PaddleHub(3)
PaddleHub实战——使用语义预训练模型ERNIE优化信息抽取
1、引入
本项目目的在于从物流信息中抽取想要的关键信息如姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。在此之前,我们需要考虑如何表示出我们想要的结果,在这里我们需要运用到序列标注模型来解决这一问题,常见的序列标注模型是LSTM+CRF。但是此次我们运用的为BIO体系,在序列标注任务中,一般会定义一个标签集合,来表示所以可能取到的预测结果。在本案例中,针对需要被抽取的“姓名、电话、省、市、区、详细地址”等实体,标签集合可以定义为:label = {P-B, P-I, T-B, T-I, A1-B, A1-I, A2-B, A2-I, A3-B, A3-I, A4-B, A4-I, O}。每个标签的定义分别为:P-B:姓名起始位置、P-I:姓名中间位置或结束位置、T-B:电话起始位置、T-I:电话中间位置或结束位置、A1-B:省份起始位置、A1-I:省份中间位置或结束位置、A2-B:城市起始位置、A2-I:城市中间位置或结束位置、A3-B:县区起始位置、A3-I:县区中间位置或结束位置、A4-B:详细地址起始位置、A4-I:详细地址中间位置或结束位置、O:不关注的字。
项目链接:
http://aistudio.baidu.com/aistudio/projectdetail/184200
2、语义预训练模型ERNIE优化信息抽取
百度的预训练模型ERNIE经过海量的数据训练后,其特征抽取的工作已经做的非常好。借鉴迁移学习的思想,我们可以利用其在海量数据中学习的语义信息辅助小数据集(如本示例中的快递单数据集)上的任务。

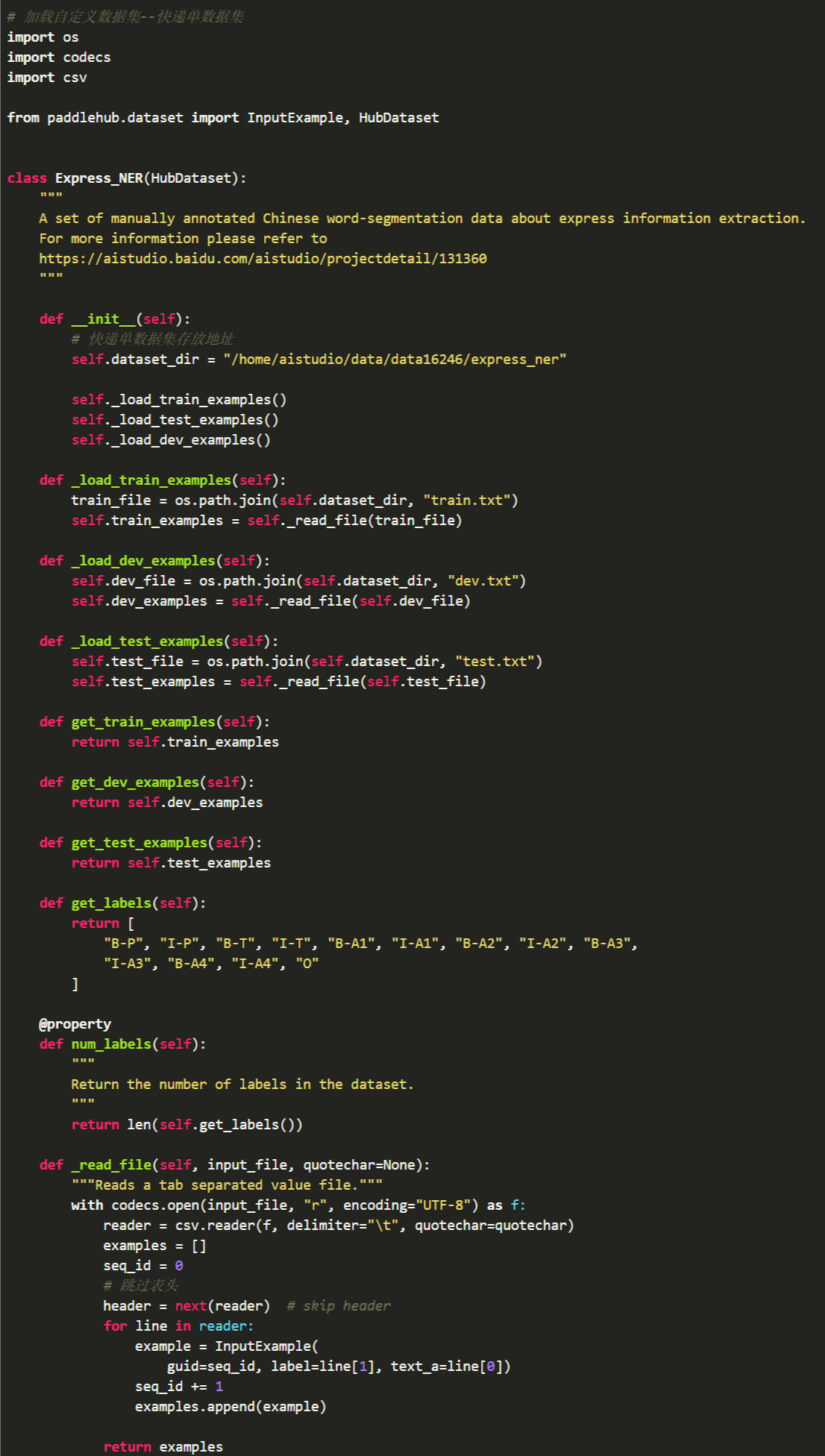
- PaddleHub加载自定义数据集
加载文本类自定义数据集,仅需要继承HubDataset类,替换数据集存放地址即可。此处将自定义数据集加载进PaddleHub使用,这样我们只需要在小数据集上微调(Fine-tune)预训练模型即可。

- PaddleHub一键加载ERNIE

- 构建Reader
生成一个序列标注的reader,reader负责将dataset的数据进行预处理,首先对文本进行切词,接着以特定格式组织并输入给模型进行训练。

- 组建Finetune Task
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个Task。

- 开始Finetune
我们选择finetune_and_eval接口来进行模型训练,这个接口在finetune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。
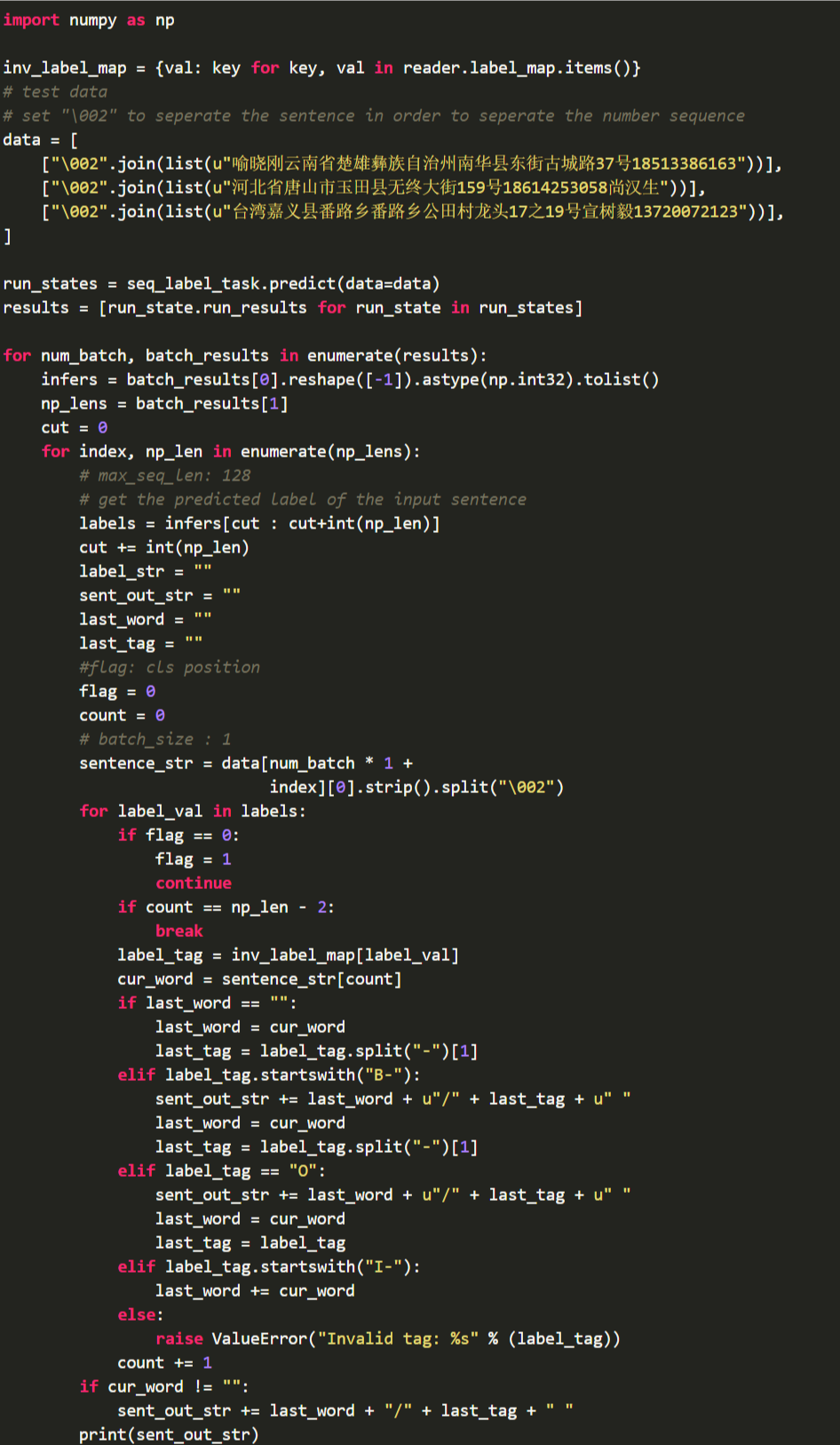
3、使用模型进行预测
当Finetune完成后,我们使用模型来进行预测,整个预测流程大致可以分为以下几步:
- 构建网络
- 生成预测数据的Reader
- 切换到预测的Program
- 加载预训练好的参数
- 运行Program进行预测
4、总结与收获
通过本次实践活动,我了解了一个关于人工智能方面学习与实训的社区——AI Studio,在经过一系列的学习与操作后,我感受到了在此中进行学习的便捷,AI Studio作为目前中国最大的人工智能开发者社区,集开放数据、开源算法、免费算力三位一体,为开发者了提供高效学习和开发研究的环境以及高价值高奖金竞赛项目,同时PaddleHub也为我们提供了可运用的预训练模型等大量学习与实训的资源。
我们需要深入学习相关专业知识,也要学会运用已有资源进行实际训练。此次活动,表现多有不足,在今后的日子里仍然需要加深对相关知识的了解与应用,同时需要增加有关Python语法及运用的练习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号