:
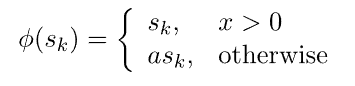
6.5. Noisy ReLU
另一个是ReLU的扩展,称为噪声ReLU。主要区别是输出包含由高斯概率密度N产生的噪声,其均值为零,标准差为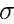 (sigma):
(sigma):
![]()
6.6. ELU
指数线性单位 (ELU) 尝试使平均激活接近零,从而加快学习速度。ELU 可以获得比 ReLU 更高的分类精度:
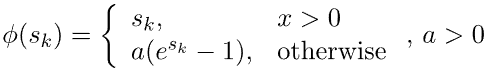
6.7. Softplus 或SmoothReLU
ReLU(Softplus/SmoothReLU)函数的平滑近似有一个显着的特征,即其导数是逻辑函数:

6.8. Swish函数
Swish函数由Google开发,具有卓越的性能和与ReLU函数相同的计算效率:
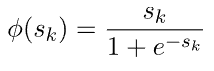
7.Complex Nonlinear Activation 函数
7.1. 复杂问题
我们之前考虑的所有激活函数都是真实的。但是有些应用领域使用具有复杂功能的模型。
一个典型的例子是电磁系统,其中许多系统模拟某种类型的波现象,具有振幅和相位。复杂特征源于波是周期函数,可以用虚指数表示,因为从欧拉公式:
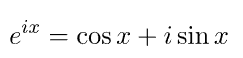
-
I是虚数单位。
我们可以使用虚激活函数的其他应用领域是电磁波和光波,模拟和数字电路中的电信号;电子波;超导体;量子计算;声波和超声波;周期性类型和指标;循环动力学的高稳定性;混沌和分形;四元数。
7.2.Activation Functions in Complex-Valued Neural Networks(复值神经网络中的激活函数)
我们可以通过多种方式处理神经网络本质上复杂的问题。例如,我们可以设计一个网络,该网络将模型的实部和虚部作为单独的输出单元,仅使用实函数,但也可以直接处理它们。
这个话题非常广泛。重要的问题是,有可能利用复杂的非线性激活函数导出反向传播的扩展,从而产生所谓的复值神经网络(CVNN)。
这些激活函数使用我们在前一节中分析过的一些sigmoid函数的表达式。网络的每个单元都产生一个复杂的输出,我们可以聚合它,它成为下一层单元的复杂输入。
通常,我们考虑两种主要形式的函数,实数-虚数型激活函数:
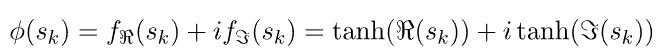
和振相型激活函数:
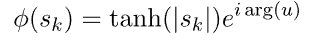
其中arg是复数sk的参数,![]() 和
和![]() 是实分量和虚分量。
是实分量和虚分量。
8. 结论
在本教程中,我们概述了反向传播算法中使用的非线性激活函数。
我们没有简单地列出数学函数及其特征,而是试图对这个问题给出一个连贯的方法,突出问题和需求,从逻辑的角度来看,这些问题和需求导致了文本的处理。
一些鲜为人知的扩展,如虚函数,最近使得将前馈神经网络和反向传播算法的应用扩展到新问题成为可能。
我们还可以发现许多其他非线性激活函数,以使用反向传播以外的算法来训练网络。例如,径向基函数(RBF)使用高斯函数;但是,在本文中,我们重点介绍了反向传播机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号