摘要
在医学语义分割中,卷积操作的固有局部性,导致U型网络在建模长期依赖方面显示出局限性。transformer被设计用于序列到序列的预测,由于其固有的全局注意力机制,使其可作为可选网络结构。但transformer低级细节不足,可能导致本地化能力有限。
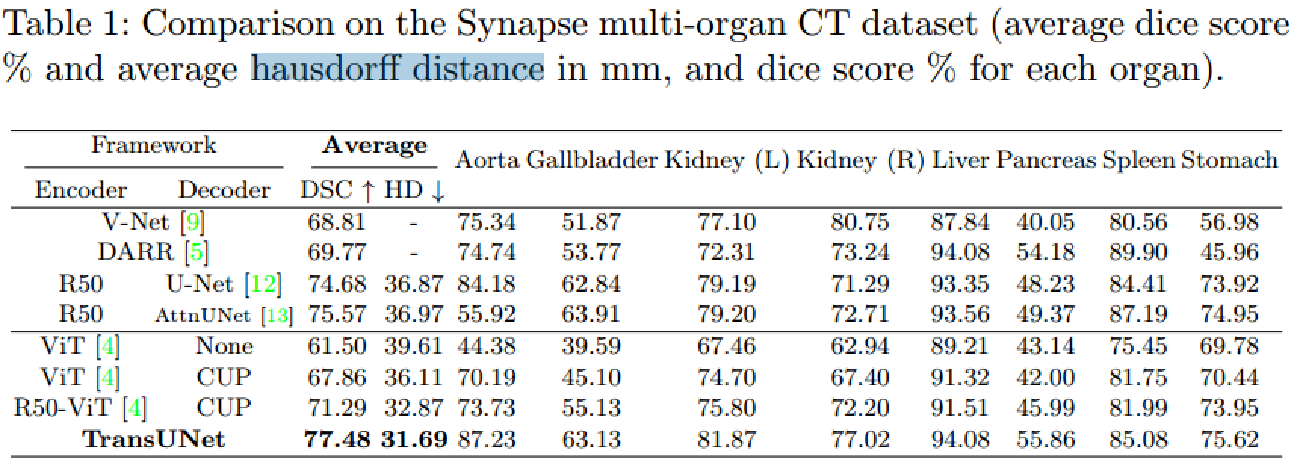
本文提出TransUNet,比transformer和Unet都要好,可作为医学图像分割的替代方案。transformer从cnn的特征图编码图像块,作为输入序列,用于提取全局特征。解码器上采样编码特征,与高分辨率CNN特征结合,进行精确定位。
代码已开源:https://github.com/Beckschen/TransUNet
方法
transformer作为编码器
-
图像序列化
与【4】相同,首先进行切分,将输入x变为平面的2维patch序列,每个patch大小PxP,数量N=(HW)/P2,即序列长度。
-
patch嵌入
使用可训练线性投影,将向量化的patch Xp映射到潜在的d维嵌入空间.
为编码patch空间信息,学习特定的位置嵌入,与patch嵌入相加,保留位置信息
![]()
E是Patch嵌入投影,Epos代表位置嵌入
transformer编码器由L层多头自注意力(MSA)和多层感知机块(MLP)组成,所以第l层的输出为:

LN代表层归一化,ZL是编码的图像表征,transformer层的结构如图1(a)所示。


TransUNet
利用一个混合了CNN-Transformer结构作为编码器,并且用一个级联的上采样器保证精确预测。
-
CNN-transformer混合作为编码器
CNN首先用于特征提取器产生一个特征图,作为输出。
patch嵌入应用到(CNN的)特征图对应的1x1的patches上,而不是原图。
-
级联的上采样器(CUP)
包含多个上采样步骤,以解码输入特征,用于输出最后的分割掩码。
在将隐藏特征序列![]() 变为H/P x H/P x D,我们通过级联多个上采样块来实现从H/P × W/P到H×W的全分辨率,每个块依次由一个2×上采样算子、3×3卷积层和ReLU层组成。
变为H/P x H/P x D,我们通过级联多个上采样块来实现从H/P × W/P到H×W的全分辨率,每个块依次由一个2×上采样算子、3×3卷积层和ReLU层组成。
我们可以看到,CUP和混合编码器形成了一个u型架构,通过跳过连接,可以在不同的分辨率级别上实现特征聚合。CUP的详细结构以及中间的跳跃连接如图1(b).
实验和讨论
实现细节:
简单数据增强:随机旋转和翻转
ViT:12层transformer层;
R50-ViT:ResNet-50和ViT
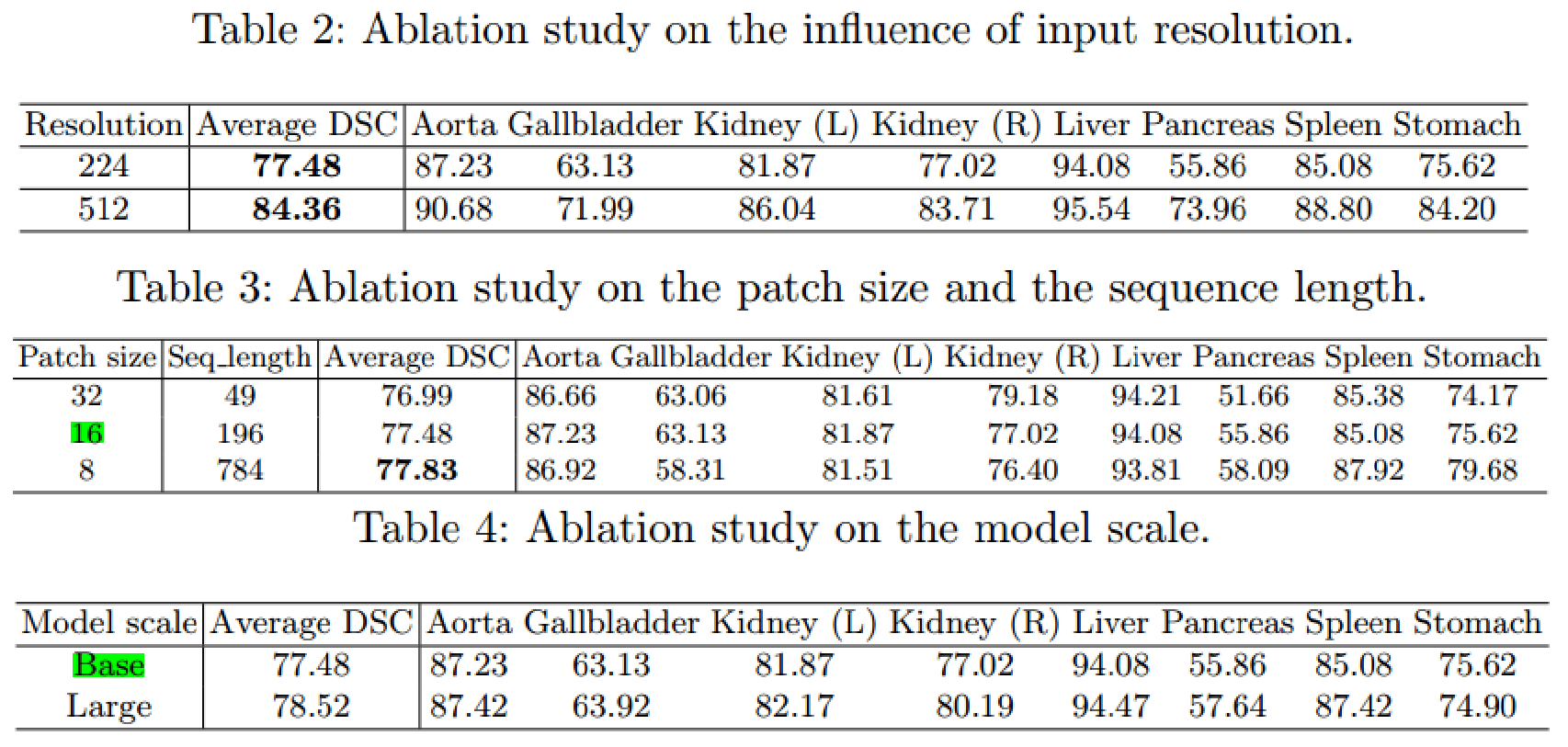
输入:224x224,patch为16x16
4个上采样块


公众号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号