
生成对抗网络-AI快速进阶系列
1. 概述
在本教程中,我们将介绍生成对抗网络 (GAN)。
首先,我们将介绍术语生成模型及其分类法。然后,将描述GAN的架构和训练管道,并附有详细示例。最后,我们将讨论GAN的挑战和应用。
2. 生成模型
在机器学习中,有两种主要的学习类型:
在监督学习中,我们被给予自变量X和相应的标签Y,我们的目标是学习一个映射函数f: X to Y,使预定义的损失函数最小化。在这些任务中,我们训练判别模型,目的是学习条件概率p(Y|X)。监督学习任务的例子包括分类、回归等。
无监督学习,我们只给自变量X,我们的目标是学习数据的一些潜在模式。在这些任务中,我们训练生成模型,目的是捕获概率p(X)。无监督学习任务的例子包括聚类、降维等。
通常,生成模型尝试学习数据的底层分布。然后,该模型能够预测给定样本的可能性,并使用学习到的数据分布生成一些新的样本。
生成模型有两种类型:
一方面,我们有明确的密度模型,假设数据的先验分布。在这里,我们定义了一个显式的密度函数,然后我们尝试在我们的数据上最大化这个函数的可能性。如果我们能以参数形式定义这个函数,我们就讨论了一个可处理的密度函数。然而,在许多情况下,如图像,不可能设计一个参数函数来捕捉所有的数据分布,我们必须使用密度函数的近似值。
另一方面,还有隐式密度模型。这些模型定义了一个直接生成数据的随机过程。GANs属于这一类:
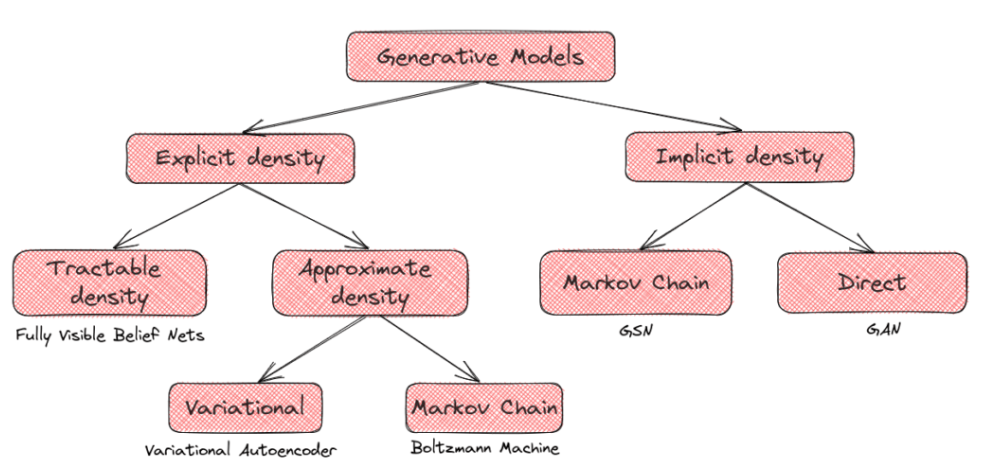
上面,我们可以看到Ian Goodfellow提出的生成模型的分类法。
3. 生成对抗网络
3.1. 架构
让我们从由两个网络组成的 GAN 的基本架构开始。
首先,生成器将固定长度的随机向量z作为输入,并学习映射G(z)以生成模拟原始数据集分布的样本然后,我们有一个鉴别器,它将一个样本x作为输入,这个样本x要么来自原始数据集,要么来自生成器的输出分布。它输出一个标量,表示x来自原始数据集的概率
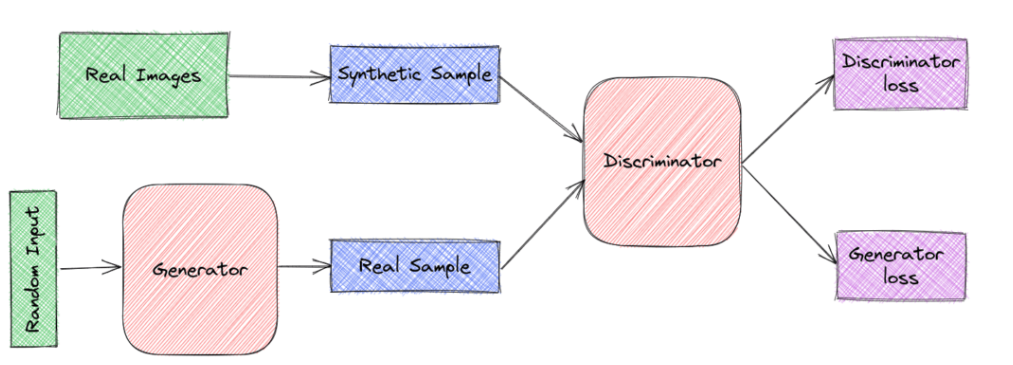
G和D都是神经网络表示的可微函数。
3.2. 损失函数
我们可以把G看作是一群制造假币的造假者,而我们可以把D比作试图检测假币的警察。G的目标是欺骗D,在不被发现的情况下使用假货币。双方都试图改进他们的方法,直到在某一时刻,无法区分真假货币。
更正式地说,D和G使用以下目标函数玩一个双人极大极小博弈:
min_G \ max_D \ log D (x) + log (1 - D (G (z)))
其中x来自原始数据集z是随机向量。
我们观察到,目标函数是用两个模型的参数定义的。G的目标是最小化log (1 - D(G(z))项,以欺骗鉴别器将假样本分类为真实样本。
同时,D的目标是最大化log D(x) + log (1 - D(G(z)),它对应于将正确标签分配给真实样本和生成器样本的概率。
这里需要注意的是,这不是一个常见的优化问题,因为每个模型的目标函数都依赖于其他模型的参数,而且每个模型只控制自己的参数。这就是我们谈论游戏而不是优化问题的原因。虽然优化问题的解是局部或全局最小值,但这里的解是纳什均衡。
3.3. 训练
同步SGD用于训练GAN。在每一步中,我们抽取两批样本:
X个来自原始数据集的样本
来自先验随机分布的Z向量
然后,我们将它们传递给各自的模型,如上图所示。最后,我们同时应用两个梯度步骤:一个是更新G关于其目标函数的参数,另一个是更新D的参数。
3.4. DCGAN
最著名的图像GAN架构之一是深度卷积GAN (DCGAN),它具有以下特征。批处理归一化应用于生成器和鉴别器的所有层。当然,为了学习图像分布的真实均值和尺度,它们的输出层没有被归一化。
然后生成器使用卷积架构:
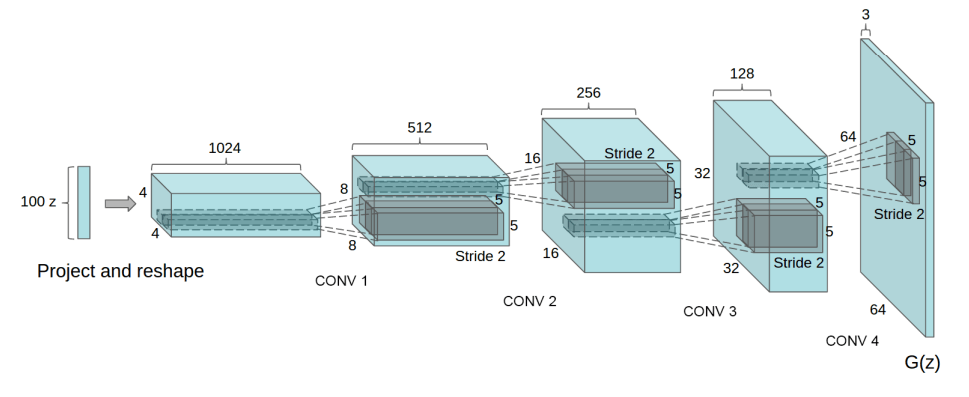
在训练过程中,使用Adam优化器代替SGD, SGD在生成器中使用ReLU激活,在鉴别器中使用Leaky ReLU激活。
3.5. 例子
现在让我们描述一下GAN如何学习生成数字“7”的图像。
首先,Generator从一些简单的先验分布中采样一个向量z,并输出一个图像G(z)。由于模型的参数是随机初始化的,因此输出的图像甚至不接近数字“7”:

在训练过程中,生成器学会了生成越来越接近原始分布(描绘数字“7”)的图像,以欺骗鉴别器。因此,在某个时刻G输出的图像更类似于数字“7”:

最后,生成器输出的图像分布和原始分布非常接近,并生成描绘数字“7”的合成图像:

4. 应用
现在让我们谈谈 GAN 的一些最有用的应用程序。
4.1. 数据增强
GAN可用于在提供的数据有限的情况下生成用于数据增强的合成样本。
4.2. 图像修复
在许多情况下,我们想要重建图像并删除不需要的对象或恢复旧图像的损坏部分。GAN 在这项任务中取得了出色的结果,就像下面的模型移除绳索一样:

4.3. 超分辨率
该术语是指从较低分辨率的图像生成高分辨率图像的过程。对于许多安全应用程序,这是一项非常有用的任务。
4.4. 图像到图像的转换
这里我们要将输入图像转换为输出图像,这是计算机图形学和图像处理中的常见任务。有许多GAN架构可以解决这个问题,比如CycleGAN:
我们只提到了这些模型的几个应用。GAN可以改善许多任务,它们的适用性尚未得到充分探索。每年,我们都发现越来越多的领域可以证明 GAN 是有用的。
5. 挑战
尽管 GAN 已经在许多领域取得了成功,但在训练 GAN 进行无监督学习时,我们必须面对许多挑战。
5.1. 不收敛
正如我们前面提到的,训练GAN不是一个普通的优化问题,而是一个最小最大值游戏。因此,实现收敛到优化生成器和鉴别器目标的点具有挑战性,因为我们必须学习一个平衡点。从理论上讲,我们知道如果在函数空间中进行更新,则同时 SGD 会收敛。当使用神经网络时,这个假设不适用,理论上不能保证收敛性。此外,很多时候我们观察到生成器撤消鉴别器的进度而没有到达任何有用的地方的情况,反之亦然。
5.2. 评估
每个学习任务的一个重要方面是评估。通过检查生成器产生的合成样本,我们可以很容易地定性评估 GAN。但是,我们需要定量指标来稳健地评估任何模型。不幸的是,目前尚不清楚如何定量评估生成模型。有时,获得良好可能性的模型会生成不切实际的样本,而生成真实样本的其他模型则呈现较差的可能性。
5.3. 离散输出
为了训练GAN,生成器的架构应该是可微分的。但是,如果我们希望生成器产生离散数据,则相应的函数将不可微分。尽管针对此限制提出了许多解决方案,但没有最佳的通用解决方案。处理这个问题将帮助我们在NLP等域中使用GANs。
5.4. 使用代码
生成器将随机向量z作为输入并生成样本x。因此,可以将向量z视为样本x的特征表示,并可用于各种其他任务。然而,z给定样本x是非常困难的,因为我们想从高维空间移动到低维空间。
6. 结论
在本教程中,我们介绍了 GAN。首先,我们讨论了提出分类法的生成模型的一般领域。然后,我们描述了GAN的基本架构和训练过程。最后,我们简要提到了GAN的应用和挑战。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号