
监督、半监督、无监督和强化学习简介-AI快速进阶系列
1. 概述
机器学习包括应用数学和统计方法让机器从数据中学习。它由四大技术家族组成:
- 监督学习
- 半监督学习
- 无监督学习
- 强化学习
在本文中,我们将探讨机器学习的目的以及何时应该使用特定技术。因此,我们将根据简单的示例了解它们的工作原理。
2. 监督学习
监督学习是一种由向机器学习模型提供标记数据组成的技术。标记的数据集通常是从经验中收集的数据,也称为经验数据。此外,数据通常需要准备以提高其质量、填补其空白或只是针对训练进行优化。
让我们以以下葡萄酒类型数据集为例:
| 类型 | 酸度 | 二氧化物 | 酸碱度 |
|---|---|---|---|
| 白 | 0.27 | 45 | 3 |
| 红 | 0.3 | 14 | 3.26 |
| 白 | 0.28 | 47 | 2.98 |
| 白 | 0.18 | 3.22 | |
| 红 | 16 | 3.17 |
现在让我们看看准备后的样子:
| 类型 | 酸度 | 二氧化物 | 酸碱度 |
|---|---|---|---|
| 1 | 0.75 | 0.94 | 0.07 |
| 0 | 1 | 0 | 1 |
| 1 | 0.83 | 1 | 0 |
| 1 | 0 | 0.52 | 0.86 |
| 0 | 0.67 | 0.06 | 0.68 |
我们纠正了与数据集质量(缺失单元格)相关的问题,并对其进行了优化以简化学习过程。例如,我们可以看到红色和白色的值已被数字值替换。
根据用例,我们将使用分类或回归模型。
让我们发现这些术语的含义以及如何选择最适合的术语。
2.1. 分类
首先,让我们假设我们有一个汽车图像数据集。我们希望按类型对这些图像进行分类:轿车,卡车,货车等。因此,对于此类用例,我们希望使用分类模型。
这种类型的模型将我们的输入分类到预定义和详尽的类之一中,在本例中按汽车类型分类。
但在此之前,我们将向它提供大量标记为正确输出类的汽车图像。这就是我们所说的训练步骤。
之后,该模型将在另一组以前从未处理过的标记图像上进行测试。此步骤对于了解模型在给定新数据时的行为至关重要。
最后,如果结果达到一定水平的正确预测,我们可以认为模型成熟。级别通常取决于用例的关键程度。例如,过滤垃圾邮件的模型不如操作自动驾驶汽车的模型重要。我们使用损失函数计算模型的准确性。
作为说明,下图是由两个类组成的分类模型的示例:cat和not cat:
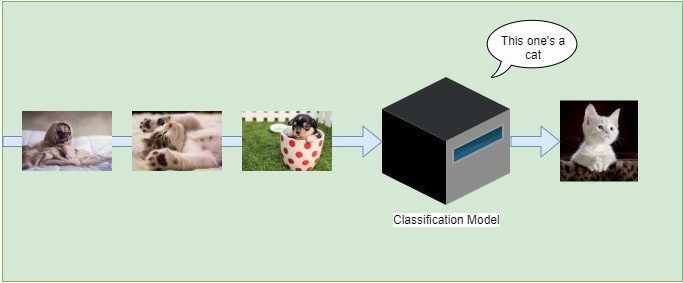
让我们列出一些用于分类的算法:
- 逻辑回归
- 随机森林
- 决策树
- 支持向量回归器
- k 最近邻
2.2. 回归
另一方面,回归不会给出一个类作为输出,而是一个特定的值,也称为预测或预测。
我们使用回归模型根据历史数据预测这些值。这样,它与分类模型没有太大区别。它还需要一个训练步骤和一个测试步骤。
例如,假设我们有人的年龄和他们各自的身高。使用这些数据,我们将能够建立一个模型,根据某人的年龄预测他们的身高最有可能是多少:
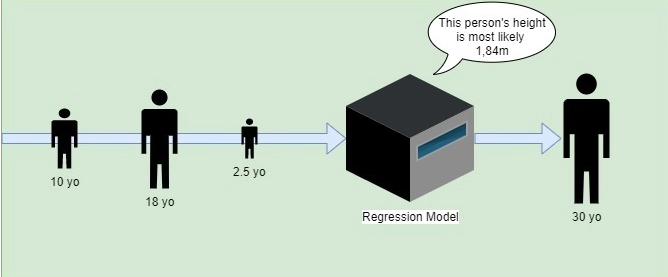
让我们看看哪些算法可用于回归:
- 线性回归
- 随机森林
- 决策树
- 支持向量回归器
- k 最近邻
我们注意到,其中大多数也列在分类小节中。
3. 无监督学习
与监督学习相比,无监督学习包括处理未标记的数据。事实上,这些用例中的标签通常很难获得。例如,没有足够的数据知识或标签太昂贵。
此外,缺乏标签使得很难为经过训练的模型设定目标。因此,衡量结果是否准确很复杂。即使如此,多种技术也允许获得结果,从而更好地掌握数据。
3.1. 集群
聚类包括根据相似项目的某些特征发现这些项目的聚类。换句话说,这种技术有助于揭示数据中的模式。
例如,我们假设我们有由汽车组成的输入。此外,数据集没有标记,我们不知道它们的相似特征或特征集会导致什么集群。聚类分析模型将找到模式。作为说明,在下面介绍的案例中,它找到了一种使用各自颜色对汽车进行分组的方法:
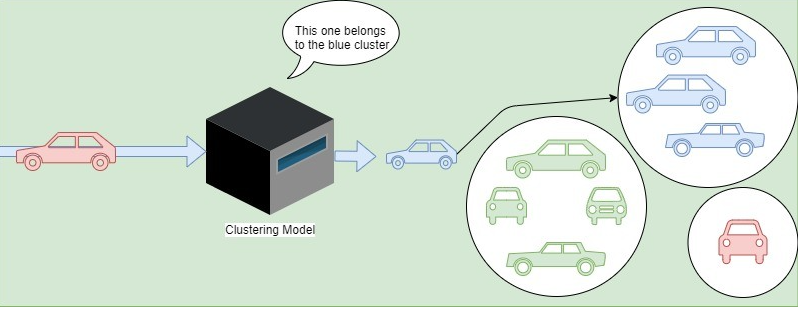
让我们发现一些聚类算法:
- k 均值聚类
- 分层聚类
3.2. 降维
维度是指数据集中的维度数。例如,维度可以表示特征或变量。它们描述数据集中的实体。
该技术的目标是检测不同维度之间的相关性。换句话说,它将帮助我们在数据集特征中找到冗余并减少冗余。例如,我们可以想到两个特征以不同的形式提供相同的信息。因此,算法将仅将其中一列保留在压缩子集中。
之后,我们将只保留所需的最小必要维度,而不会丢失任何关键信息。最后,这种技术有助于获得更好的数据集,优化进一步的训练步骤:
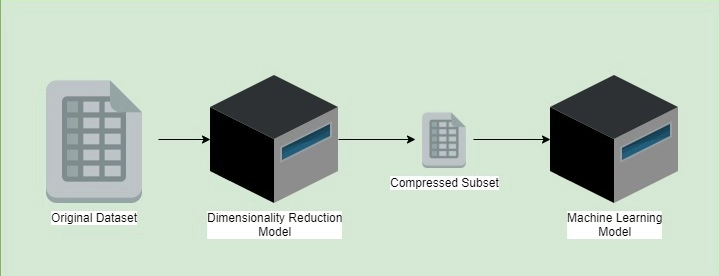
我们可以注意到降维算法的非详尽列表:
- 主成分分析
- 线性判别分析
- 广义判别分析
- 内核主成分分析
4. 半监督学习
与监督和无监督学习类似,半监督学习包括使用数据集。
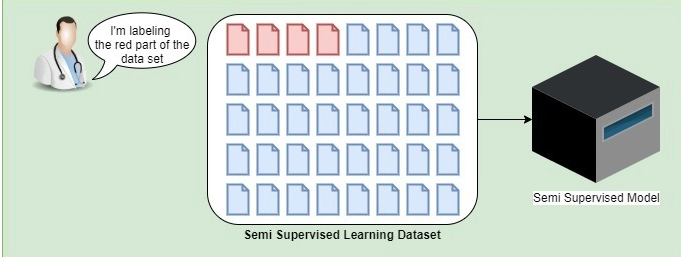
然而,半监督学习中的数据集分为两部分:标记部分和未标记部分。当标记数据或收集标记数据太难或太昂贵时,通常使用此技术。标记的部分数据也可能质量不佳。
例如,如果我们采用医学成像来检测癌症,那么让医生标记数据集是一项非常昂贵的任务。此外,这些医生还有其他更紧迫的工作要做。例如,在下面,我们可以看到医生标记了数据集的一部分,而将另一个数据集未标记。
最后,这种机器学习技术已被证明即使在数据集被部分标记的情况下也能表现出良好的准确性。
5. 强化学习
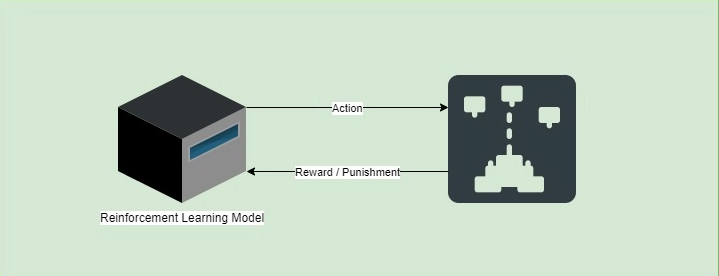
在强化学习中,系统只从一系列强化中学习。这些可以是与系统目标相关的正向关系,也可以是负数。积极的被称为“奖励”,而另一方面,我们将消极的称为“惩罚”。
例如,让我们以一个玩视频游戏的模型为例。当系统赢得更多积分时,它会获得奖励。但是,如果它输了,模型将受到惩罚。因此,模型可以确定哪些举措在战略方面是好的。
然后,这些移动的价值将相互相加,以建立短期策略和长期策略。因此,该模型将学习如何玩游戏并积累尽可能多的奖励。
最后,模型随着每个操作和奖励或每批操作和奖励而发展。
强化学习的一些算法是:
- SARSA
- Q 学习
- 汤普森采样
- 置信上限
- 蒙特卡洛树搜索
6. 如何选择合适的方法?
理想的通用算法不存在。每种算法都有其优点和缺点。根据用例和不同的因素,我们将选择一种或另一种算法。
让我们来看看选择算法时要考虑的一些非详尽的要点:
- 问题的类型 –考虑到要解决的问题,我们将选择一种已被证明可以为类似问题提供良好结果的算法。
- 可用样品数量 –一般来说,数据集越大越好,但有些算法在小数据集上也表现良好(例如朴素贝叶斯、KNeighbors 分类器、线性 SVC、SVR)
- 模型算法的复杂性与用于训练它的数据量相比——更准确地说,如果算法太复杂,但经过很少的数据训练,它将过于灵活,最终可能会过度拟合。
- 预期精度 –低准确性的机器学习模型可以比另一个旨在将损失降至最低的机器学习模型更快地获得训练
7. 结论
总之,我们已经发现了多种应用机器学习的技术。我们现在知道这些技术有不同的风格,但都有一个共同点:它们总是由数学和统计技术组成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号