
Java 中的线程池简介-Java快速进阶教程
1. 概述
本教程介绍了 Java 中的线程池。我们将从标准Java库中的不同实现开始,然后查看Google的Guava库。
2. 线程池
在 Java 中,线程映射到系统级线程,这些线程是操作系统的资源。如果我们不受控制地创建线程,我们可能会很快耗尽这些资源。
操作系统也会在线程之间进行上下文切换,以模拟并行性。一个简单的观点是,我们生成的线程越多,每个线程在实际工作上花费的时间就越少。
线程池模式有助于在多线程应用程序中节省资源,并将并行性包含在某些预定义的限制中。
当我们使用线程池时,我们以并行任务的形式编写并发代码,并将它们提交给线程池的实例执行。此实例控制多个重用的线程来执行这些任务。
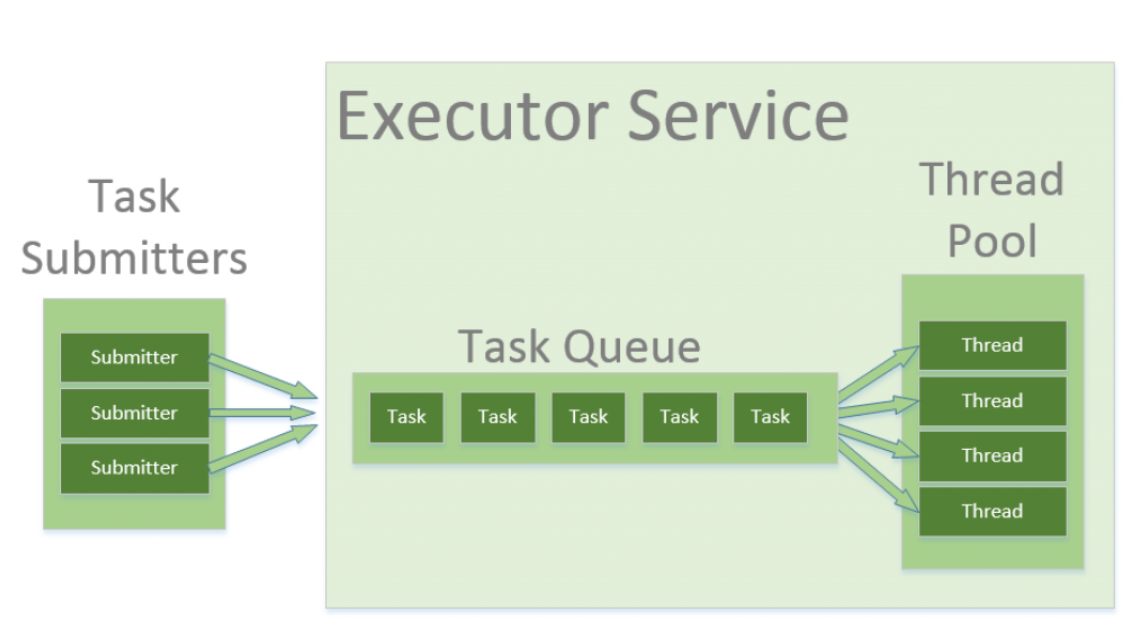
该模式允许我们控制应用程序创建的线程数及其生命周期。我们还能够安排任务的执行并将传入的任务保留在队列中。
3. Java 中的线程池
3.1.Executors, Executor 与ExecutorService
Executors helper类包含几个用于创建预配置线程池实例的方法。这些类方法是一个很好的开始。如果不需要应用任何自定义微调,就可以使用它们。
我们使用Executor和ExecutorService接口来处理Java中的不同线程池实现。通常,我们应该使代码与线程池的实际实现分离,并在整个应用程序中使用这些接口。
3.1.1.Executor
Executor接口有一个单独的执行方法来提交Runnable实例以供执行。
让我们看一个快速示例,了解如何使用Executors API获取由单个线程池和无限队列支持的Executor实例,以便按顺序执行任务。
在这里,我们运行一个简单的任务,在屏幕上打印“Hello World”。我们将以lambda (Java 8特性)的形式提交任务,它被推断为Runnable:
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Hello World"));3.1.2.ExecutorService
ExecutorService接口包含大量方法来控制任务的进度和管理服务的终止。使用此接口,我们可以提交要执行的任务,也可以使用返回的Future实例控制它们的执行。
现在我们将创建一个ExecutorService,提交一个任务,然后使用返回的Future 的get方法等待提交的任务完成并返回值:
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(() -> "Hello World");
// some operations
String result = future.get();当然,在现实生活中,我们通常不想立即调用future.get(),而是推迟调用它,直到我们真正需要计算的值。
在这里,我们重载提交方法以采用Runnable或Callable。这两者都是函数接口,我们可以将它们作为 lambda 传递(从 Java 8 开始)。
Runnable 的单一方法不会引发异常,也不会返回值。Callable接口可能更方便,因为它允许我们抛出异常并返回值。
最后,要让编译器推断Callable类型,只需从 lambda 返回一个值即可。
有关使用 ExecutorService 接口和Future接口的更多示例,请查看ExecutorService使用指南-Java快速入门教程 。
3.2.ThreadPoolExecutor
ThreadPoolExecutor是一个可扩展的线程池实现,具有许多用于微调的参数和钩子。
我们将在这里讨论的主要配置参数是corePoolSize,maximumPoolSize和keepAliveTime。
池由固定数量的核心线程组成,这些线程始终保存在内部。它还包含一些过多的线程,这些线程可能会生成,然后在不再需要它们时终止。
corePoolSize参数是将实例化并保留在池中的核心线程数。当有新任务进来时,如果所有核心线程都忙了,内部队列已满,则允许池增长到最大池大小。
keepAliveTime参数是允许过多线程(实例化超过corePoolSize)处于空闲状态的时间间隔。默认情况下,ThreadPoolExecutor仅考虑删除非核心线程。为了将相同的删除策略应用于核心线程,我们可以使用allowCoreThreadTimeOut(true) 方法。
这些参数涵盖了广泛的用例,但最典型的配置是在执行程序静态方法中预定义的。
3.2.1.newFixedThreadPool
让我们看一个例子。newFixedThreadPool方法创建一个具有相等 corePoolSize 和maximumPoolSize参数值以及零keepAliveTime 的ThreadPoolExecutor。这意味着此线程池中的线程数始终相同:
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newFixedThreadPool(2);
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(2, executor.getPoolSize());
assertEquals(1, executor.getQueue().size());在这里,我们实例化一个固定线程计数为 2 的ThreadPoolExecutor。这意味着,如果同时运行的任务数始终小于或等于 2,则它们会立即执行。否则,其中一些任务可能会被放入队列中以等待轮到它们。
我们创建了三个Callable任务,它们通过睡眠 1000 毫秒来模仿繁重的工作。前两个任务将同时运行,第三个任务必须在队列中等待。我们可以通过在提交任务后立即调用getPoolSize() 和getQueue().size() 方法来验证它。
3.2.2.Executors.newCachedThreadPool()
我们可以使用Executors.newCachedThreadPool()方法创建另一个预配置的ThreadPoolExecutor。此方法根本不接收多个线程。我们将 corePoolSize 设置为 0,并将maximumPoolSize设置为Integer。MAX_VALUE。最后,keepAliveTime是 60 秒:
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newCachedThreadPool();
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(3, executor.getPoolSize());
assertEquals(0, executor.getQueue().size());这些参数值意味着缓存的线程池可以无限制地增长,以容纳任意数量的提交任务。但是当不再需要线程时,它们将在 60 秒不活动后被处理掉。一个典型的用例是当我们的应用程序中有很多短期任务时。
队列大小将始终为零,因为内部使用了同步队列实例。在同步队列中,插入和删除操作对始终同时发生。因此,队列实际上从未包含任何内容。
3.2.3.Executors.newSingleThreadExecutor()
Executors.newSingleThreadExecutor()API 创建了包含单个线程的另一种典型形式的ThreadPoolExecutor。单线程执行器非常适合创建事件循环。corePoolSize 和maximumPoolSize参数等于 1,keepAliveTime为 0。
上面示例中的任务将按顺序运行,因此在任务完成后,标志值将为 2:
AtomicInteger counter = new AtomicInteger();
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() -> {
counter.set(1);
});
executor.submit(() -> {
counter.compareAndSet(1, 2);
});此外,此ThreadPoolExecutor使用不可变包装器进行装饰,因此在创建后无法重新配置。请注意,这也是我们无法将其强制转换为ThreadPoolExecutor 的原因。
3.3.ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 扩展了ThreadPoolExecutor类,并且还通过几个附加方法实现了ScheduledExecutorService接口:
- 计划方法允许我们在指定的延迟后运行一次任务。
- scheduleAtFixedRate方法允许我们在指定的初始延迟后运行任务,然后在一定时间段内重复运行它。period参数是在任务开始时间之间测量的时间,因此执行速率是固定的。
- scheduleWithFixedDelay方法与scheduleAtFixedRate类似,因为它重复运行给定的任务,但指定的延迟是在上一个任务结束和下一个任务开始之间测量的。执行速率可能会有所不同,具体取决于运行任何给定任务所需的时间。
我们通常使用 Executors.newScheduledThreadPool() 方法来创建一个具有给定 corePoolSize、无界maximumPoolSize和零keepAliveTime 的 ScheduledThreadPoolExecutor。
下面介绍如何安排任务在 500 毫秒内执行:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
executor.schedule(() -> {
System.out.println("Hello World");
}, 500, TimeUnit.MILLISECONDS);下面的代码演示如何在延迟 500 毫秒后运行任务,然后每 100 毫秒重复一次。计划任务后,我们使用CountDownLatch锁等待它触发三次。然后我们使用Future.cancel() 方法取消它:
CountDownLatch lock = new CountDownLatch(3);
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
ScheduledFuture<?> future = executor.scheduleAtFixedRate(() -> {
System.out.println("Hello World");
lock.countDown();
}, 500, 100, TimeUnit.MILLISECONDS);
lock.await(1000, TimeUnit.MILLISECONDS);
future.cancel(true);3.4.ForkJoinPool
ForkJoinPool是 Java 7 中引入的fork/join框架的核心部分。它解决了在递归算法中生成多个任务的常见问题。我们将使用简单的ThreadPoolExecutor 快速耗尽线程,因为每个任务或子任务都需要自己的线程才能运行。
在fork/join 框架中,任何任务都可以生成(fork)许多子任务,并使用join方法等待它们的完成。fork/join框架的好处是它不会为每个任务或子任务创建一个新线程,而是实现工作窃取算法。这个框架在我们的fork-join使用框架指南-Java快速入门教程 中有详尽的描述。
让我们看一个简单的示例,该示例使用ForkJoinPool遍历节点树并计算所有叶值的总和。下面是一个由节点、一个 int值和一组子节点组成的树的简单实现:
static class TreeNode {
int value;
Set<TreeNode> children;
TreeNode(int value, TreeNode... children) {
this.value = value;
this.children = Sets.newHashSet(children);
}
}现在,如果我们想并行地对树中的所有值求和,我们需要实现一个RecursiveTask<Integer>接口。每个任务接收自己的节点,并将其值添加到其子任务的值总和中。若要计算子值的总和,任务实现将执行以下操作:
- 流子集
- 映射在此流上,为每个元素创建一个新的计数任务
- 通过分叉来运行每个子任务
- 通过对每个分叉任务调用Join方法来收集结果
- 使用Collectors.summingInt收集器对结果求和
public static class CountingTask extends RecursiveTask<Integer> {
private final TreeNode node;
public CountingTask(TreeNode node) {
this.node = node;
}
@Override
protected Integer compute() {
return node.value + node.children.stream()
.map(childNode -> new CountingTask(childNode).fork())
.collect(Collectors.summingInt(ForkJoinTask::join));
}
}运行计算的代码非常简单:
TreeNode tree = new TreeNode(5,
new TreeNode(3), new TreeNode(2,
new TreeNode(2), new TreeNode(8)));
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
int sum = forkJoinPool.invoke(new CountingTask(tree));4. 线程池在Guava中的实现
guava是一个流行的谷歌实用程序库。它有许多有用的并发类,包括几个方便的ExecutorService 实现。实现类无法访问直接实例化或子类化,因此创建其实例的唯一入口点是MoreExecutors帮助程序类。4.1. 添加Guava作为 Maven 依赖项
我们将以下依赖项添加到 Maven pom 文件中,以将番石榴库包含在我们的项目中。在Maven中央存储库中找到最新版本的番石榴库:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>4.2. directExecutor和directExecutorService
有时我们希望在当前线程或线程池中运行任务,具体取决于某些条件。我们更愿意使用单个执行器接口,只切换实现。虽然想出一个在当前线程中运行任务的Executor 或 ExecutorService的实现并不难,但这仍然需要编写一些样板代码。
很高兴,Guava为我们提供了预定义的实例。
下面是一个示例,演示了在同一线程中执行任务。尽管提供的任务休眠 500 毫秒,但它会阻塞当前线程,并且在执行调用完成后立即提供结果:
Executor executor = MoreExecutors.directExecutor();
AtomicBoolean executed = new AtomicBoolean();
executor.execute(() -> {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
executed.set(true);
});
assertTrue(executed.get());directExecutor() 方法返回的实例实际上是一个静态单例,因此使用此方法根本不会在对象创建时提供任何开销。
我们应该更喜欢这种方法而不是MoreExecutors.newDirectExecutorService(),因为该 API 在每次调用时都会创建一个成熟的执行器服务实现。
4.3. 退出Executor Services
另一个常见问题是在线程池仍在运行其任务时关闭虚拟机。即使有取消机制,也不能保证任务在执行程序服务关闭时会表现良好并停止工作。这可能会导致 JVM 无限期挂起,而任务继续执行其工作。
为了解决这个问题,Guava引入了一系列现有的执行器服务。它们基于与 JVM 一起终止的守护进程线程。
这些服务还使用Runtime.getRuntime().addShutdownHook() 方法添加关闭挂钩,并防止 VM 在放弃挂起任务之前终止配置的时间量。
在以下示例中,我们将提交包含无限循环的任务,但我们使用配置时间为 100 毫秒的退出执行程序服务来等待 VM 终止时的任务。
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newFixedThreadPool(5);
ExecutorService executorService =
MoreExecutors.getExitingExecutorService(executor,
100, TimeUnit.MILLISECONDS);
executorService.submit(() -> {
while (true) {
}
});如果没有现有的执行程序服务,此任务将导致 VM 无限期挂起。
4.4. 侦听装饰器
侦听装饰器允许我们包装ExecutorService并在任务提交时接收ListenableFuture实例,而不是简单的Future实例。ListenableFuture接口扩展了Future,并具有一个附加方法addListener。此方法允许添加在将来完成时调用的侦听器。
我们很少想直接使用ListenableFuture.addListener() 方法。但它对于Futures实用程序类中的大多数帮助程序方法都是必不可少的。
例如,使用Futures.allAsList() 方法,我们可以将多个 ListenableFuture 实例组合到一个ListenableFuture中,该实例在成功完成所有组合的期货后完成:
ExecutorService executorService = Executors.newCachedThreadPool();
ListeningExecutorService listeningExecutorService =
MoreExecutors.listeningDecorator(executorService);
ListenableFuture<String> future1 =
listeningExecutorService.submit(() -> "Hello");
ListenableFuture<String> future2 =
listeningExecutorService.submit(() -> "World");
String greeting = Futures.allAsList(future1, future2).get()
.stream()
.collect(Collectors.joining(" "));
assertEquals("Hello World", greeting);
 浙公网安备 33010602011771号
浙公网安备 33010602011771号