

什么是交叉熵-AI快速进阶系列
1. 概述
在本教程中,我们将研究机器学习交叉熵的定义。
我们将首先讨论信息论中的熵的概念及其与监督学习的关系。
然后,我们将看到如何从单变量分布中的熵定义中推导出二元分布中的交叉熵。这将使我们很好地理解一个如何概括另一个。
最后,我们将看到如何使用交叉熵作为损失函数,以及如何通过梯度下降来优化模型的参数。
2. 熵
2.1. 监督学习中的熵和标签
在我们关于熵的计算机科学定义的文章中,我们讨论了二进制变量的信息熵与符号序列中的组合熵有关的想法。
让我们首先定义为x一个随机分布的二进制变量。然后,我们可以将其香农熵度量计算H为变量可以假设的两个符号(0 位和 1 位)的组合熵。公式H如下:
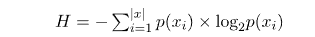
当我们在监督机器学习中处理分类问题时,我们尝试学习一个函数,该函数将一组有限的标签中的一个标签分配给观察的特征。因此,标签或类c的集合C = {c_1, c_2, ... , c_n}由几个不同的符号组成,我们可以将它们视为模型输出假设的可能值。这样我们可以计算分类预测模型输出的类标签的熵度量。
2.2. 概率分类而非确定性分类
有两种方法可以过渡到熵的概率定义,这使我们能够使用概率而不是标签的离散分布。
第一种方法是将类的相对发生频率解释为其发生的概率。这意味着我们可以考虑p(c_i)类在类c_i分布中出现的次数除以分布的长度。
第二个与一些分类模型本质上是概率性的考虑有关,并且不输出单点预测,而是输出概率分布。这与分类模型外层中使用的激活函数有关。机器学习模型输出层最常见的概率函数是:
logistic函数
softmax函数
hyperbolic tangent函数,如果归一化到区间(0,1)
这些函数输出0到1之间的一个值或一组值,因此我们可以将其解释为观测值所属类的概率分布。
这些函数输出一个或一组介于 0 和 1 之间的值或一组值,因此我们可以将其解释为观察的类隶属关系的概率分布。
2.3. 标签的熵和概率分布
特别是softmax函数,而不是将单个类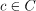 输出为给定输入的最可能的标签,而是返回整个集合C的概率分布
输出为给定输入的最可能的标签,而是返回整个集合C的概率分布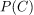 。此概率对应于分配给每个可能标签
。此概率对应于分配给每个可能标签 的各个概率
的各个概率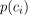 。
。
我们随后可以使用它们来计算类别标签C及其相关概率P(C)分布的熵:
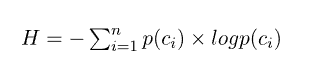
2.4. 分类中熵的实际例子
让我们想象一下,例如,我们正在使用逻辑回归进行二元分类。逻辑模型的输出是一个由0到1组成的值,我们通常将其解释为输入属于第一类的概率P(y=1|x) = P(1)。这意味着第二个可能的类别具有相应的概率P(y=0 | x) = P(0) = 1- P(1),二元分类中的铽非达图尔。
我们最初可以假设逻辑模型有一个具有单一特征的输入,没有偏差项,并且唯一输入的参数为1。从这个意义上说,该模型完美地对应于sigmoidal函数![]() 且
且 。
。
然后我们可以将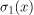 和
和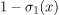 这两个概率解释为二进制随机变量的概率分布,并据此计算熵测度H:
这两个概率解释为二进制随机变量的概率分布,并据此计算熵测度H:
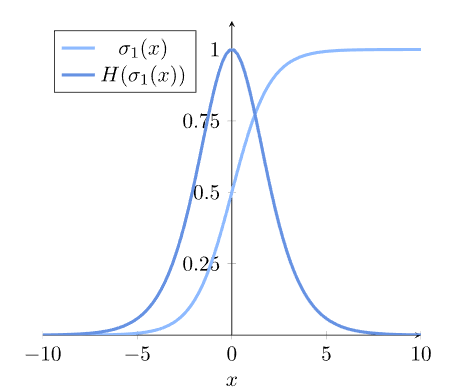
毫不奇怪,当分类的输出未定时,熵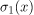 最大化。当分配给每个类的概率相同时,就会发生这种情况。
最大化。当分配给每个类的概率相同时,就会发生这种情况。
2.5. 使用多个概率分布
但是,我们也可以使用多个概率分布和相应的模型。例如,如果我们比较逻辑回归的多个模型的输出,就像我们上面定义的那样,就是这种情况。
假设我们要将前一个模型与第二个模型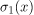
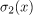 进行比较。进行这种比较的一种方法是研究相对两个概率分布及其熵之间存在的差异。
进行比较。进行这种比较的一种方法是研究相对两个概率分布及其熵之间存在的差异。
如果我们想象对于两个参数是
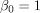 和
和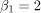 ,那么我们得到一个具有这个相关熵的模型:
,那么我们得到一个具有这个相关熵的模型: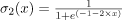
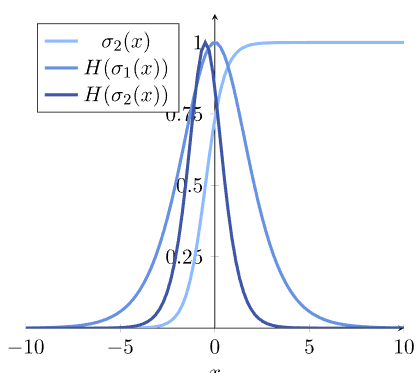
请注意,这两个模型的熵是如何不对应的。这意味着,作为一般规则,两种不同概率分布的熵是不同的。
2.6. 有些熵比其他熵更相等
最后,如果我们比较两个熵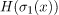 和
和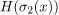 第三个熵
第三个熵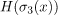 ,它源自具有参数
,它源自具有参数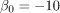 和
和 的逻辑模型,我们会观察到这一点:
的逻辑模型,我们会观察到这一点:
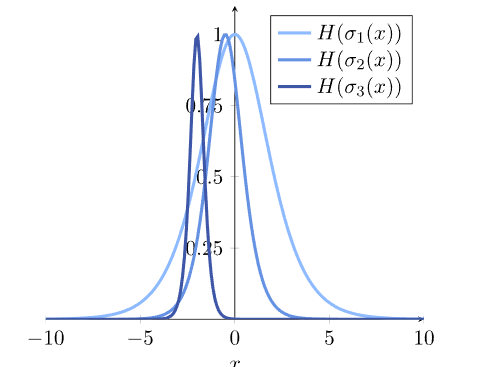
在我们看来,前两个概率分布与分类器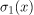 、
、 相关,其熵比第三个分类器的
相关,其熵比第三个分类器的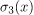 熵更相似。
熵更相似。
这给了我们一个直观的想法,如果我们想比较概率模型之间的预测,甚至概率模型和一些已知的概率分布之间的预测,我们需要使用一些无量纲度量来比较它们各自的熵。
3. 交叉熵
3.1. 交叉熵的定义
在这些基础上,我们可以将单变量随机分布中的熵概念扩展到二元分布的交叉熵的概念。或者,如果我们使用概率术语,我们可以从概率分布的熵扩展到两个不同概率分布的交叉熵度量。
两个概率分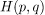 的交叉熵P,Q并拥有以下公式:
的交叉熵P,Q并拥有以下公式:

3.2. 模型比较的交叉熵
我们可以应用这个公式来比较两个模型的输出, 并且
并且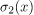 ,从上一节:
,从上一节:![]()
这是这两个特定模型的交叉熵图:
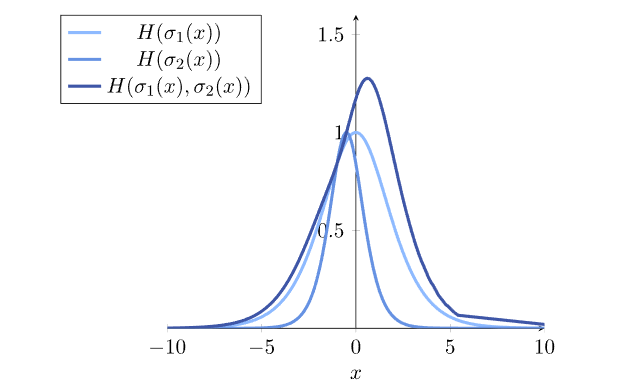
请注意,交叉熵通常(但不一定)高于两个概率分布的熵。我们对这种现象的一个直观理解是将交叉熵想象为两个分布的某种总熵。然而,更准确地说,我们可以考虑来自两个分布的交叉熵,以使其与这些分布的熵保持距离,两个分布之间的差异就越大。
3.3. 配对排序事项
另请注意,我们将术语插入H运算符的顺序很重要。两者的功能 和
和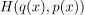 一般是不同的。例如,这是比较两个逻辑回归模型的交叉熵的图形,同时交换项:
一般是不同的。例如,这是比较两个逻辑回归模型的交叉熵的图形,同时交换项:
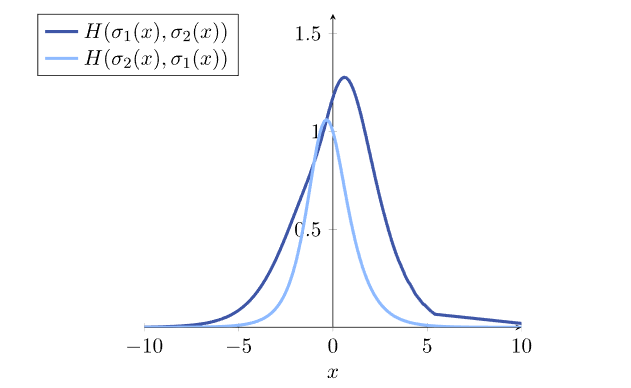
当我们计算观测到的概率分布之间的交叉熵时,这一点尤其重要;比如,一个分类模型的预测,和一个目标类分布。在这种情况下,真实的概率分布总是第一项p(x),模型的预测总是第二项q(x)。
4. 通过交叉熵进行模型优化
4.1. 交叉熵作为损失函数
交叉熵在机器学习中最重要的应用在于它作为损失函数的使用。在这种情况下,交叉熵的最小化;即,损失函数的最小化允许优化模型的参数。对于模型优化,我们通常使用所有训练观察值和相应预测之间的交叉熵平均值。
让我们将逻辑回归模型用作预测模型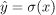 。然后,交叉熵作为其损失函数为:
。然后,交叉熵作为其损失函数为:
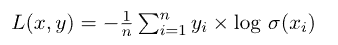
4.2. 交叉熵的算法最小化
然后,我们可以通过优化构成模型预测的参数来最小化损失函数。参数空间上的梯度下降。实现此目的的典型算法方法是通过跨越的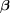
我们在上面讨论了如何计算逻辑模型的预测。具体来说,我们指出预测被计算为输入和参数的线性组合的逻辑函数:
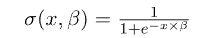
我们还知道逻辑函数的导数为:
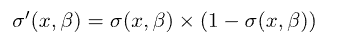
由此,我们可以推导出关于参数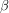 的梯度为:
的梯度为:
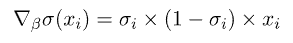
接着,我们可以将损失函数的梯度计算为:
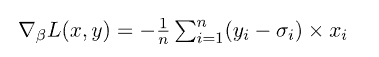
最后,这让我们通过梯度下降来优化模型。
5. 结论
在本文中,我们研究了交叉熵的定义。我们从单变量概率分布的熵形式化开始。然后,我们推广到二元概率分布及其比较。
此外,我们分析了交叉熵作为分类模型损失函数的作用。
与此相关,我们还研究了通过梯度下降将其最小化的问题,以实现参数优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号