

地址:https://github.com/yaoppeng/U-Net_v2/tree/master
1. 摘要
Unetv2的目的是增加注入到低级特征中的语义信息,同时用更精细的细节来精炼高级特征。我们的方法可以无缝集成到任何编码器-解码器网络中。在几个公共医学分割数据集上评估了皮肤损伤分割和息肉分割,实验结果证明该方法的分割精度超过了最先进的方法,同时保持了内存和计算效率。
2. 方法
2.1 整体结构
unet v2的整体结构如下图,包含编码器、SDI(semantic and detail infusion)模块和解码器三部分:
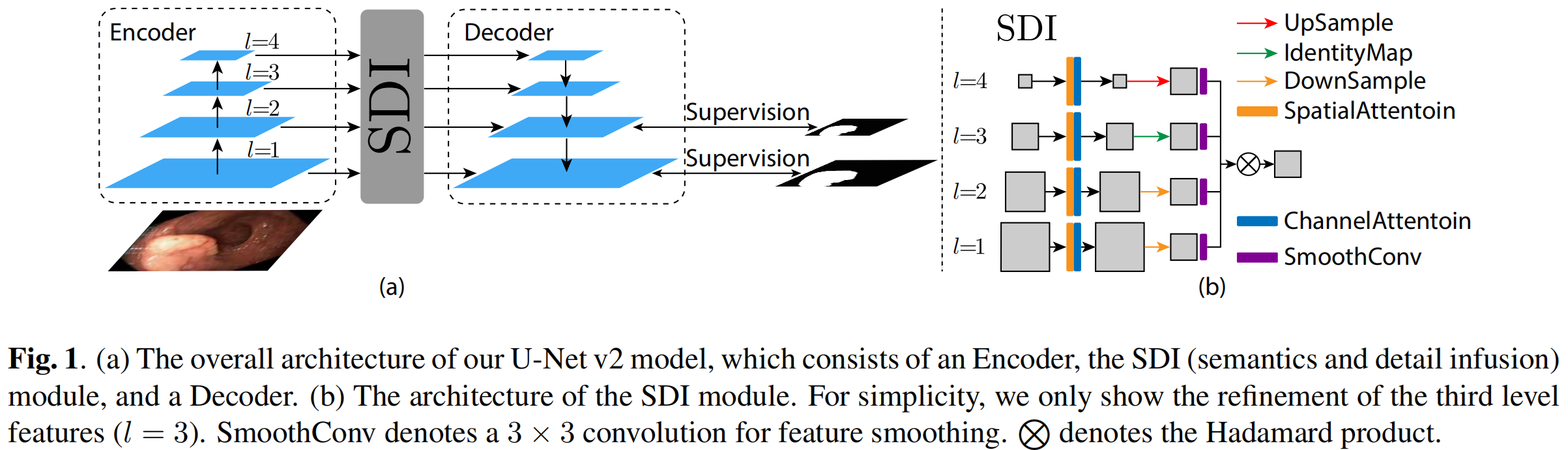
编码器输出的M级特征传到SDI以更进一步精炼。
2.2 SDI模块
首先,在第i级特征上应用空间和通道注意力机制,制,以集成局部空间信息和全局channel信息,然后利用1x1卷积将通道降至c(c为超参),得到的结果图表示为fi2,将decoder的每个level的特征图都调整至fi2大小,表示为:
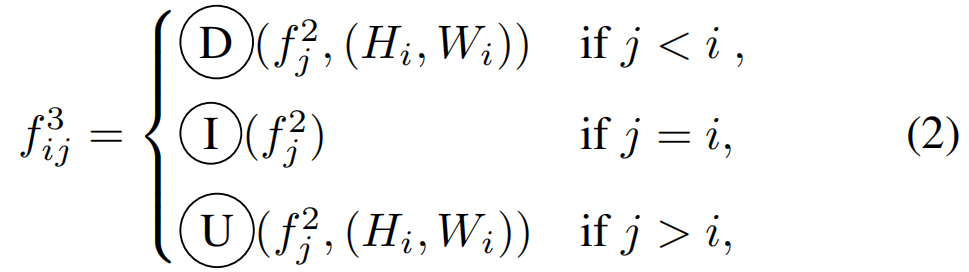
D表示平均池化,I表示恒等映射,U代表双线性插值,之后采用3x3卷积平和每个特征图f3ij,之后采用Hadamard product到所有特征图以用更多语义信息和精细细节增强第i个级别的特征图,表示为:
![]()
然后,fi5被发送到第i级解码器进行进一步的分辨率重建和分割。
3. 实验
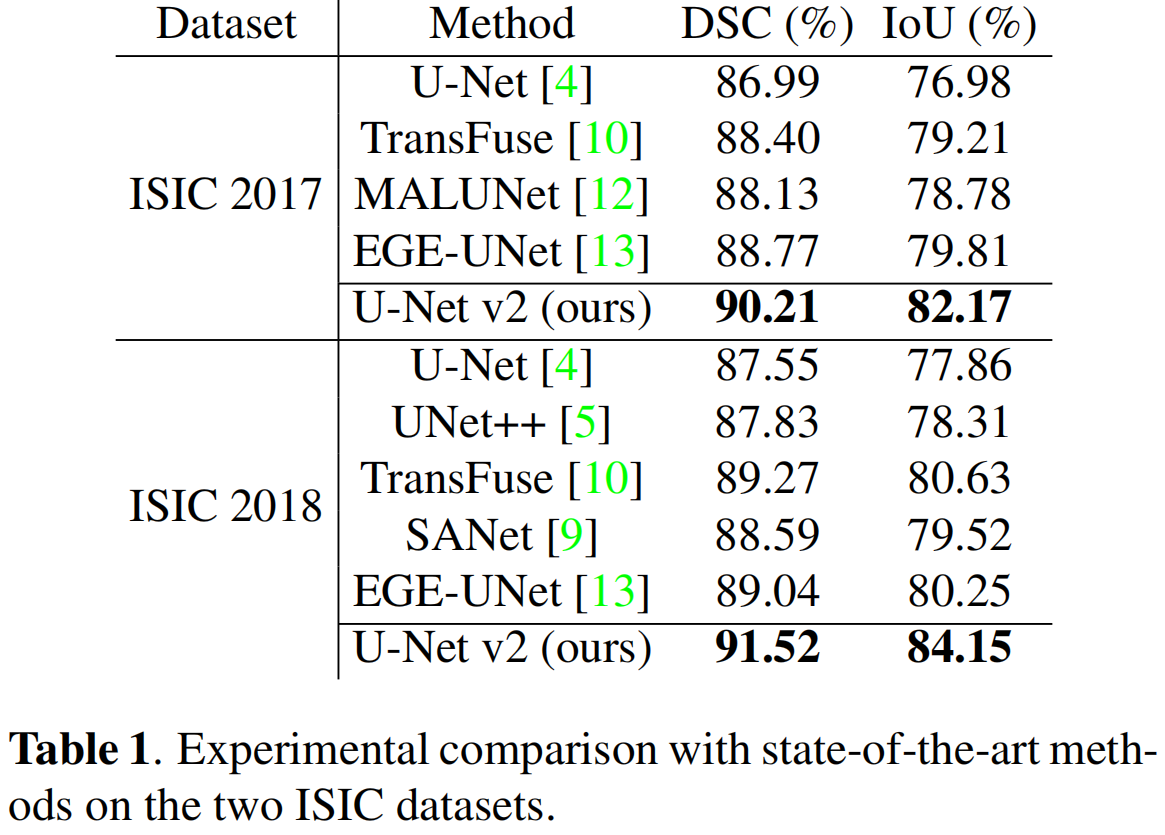



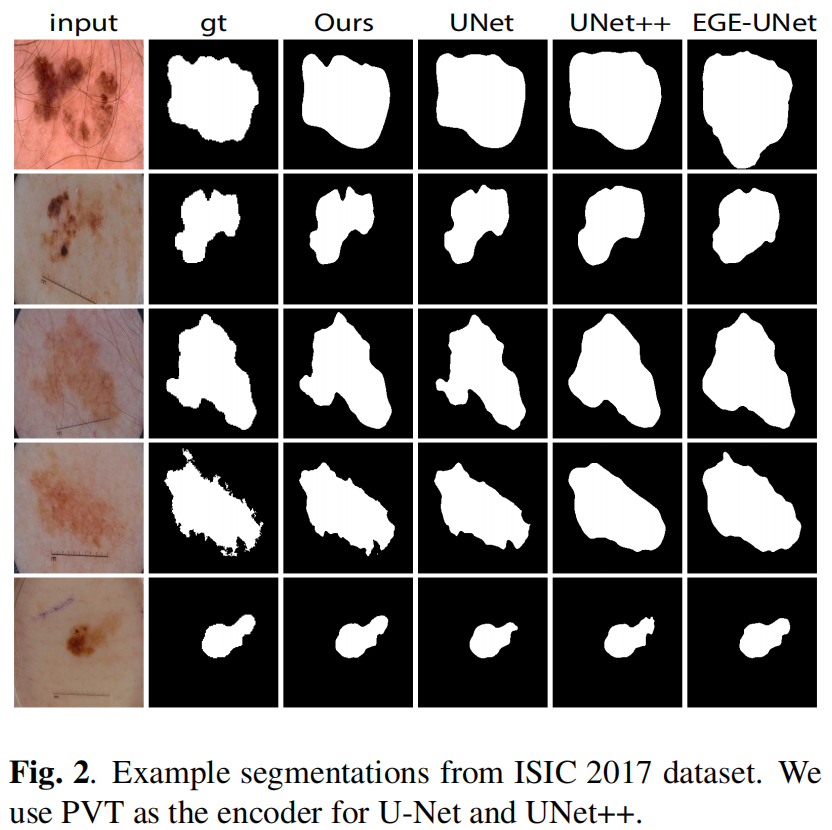
通道注意力、空间注意力以及SDI模块代码如下:
代码转自https://github.com/yaoppeng/U-Net_v2/blob/master/unet_v2/UNet_v2.py
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class SDI(nn.Module):
def __init__(self, channel):
super().__init__()
self.convs = nn.ModuleList(
[nn.Conv2d(channel, channel, kernel_size=3, stride=1, padding=1)] * 4)
def forward(self, xs, anchor):
ans = torch.ones_like(anchor)
target_size = anchor.shape[-1]
for i, x in enumerate(xs):
if x.shape[-1] > target_size:
x = F.adaptive_avg_pool2d(x, (target_size, target_size))
elif x.shape[-1] < target_size:
x = F.interpolate(x, size=(target_size, target_size),
mode='bilinear', align_corners=True)
ans = ans * self.convs[i](x)
return ans


 浙公网安备 33010602011771号
浙公网安备 33010602011771号