前端犄角旮旯,非常规面试题总结(不断更新....)
前段时间面试了一个大厂,被问了一些犄角旮旯的面试题,整场下来,一脸懵逼,决定痛定思痛,把这些题总结下来,不断更新。每天一遍,每天进步。。。
1、npm cnpm yarn pnpm的区别,各自的优势是什么? 你项目中用的什么?
首先说一下Node.js,简单的说 Node.js 就是运行在服务端的 JavaScript。node通过更改连接到服务器的方式,可以处理高并发任务。
npm:
nodejs的包管理器,用于node插件管理(包括安装、卸载、管理依赖等)
npm安装速度慢的一个重要原因:npm远程服务器在国外,必须首先遍历所有的项目依赖关系,然后再决定如何生成扁平化的node_modules结构。不过,npm有本地缓存,它保存了已经下载的每个版本的压缩包,缓存可以减少安装时间。
yarn
像npm一样,yarn使用本地缓存。与npm不同的是,yarn无需互联网连接就能安装本地缓存的依赖项,它提供了离线模式。
Yarn Workspaces(工作区)是Yarn提供的monorepo的依赖管理机制,从Yarn 1.0开始默认支持,用于在代码仓库的根目录下管理多个package的依赖。
Workspace 能更好的统一管理有多个项目的仓库,既可在每个项目下使用独立的 package.json 管理依赖,又可便利的享受一条 yarn命令安装或者升级所有依赖等。更重要的是可以使多个项目共享同一个 node_modules目录,提升开发效率和降低磁盘空间占用。
pnpm
利用硬链接和符号链接来避免复制本地缓存源文件,继承了yarn的所有优点,包括离线模式和确定性安装.内部基于内容寻址的文件系统存储磁盘上所有的文件:1.不会重复安装同一个包。2.即使包的不同版本,pnpm也会极大程度的复用之前版本的代码。
对比其优劣势
npm
node_modules扁平化结构
支持workspace,大部分开发人员用npm也能很好的打包
逐行安装(速度较慢)
问题:幻影依赖,依赖分身
yarn
node_modules扁平化解构
支持workspace,monorepo
yarn主要为了解决语义版本控制而导致npm安装不确定的问题,由yarn.lock文件,不过npm也出了package-lock文件
并行安装(速度较快)
问题:幻影依赖,依赖分身
pnpm
pnpm采用内存寻址存储的方法,通过软硬链接引用依赖,实现node_modules非扁平化结构,
支持workspace,monorepo,速度快,磁盘占用空间小(速度最快)
通过内容寻址存储解决了幻影依赖,依赖分身的问题,安全性高。
pnpm 的安装速度在大多数场景都比 npm 和 yarn 快 2 倍,节省的磁盘空间也更多。
问题:
因为依赖源文件是安装在 store 中,调试依赖或 patch-package 给依赖打补丁也不太方便,可能会影响其他项目。
由于 pnpm 创建的 node_modules 依赖软链接,因此在不支持软链接的环境中,无法使用 pnpm,比如 Electron 应用。
2、devDependencies、dependencies,peerDependencies的区别
npm install mypack & npm install mypack -save 将 mypack安装到node_modules目录下,并且将该包名放入package.json下的dependencies中
npm install mypack -save-dev 将 mypack安装到node_modules目录下,并且将该包名放入package.json下的devdependencies中
npm install mypack -g 将 mypack安装你 node 的安装目录 及 全局目录。该包名不放入package.json中,可以直接在命令行里使用。如npm
dependencies 字段中指定的是项目运行时需要的依赖包,也就是生产环境下需要的依赖。这些依赖将会被安装在生产环境中,并被打包进最终的发布版本中。一般来说,这些依赖是指与项目密切相关的库和框架,比如 express、lodash、axios 等。当我们使用 npm install 安装项目时,dependencies 中指定的依赖包也会被自动安装。使用场景:适用于项目的主要功能模块、框架以及必要的第三方库。这些依赖项会随着应用程序一起部署,并在生产环境中运行。
devDependencies 字段中指定的是开发环境下所需的依赖包。这些依赖通常是开发人员在编写和测试代码时使用的,而不会被打包到最终的发布版本中。一般来说,这些依赖包是用于构建、测试、调试等用途,比如 Babel、Webpack、Mocha 等。当我们使用 npm install 安装项目时,devDependencies 中指定的依赖包不会被安装。若需要安装 devDependencies 中的依赖,需要使用 npm install --dev。使用场景:适用于开发过程中的辅助工具、测试框架、构建工具、代码质量检查工具等。这些依赖项不会影响应用程序的实际运行,只在开发环境中使用。
peerDependencies 字段中指定的是项目所依赖的其他包的版本号范围。这些依赖会要求安装方在安装项目时手动安装所需要的版本。peerDependencies 通常用于告知用户项目运行时所依赖的某些库或框架的版本,而且这些库或框架已经被全局安装或者被安装在项目外面。peerDependencies 可以确保安装的库版本与项目所依赖的版本一致,从而减少版本兼容性问题。
使用场景:
开发库或模块依赖特定版本的外部库:如果你正在开发一个库或模块,它依赖于外部库的特定版本来实现某些功能,但你不希望将这些外部库包含在你的库中,那么你可以在你的 package.json 中指定这些外部库为 peerDependencies。
版本兼容性:有时,不同的库可能依赖于同一个外部库的不同版本,这可能导致版本冲突。通过在你的库中使用 peerDependencies,你可以确保使用者在安装你的库时会同时满足这些依赖项的版本要求,从而避免版本冲突。
库的可插拔性:如果你的库需要与其他库或模块协同工作,而这些库或模块可能在项目中以插件或扩展的形式存在,你可以使用 peerDependencies 来确保插件与你的库兼容。
提供建议性的依赖项:有时候,你可能希望为使用者提供一些建议性的依赖项,虽然这些依赖项不是强制性的。在这种情况下,你可以将这些依赖项列为 peerDependencies,使用者可以根据自己的需求来决定是否安装。
使用 peerDependencies 时需要注意以下几点:
使用 peerDependencies 不会自动安装依赖项,它只是告诉使用者需要安装这些外部依赖项,并确保版本兼容性。
使用 peerDependencies 时,使用者需要手动安装符合要求的外部依赖项,以便与你的库或模块正常工作。
为了避免冲突和混淆,建议在文档中清楚地说明使用者需要安装的外部依赖项以及版本要求。
3、生产环境,开发环境,测试环境等不同的环境的面试题
开发环境:
开发环境时程序猿们专门用于开发的服务器,配置可以比较随意,为了开发调试方便,一般打开全部错误报告和测试工具,是最基础的环境。开发环境的分支,一般是feature分支。
测试环境
一般是克隆一份生产环境的配置,一个程序在测试环境工作不正常,那么肯定不能把它发布到生产服务器上,是开发环境到生产环境的过度环境。测试环境的分支一般是develop分支,部署到公司私有的服务器或者局域网服务器上,主要用于测试是否存在bug,一般会不让用户和其他人看到,并且测试环境会尽量与生产环境相似。
生产环境
生产环境是指正式提供对外服务的,一般会关掉错误报告,打开错误日志,是最重要的环境。部署分支一般为master分支。
上述环境也可以说是系统开发的三个阶段:开发->测试->上线,其中生产环境也就是通产说的真实的环境,最后交给用户的环境。
如何在Vue中丝滑的切换环境呢?
- 在根目录建立.env系列文件
- .env.development(开发环境,用于serve启动的项目)
- .env.production(生产环境,用于build打包的项目)
- .env.test(测试环境)
//在文件中可以配置下面的变量 后面写请求服务器的地址
VUE_APP_BASE_API = '需要请求API'
1 //对应的 "scripts": 2 "dev": "vue-cli-service serve", 对应开发环境 3 "test": "vue-cli-service serve --mode test", 对应测试环境 4 "build": "vue-cli-service build", 对应生产环境 5 "build:test": "vue-cli-service build --mode test",对应测试环境
在vue中使用的话可以直接使用 process.env.VUE_APP_BASE_API 进行取值,也就是我们预先配置好的请求地址
1 const service = axios.create({ 2 baseURL: process.env.VUE_APP_BASE_API, 3 timeout: 10000, 4 })
生产环境中如何调试,如何查找报错对应的位置?
(1)服务器通过搜索生产环境的日志
在方法开头和结尾或者在catch中抓取写日志log。这种方式适合小范围集群或者单体服务,绝对不适用大量集群的情况,大量集群日志会分散到多个服务器,
具体调用哪台服务器根本就不知道,所以成本很高。
(2)SoueceMap
虽然map文件提供了便利,但是在生产环境,为了安全,是建议关闭SourceMap的,因为通过.map文件和编译后代码可以很容易反编译出项目的源码,这样就相当于泄露了项目的代码。
生产环境的代码,经过压缩、编译,很不利于debug。由于生产环境没有配置SourceMap,所以代码报错时,或是通过Fundebug,Sentry等工具搜集到的报错信息,得到报错代码的行和列都是编译后的代码,这样很不易于定位问题。针对这个问题,需要准备一份生产环境代码的map文件,为了方便,可以在项目的package.json增加debug命令用来生成map文件。这条命令除了开启sourcemap,其他的具体webpack配置和生产环境配置相同。
1 "scripts": {
2 "start": "vue-cli-service serve --mode dev",
3 "stage": "vue-cli-service build --mode staging",
4 "online": "vue-cli-service build",
5 "debug": "vue-cli-service build --mode debug"
6 },
有了map文件,通过SourceMap提供的API就可以定位到源码的位置。下面是实现的核心代码。
1 // Get file content
2 const sourceMap = require('source-map');
3 const readFile = function (filePath) {
4 return new Promise(function (resolve, reject) {
5 fs.readFile(filePath, {encoding:'utf-8'}, function(error, data) {
6 if (error) {
7 console.log(error)
8 return reject(error);
9 }
10 resolve(JSON.parse(data));
11 });
12 });
13 };
14
15 // Find the source location
16 async function searchSource(filePath, line, column) {
17 const rawSourceMap = await readFile(filePath)
18 const consumer = await new sourceMap.SourceMapConsumer(rawSourceMap);
19 const res = consumer.originalPositionFor({
20 'line' : line,
21 'column' : column
22 });
23 consumer.destroy()
24 return res
25 }
最重要的就是使用SourceMap提供的 originalPositionFor API。 SourceMapConsumer.prototype.originalPositionFor(generatedPosition)
originalPositionFor API的参数为一个包含line和column属性的对象
line 编译生成代码的行号,从1开始
column 编译生成代码的列号,从0开始
这个方法会返回一个具有以下属性的对象
1 { source: 'webpack:///src/pages/common/403.vue?c891', // 源代码文件的位置,如果无法获取,返回null。
2 line: 4, // 源代码的行号,从1开始,如果无法获取,返回null。
3 column: 24, // 源代码的列号,从0开始,如果无法获取,返回null。
4 name: 'get' // 源代码的标识,如果无法获取,返回null。
5 }
4、库的版本问题
(1)版本号前面的“^”和“~”代表什么:
“^”它表示尽量使用最新版本,但保证不产生兼容问题。
~符号,表示版本号只能改变最末尾那段(如果是 ~x.y 末尾就是 y,如果是 ~x.y.z 末尾就是 z),比如这种情况:~1.2 等于 >=1.2.0; <2.0.0
因为0的特殊性所以如果你要指定 0 开头的库那一定要注意:~0.1 这种写法是很危险的,因为 ~0.1 等于 >=0.1.0; <1.0.0,可能出现无法向下兼容的情况,比较保险的写法还是:^0.1(等于 >=0.1.0; <0.2.0)
(2)改变版本号怎么做
npm version 命令用于更改版本号的信息,并执行commit 操作;该命令执行后, package.json 里的 version 会自动更新。
一般来说,当版本有较大改动时,变更第一位, 执行命令:npm version major -m "description" , 例如1.0.0 -> 2.0.0;
当前包变动较小时,可变更第二位,执行命令:npm version minor -m "description", 例如: 1.0.0 -> 1.1.0;
当前包只是修复了些问题时,可变更第三位,执行命令:npm version patch -m "description", 例如: 1.0.0 -> 1.0.1;
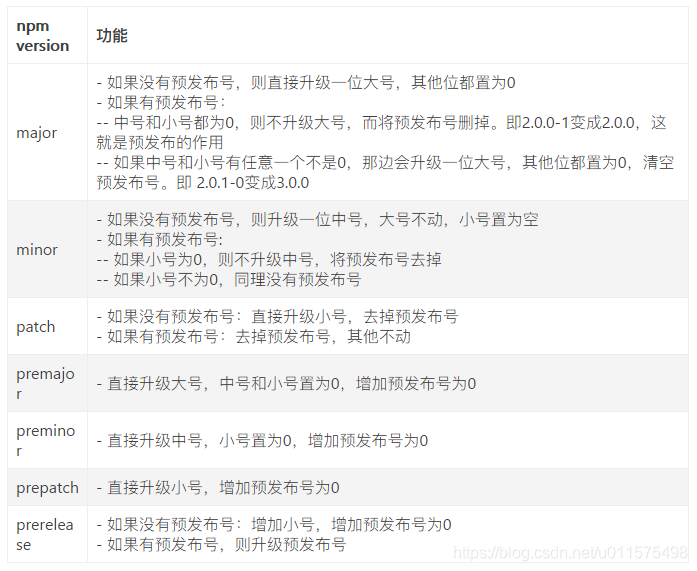
(3)pack.json的配置有哪些?
- 描述配置 主要是项目的基本信息,包括名称,版本,描述,仓库,作者等,部分会展示在 npm 官网上。
- 文件配置 包括项目所包含的文件,以及入口等信息。
- 脚本配置
命令行方式启动预设置的脚本 - 依赖配置 项目依赖其他包引用的相关信息。
- 发布配置 主要是和项目发布相关的配置。
- 系统配置 和项目关联的系统配置,比如 node 版本或操作系统兼容性之类。这些要求只会起到提示警告的作用,即使用户的环境不符合要求,也不影响安装依赖包。
- 第三方配置 一些第三方库或应用在进行某些内部处理时会依赖这些字段,使用它们时需要安装对应的第三方库。
5、有关提升项目性能的方案

1、减少 HTTP 请求次数:可以使用雪碧图、图片压缩等方法,减少静态资源的 HTTP 请求次数。
2、浏览器缓存:在合适的情况下,使用浏览器缓存可以显著减少请求时间,提高页面加载速度。
通过设置 http 头信息,可用的参数如下:其中 Expires 和 Cache-control 属于强缓存;Last-Modified/If-Modified-Since 和 Etag/If-None-Match 属于协商缓存。
* Expires
* Cache-control
* Last-Modified/If-Modified-Since
* Etag/If-None-Match
3、使用 CDN 加速:使用 CDN 加速可以将静态资源分发到多个节点,减少请求延迟,提高页面加载速度。
(1)、进行webpack的配置,将一些基本的npm包放在了CDN服务器上
(2)注入cdn变量 由于在开发环境时,文件资源还是可以从本地 node_modules 中取出,而只有项目上线了,才需要去使用外部资源。此时我们可以使用环境变量来进行区分。
(3)注入CDN配置到html模板 之后通过 html-webpack-plugin注入到 index.html之中:
4、延迟加载组件:对于一些比较耗时的组件,可以使用懒加载的方式,等到用户需要使用的时候再加载,避免在页面加载时一次性请求过多资源导致页面卡顿。
5、使用 Webpack 进行打包和压缩:Webpack 可以将多个 JS、CSS 文件打包成一个文件,减少 HTTP 请求次数;同时还可以进行代码压缩,减少文件大小,提高页面加载速度。
(1)下载压缩相关的库
1 # js 压缩 2 npm install uglifyjs-webpack-plugin --save-dev 3 # css提取 4 npm install mini-css-extract-plugin --save-dev 5 # css压缩 6 npm install css-minimizer-webpack-plugin --save-dev 7 # 读取环境变量 8 npm install cross-env --save-dev
(2)配置 webpack.config.js
1 const path = require("path") 2 const webpack = require("webpack") 3 const HtmlWebpackPlugin = require('html-webpack-plugin') // 生成html入口文件 4 const {CleanWebpackPlugin} = require('clean-webpack-plugin') // 编译文件时,清理 build/dist 目录,再生成新的 5 6 const MiniCssExtractPlugin = require('mini-css-extract-plugin'); 7 const CssMinimizerPlugin = require("css-minimizer-webpack-plugin"); 8 const UglifyJsPlugin = require('uglifyjs-webpack-plugin'); 11 const isProduction = process.env.NODE_ENV === "production" 12 const isDevelopment = process.env.NODE_ENV === "development" 13 console.log("print env: ", isProduction) 14 15 module.exports = { 16 entry: { 17 app: path.resolve(__dirname, "src/index.tsx"), 18 }, 19 mode: "development", 20 module: { 21 rules: [ 22 { 23 test: /\.(js|jsx|ts|tsx)$/, 24 exclude: /node_modules/, 25 use: [ 26 { 27 loader: "babel-loader", 28 options: { 29 presets: [ 30 [ 31 "@babel/preset-env", 32 // 配置信息 33 { 34 targets: { 35 "chrome": "58", 36 "ie": "11", 37 }, 38 // 指定 corejs 的版本 39 "corejs": "3", 40 // 使用 corejs 的方式 "usage" 表示按需加载 41 "useBuiltIns": "usage" 42 } 43 ], 44 [ 45 "@babel/preset-typescript", 46 ], 47 [ 48 "@babel/preset-react", 49 {} 50 ] 51 ] 52 } 53 }, 54 { 55 loader: "ts-loader" // 1. 先加载ts 56 } 57 ], 58 }, 59 { 60 test: /\.(css|scss)$/, 61 use: [ 62 63 { 64 loader: process.env.NODE_ENV === "production" 65 ? MiniCssExtractPlugin.loader // 提取css到文件中,放到head中 66 : "style-loader", // 4. 加载样式文件到head 67 68 }, 69 { 70 loader: "css-loader", // 3. 加载css 71 options: { 72 importLoaders: 1, 73 sourceMap: true 74 } 75 }, 76 { 77 loader: "postcss-loader", // 2. 加载postcss(项目里配置的是 autoprefixer 和 px2rem) 转换 css里的rem和厂商前缀 78 options: { 79 postcssOptions: { 80 config: path.resolve(__dirname, 'postcss.config.js') 81 }, 82 sourceMap: true 83 } 84 }, 85 { 86 loader: "sass-loader", // 1. 加载 scss 转换成css 87 options: { 88 sourceMap: true 89 } 90 } 91 ] 92 }, 93 // { 94 // test: /\.(png|jpg|gif)$/, 95 // use: [ 96 // { 97 // loader: 'file-loader', 98 // options: { 99 // name: '[sha512:hash:base64:7].[ext]' 100 // } 101 // } 102 // ] 103 // } // by junfenghe 2021-12-06 104 { 105 test: /\.(png|jpg|gif|ico)$/, 106 type: 'asset/resource', 107 generator: { 108 filename: 'static/media/[hash][ext][query]' 109 } 110 }, 111 { 112 test: /\.svg/, 113 type: 'asset/inline' 114 }, 115 // 20230216 打包html中的图片 116 { 117 test: /\.(htm|html)$/i, 118 loader: "html-withimg-loader" 119 } 120 // { 121 // test: /\.(txt|pdf|excel)$/, 122 // type: 'asset/source' 123 // } 124 ] 125 }, 126 resolve: { 127 extensions: ["*", ".js", ".jsx", ".ts", ".tsx"], // 尝试按顺序解析这些后缀名。能够用户再引入模块时不带扩展,例如:import File from '../path/to/file' 128 }, 129 output: { 130 path: path.resolve(__dirname, "build"), // 文件输出的路径 131 // filename: "bundle.js", //对于单一入口(entry point)起点,filename 会是一个静态名称; 132 filename: "static/js/[name].[fullhash].bundle.js", // 决定了每个输出 bundle 的名称。这些 bundle 将写入到 output.path 选项指定的目录下。// 当通过多个入口起点(entry point)、代码拆分(code splitting)或各种插件(plugin) 创建多个 bundle,应该赋予每个 bundle 一个唯一的名称 133 assetModuleFilename: "images/[hash][ext][query]" // by junfenghe 2021-12-06 // by junfenghe 20221228 134 }, 135 //20230216 136 optimization: { 137 minimizer: [ 138 // 在 webpack@5 中,你可以使用 `...` 语法来扩展现有的 minimizer(即 `terser-webpack-plugin`),将下一行取消注释 139 `...`, 140 new CssMinimizerPlugin({ 141 parallel: true,//使用多进程并发执行, 142 minimizerOptions:{ 143 preset:[ 144 "default", 145 { 146 discardComments: {removeAll:true},//移除所有注释 147 }, 148 ] 149 } 150 }), 151 ] 152 }, 153 //20230216 154 plugins: [ 155 new HtmlWebpackPlugin({ 156 template: path.join(__dirname, 'public/index.html') 157 }), 158 new CleanWebpackPlugin({ 159 path: path.join(__dirname, 'build') 160 }), 161 // // 20230216 代码压缩 162 // new UglifyJsPlugin({ 163 // parallel: true,// 使用多进程并行以提高构建速度 164 // sourceMap: true,// 使用源映射将错误信息位置映射到模块(这将会减慢编译速度)。 165 // // extractComments:true,//启用禁用提取注释 166 // cache: true,//启用缓存 167 // uglifyOptions: { 168 // comments: false,//如果你构建时不想出现注释,可以按照以下配置将 uglifyOptions.output.comments 设置为 false: 169 // }, 170 // }), 171 // // 提取css 172 new MiniCssExtractPlugin({ 173 // Options similar to the same options in webpackOptions.output 174 // both options are optional 175 filename: 'static/css/[name].[contenthash:8].css', 176 chunkFilename: 'static/css/[name].[contenthash:8].chunk.css', 177 }), 178 new CssMinimizerPlugin() 179 180 ], 181 devServer: { 182 static: { 183 directory: path.join(__dirname, "public") 184 }, 185 historyApiFallback: true, //When using the HTML5 History API, the index.html page will likely have to be served in place of any 404 responses. Enable devServer.historyApiFallback by setting it to true: 186 port: 3003, 187 compress: true 188 }, 189 devtool: isProduction?false:'source-map',//生产环境关闭sourcemap 190 } 191 192 if (isProduction) { 193 pluginsProduction = [ 194 // 20230216 代码压缩 195 new UglifyJsPlugin({ 196 parallel: true,// 使用多进程并行以提高构建速度 197 sourceMap: true,// 使用源映射将错误信息位置映射到模块(这将会减慢编译速度)。 198 // extractComments:true,//启用禁用提取注释 199 cache: true,//启用缓存 200 uglifyOptions: { 201 comments: false,//如果你构建时不想出现注释,可以按照以下配置将 uglifyOptions.output.comments 设置为 false: 202 }, 203 }), 204 205 ] 206 module.exports.plugins.push( 207 ...pluginsProduction 208 ) 209 210 }
(3)基于 React.lazy() 的优化
1 import DimensionReading from "../../pages/dimension/dimension-reading/dimension-reading"; 2 import DimensionWriting from "../../pages/dimension/dimension-writing/dimension-writing"; 3 import DimensionPhoto from "../../pages/dimension/dimension-photo/dimension-photo"; 4 import DimensionPlan from "../../pages/dimension/dimension-plan/dimension-plan"; 5 import DimensionAdd from "../../pages/dimension/dimension-add/dimension-add"; 6 import DimensionHome from "../../pages/dimension/dimension-home/dimension-home"; 7 import SelfIntro from "../../pages/self-intro/self-intro";
1 const DimensionReading = lazy(() => import("../../pages/dimension/dimension-reading/dimension-reading")) 2 const DimensionWriting = lazy(() => import("../../pages/dimension/dimension-writing/dimension-writing")) 3 const DimensionPhoto = lazy(() => import("../../pages/dimension/dimension-photo/dimension-photo")); 4 const DimensionPlan = lazy(() => import("../../pages/dimension/dimension-plan/dimension-plan")); 5 const DimensionAdd = lazy(() => import("../../pages/dimension/dimension-add/dimension-add")); 6 const DimensionHome = lazy(() => import("../../pages/dimension/dimension-home/dimension-home")); 7 const SelfIntro = lazy(() => import("../../pages/self-intro/self-intro"));
6、使用 Web Workers:对于一些计算密集型任务,可以使用 Web Workers 将任务分发到多个线程中,提高运算效率,避免页面卡顿。
7、优化 JavaScript 代码:优化 JavaScript 代码可以减少页面的运行时间,提高页面性能。一些常见的优化方案包括:避免使用全局变量,减少 DOM 操作,避免不必要的循环等。
8、使用响应式布局:使用响应式布局可以使页面适应不同大小的设备屏幕,提高用户体验,避免出现滚动条等不必要的元素。
9、使用 CSS3 动画:使用 CSS3 动画可以减少对 JavaScript 的依赖,提高动画效果的性能。
10、使用服务端渲染:服务端渲染可以将页面的渲染工作在服务端完成,减少客户端的渲染时间,提高页面性能。
6、for of 为什么会打乱顺序
`for...of`循环在遍历可迭代对象时,会按照对象的迭代器顺序来进行遍历。对于数组来说,迭代器顺序就是数组元素的顺序。
然而,有些可迭代对象的迭代器可能会返回按照不同顺序排列的元素。这就导致了在使用`for...of`循环遍历这些对象时,元素的顺序可能会被打乱。
例如,对于Set对象来说,它是一种无序的集合,Set对象的迭代器会返回按照元素插入的顺序进行遍历。但是,由于Set对象是无序的,所以在使用`for...of`循环遍历Set对象时,元素的顺序可能会被打乱。
另外,对于对象字面量(Object literals)来说,它们的属性的顺序是不确定的。在某些JavaScript引擎中,对象字面量的属性可能会按照它们被定义的顺序进行遍历,但在其他引擎中,属性的顺序可能是随机的。因此,在使用`for...of`循环遍历对象字面量时,属性的顺序可能会被打乱。
需要注意的是,对于数组来说,`for...of`循环会按照数组元素的顺序进行遍历,不会打乱顺序。只有对于某些特殊的可迭代对象,才会出现顺序被打乱的情况。
如果需要保持遍历顺序的稳定性,可以使用`for`循环或`forEach`方法来遍历。它们会按照数组元素的顺序进行遍历,不会打乱顺序。
7、tostring.call方法,为啥要放在原型上面?
`toString.call`方法是用来获取一个对象的类型信息的通用方法。它的作用是返回一个表示对象类型的字符串。
`toString.call`方法的实现是通过调用Object原型上的`toString`方法,并将需要获取类型的对象作为方法的调用者。例如,`toString.call(obj)`会调用`Object.prototype.toString`方法,并将`obj`作为调用者。
将`toString.call`方法放在原型上的主要原因是为了实现方法的共享和复用。将方法放在原型上意味着所有的实例对象都可以共享这个方法,而不需要每个实例对象都拥有自己的方法副本。这样可以节省内存空间,并提高代码的执行效率。
另外,将`toString.call`方法放在原型上还可以确保方法的一致性和稳定性。由于所有的实例对象都共享同一个方法,所以无论是哪个实例对象调用该方法,返回的结果都是一致的。这样可以避免由于不同实例对象上方法的差异导致的错误。
总结来说,将`toString.call`方法放在原型上可以实现方法的共享和复用,节省内存空间,提高代码执行效率,并确保方法的一致性和稳定性。
8、面向对象是什么?有几种继承方式?原型链是什么?
在JavaScript中,面向对象编程(Object-Oriented Programming,OOP)是一种编程范式,它将数据以及操作数据的方法组合在一起,形成对象。对象能够封装数据(属性)和行为(方法),并且能够与其他对象进行交互。通过面向对象的方式,JavaScript可以更好地组织和管理代码,提高代码的可维护性和复用性。开发者可以创建对象、定义构造函数、设置原型等来实现面向对象编程的特性。在现代的JavaScript开发中,面向对象编程已经成为一种常用的编程范式。
-
原型链继承(Prototype Inheritance):通过将一个对象的实例赋值给另一个对象的原型,实现继承。子对象继承父对象的属性和方法,但存在引用类型共享的问题。
-
构造函数继承(Constructor Inheritance):通过在子类构造函数中调用父类构造函数实现继承。子类继承父类的属性,但无法继承父类的原型上的方法。
-
组合继承(Combination Inheritance):结合原型链继承和构造函数继承,使用构造函数继承实现属性继承,使用原型链继承实现方法继承,以解决属性和方法分别继承的问题。
-
原型式继承(Prototype-based Inheritance):通过复制一个对象并对其进行扩展来实现继承,类似于对象的克隆。
-
寄生组合继承(Parasitic Combination Inheritance):在组合继承的基础上进行优化,避免调用两次父类构造函数,使用寄生式继承来继承父类的原型。
-
ES6 Class继承:ES6引入了Class语法糖,使得 JavaScript 类的声明、继承等更加类似于传统面向对象编程语言。使用
class关键字可以更方便地定义类和继承关系。
在 JavaScript 中,每个对象都有一个属性__proto__,指向其原型(prototype)的内部链接。这个原型对象又有自己的原型,以此类推,形成了一个链式结构,被称为原型链。
8、forEach,和for,of便利1w条数据谁快
在遍历1万条数据的情况下,使用`for`循环通常比`forEach`和`for...of`循环更快。
`for`循环是一种基本的循环结构,它直接操作数组的索引,因此效率较高。在遍历大量数据时,使用`for`循环可以更好地利用计算机的底层机制,提高遍历速度。
`forEach`是数组的方法,它会对数组中的每个元素都执行一个回调函数。尽管`forEach`提供了简洁的语法,但它在性能上通常比`for`循环稍慢。这是因为`forEach`方法会在每次迭代时都调用一个回调函数,这会带来一些额外的开销。
`for...of`循环是ES6中引入的一种新的遍历方式,它可以遍历可迭代对象(如数组、字符串等)。与`forEach`相比,`for...of`循环在性能上更接近`for`循环。然而,由于`for...of`循环需要进行迭代器的生成和管理,因此在某些情况下可能略慢于`for`循环。
综上所述,当需要遍历大量数据时,使用`for`循环通常是最快的。但是,在编写代码时,应根据具体情况选择最适合的循环方式,以满足代码的可读性和维护性。
9、for of 和for in和forEach的区别
-
for in:主要用于遍历对象的属性。在每次迭代中,变量会被赋值为不同的属性名。非Symbol类型的可枚举属性被迭代。此外,for in也可以遍历数组的索引,这是它不同于for of和forEach的一个特点。
- 用来遍历对象的可枚举属性,包括实例属性和原型属性。
- 不推荐用于遍历数组,因为可能会遍历到数组的原型属性和方法。
- 语法:
for (let key in object) { }
-
for of:适用于遍历数/数组对象/字符串/Map/Set等拥有迭代器对象的集合。它能够正确响应break、continue和return语句,这是与forEach()的主要区别。for of遍历的是数组元素值,不包括数组的原型属性方法和索引名。
for...of用来遍历可迭代对象(如数组、字符串、Map、Set等),只遍历对象本身的元素,而不包括原型链上的属性。- 可以获取到当前元素的值,而不是索引或键。
- 语法:
for (let value of iterable) { }
-
forEach():是JavaScript中Array的一个方法,专门用来循环数组。它可以直接取到元素,同时也可以取到index值。但是,forEach()有一些限制:不能同时遍历多个集合,在遍历的时候无法修改和删除集合数据,方法不能使用break, continue语句跳出循环,或者使用return从函数体返回,对于空数组不会执行回调函数。
forEach是数组的原生方法,用于遍历数组的每个元素。forEach接受一个回调函数作为参数,对数组中的每个元素执行该回调函数。- 无法中途跳出循环,也无法使用
break或continue。 - 语法:
array.forEach(callback(currentValue [, index [, array]]) { }
总结来说,for in适合遍历对象的属性或数组的索引,for of适合遍历可迭代对象如数组、字符串等,而forEach()则专门用于遍历数组元素
9、304强缓存原理
304缓存机制是基于HTTP的协议规范,它利用了浏览器的缓存功能来减少对服务器的请求。当浏览器第一次请求一个页面时,服务器会返回整个页面的内容,并在响应头中添加一个Last-Modified字段,该字段表示该页面的最后修改时间。浏览器会将这个页面缓存起来,并记录下该页面的最后修改时间。
当用户再次访问同一个页面时,浏览器会先检查该页面的缓存是否过期。如果缓存没有过期,浏览器会直接从缓存中加载页面,而不会向服务器发送请求。这样可以大大减少对服务器的访问,提高网站的响应速度。如果缓存已经过期,浏览器会向服务器发送一个请求,并在请求头中添加一个lf-Modified-Since字段,该字段的值为上次缓存页面的最后修改时间。服务器收到请求后,会检查该页面的最后修改时间是否与lIf-Modified-Since字段的值相等。如果相等,服务器会返回一个304 Not Modified的响应,告诉浏览器该页面没有修改,可以直接从缓存中加载。如果不相等,服务器会返回一个200 OK的响应,并返回最新的页面内容。
通过304缓存机制,可以减少服务器的负载,提高网站的响应速度。当网站的访问量很大时,这种优化策略尤为重要。同时,304缓存机制也可以节省用户的流量,减少手机流量费用的消耗。
然而,要正确使用304缓存机制,需要注意以下几点:1.服务器需要正确设置Last-Modified和ETag字段。Last-Modified字段表示页面的最后修改时间,而ETag字段可以用来标识页面的版本号。浏览器在发送请求时,可以根据这两个字段来判断页面是否修改。⒉浏览器需要正确设置缓存策略。在发送请求时,浏览器可以在请求头中添加一个Cache-Control字段,该字段的值可以设置为max-age或no-cache等。max-age表示页面的缓存时间,no-cache表示不缓存页面。3.在页面内容发生变化时,需要正确更新Last-Modified和ETag字段。这样浏览器才能正确判断页面是否修改。
304缓存机制是一种常用的缓存策略,可以有效减少对服务器的请求,提高网站的响应速度。但是要正确使用304缓存机制,需要服务器和浏览器之间的配合。只有正确设置缓存策略和更新页面的最后修改时间,才能发挥出最大的优势。在实际开发中,我们可以根据网站的特点和访问模式来选择合适的缓存策略,以提高用户的访问体验
10、react的onClick和vue的@click分别是怎么实现的
React中的onClick是通过事件委托来实现的。在React中,每个组件都有自己的事件系统,当点击事件发生时,React会将事件传递给对应的组件,然后组件可以通过定义一个onClick属性来处理点击事件。
例如,在React中,可以通过以下方式来实现点击事件的处理:
1 class MyComponent extends React.Component { 2 handleClick() { 3 console.log('Clicked'); 4 } 5 6 render() { 7 return <button onClick={this.handleClick}>Click Me</button>; 8 } 9 }
在上述代码中,当按钮被点击时,会调用`handleClick`方法,并打印出"Clicked"。
而在Vue中,@click是通过指令来实现的。在Vue中,可以通过在模板中使用@click指令来绑定点击事件的处理函数。
例如,在Vue中,可以通过以下方式来实现点击事件的处理:
1 <template> 2 <button @click="handleClick">Click Me</button> 3 </template> 4 5 <script> 6 export default { 7 methods: { 8 handleClick() { 9 console.log('Clicked'); 10 }, 11 }, 12 }; 13 </script>
在上述代码中,当按钮被点击时,会调用`handleClick`方法,并打印出"Clicked"。
总结来说,React中的onClick是通过事件委托来实现的,而Vue中的@click是通过指令来实现的。
11、怎么用hook去创建监听事件
要使用 React 的 Hook 来创建监听事件,你可以使用 `useState` 和 `useEffect` 这两个常用的 Hook。
首先,使用 `useState` 来创建一个状态变量,用于存储事件的监听状态:
1 import React, { useState } from 'react'; 2 3 function MyComponent() { 4 const [count, setCount] = useState(0); 5 6 // 其他逻辑代码... 7 }
然后,使用 `useEffect` 来创建事件的监听,当特定的条件满足时,会执行注册的事件处理函数:
1 import React, { useState, useEffect } from 'react'; 2 3 function MyComponent() { 4 const [count, setCount] = useState(0); 5 6 useEffect(() => { 7 const handleClick = () => { 8 setCount(count + 1); 9 }; 10 11 // 在这里注册事件监听器 12 document.addEventListener('click', handleClick); 13 14 // 在这里返回一个清除函数,用于在组件卸载时移除事件监听器 15 return () => { 16 document.removeEventListener('click', handleClick); 17 }; 18 }, [count]); 19 20 // 其他逻辑代码... 21 }
在上述示例中,我们在 `useEffect` 内部注册了一个点击事件监听器,在每次点击时会触发 `handleClick` 函数,更新 `count` 的值。然后,在返回的清除函数中,我们移除了注册的事件监听器,以防止内存泄漏。
需要注意的是,`useEffect` 的第二个参数是一个数组,用于指定哪些状态变量的改变会触发回调函数。在上面的示例中,我们传入了 `[count]`,意味着只有当 `count` 发生改变时才会注册/移除事件监听器。如果希望一开始就注册事件监听器并且不依赖任何状态变量,可以将第二个参数提供一个空数组 `[]`,表示没有依赖项。
12、如何不用hash实现一个热更新
要实现热更新而不使用哈希(hash)的方法,可以使用文件版本号(file versioning)。
以下是一种可能的实现方式:
1. 在服务器上,为每个文件生成一个唯一的版本号,并将其嵌入到文件名中或者通过特定的 HTTP 头部发送给客户端。
2. 在客户端,获取服务器上文件的版本号。
3. 在页面中引用文件时,将版本号连接到文件名中,例如:`main.js?v=123456`。
4. 当服务器上的文件发生更改时,更新文件的版本号。
5. 当客户端发现头部的版本号与当前版本号不匹配时,表示有新的文件可供更新。此时,客户端可以请求新的文件并更新页面上的资源。
需要注意的是,以上只是一种基本的思路。具体的实现方式会因为不同的工具、框架或环境而有所差异。在实践中,你可能需要使用工具或框架提供的热更新功能,例如 Webpack 的热模块替换(Hot Module Replacement)功能来实现热更新。
13、new 一个构造函数后会发生什么?
1、创建一个空对象,将它的引用赋给this,继承函数的原型
2、通过this将属性和方法添加到这个对象中
3、最后返回this指向的新对象
4、会隐性的新建一个空对象赋予this,还是那句话,这里的空对象并不是严格意义上的空,它还是继承了Person的原型
5、当我们new一个构造函数总是会返回一个对象,默认返回this所指向的对象。如果我们没有在构造函数内为this赋予任何属性,则会返回一个集成了构造函数原型,没有自己属性的'空对象'。
6、构造函数与普通函数无异,只是调用需要使用new,当我们不使用new调用时,语法也不会出错,但函数中的this会指向全局对象(非严格模式是window)。无法继承Person的任何属性。那有办法可以让不使用new情况下实例也能继承Person属性的做法吗,当然有,比如调用自身的构造函数
14、浏览器输入url会发生什么
-
解析 URL:浏览器会解析输入的 URL,包括协议(如
http://、https://)、域名、路径等信息。 -
DNS 解析:浏览器会通过 DNS 解析将输入的域名转换为对应的 IP 地址,以便能够定位服务器的位置。
-
建立连接:浏览器通过 TCP 协议与目标服务器建立连接,以便发送和接收数据。
-
发送 HTTP 请求:一旦连接建立成功,浏览器会向服务器发送 HTTP 请求,包括请求的资源(如 HTML 文件、图片、样式表等)和其他必要的信息。
-
服务器处理请求:服务器接收到浏览器发送的请求后,会解析请求并处理相应的资源,然后生成响应。
-
接收响应:浏览器会接收服务器返回的响应数据,如 HTML、CSS、JavaScript 等文件。
-
解析内容:浏览器开始解析接收到的数据,构建文档对象模型(DOM)和渲染树,以便后续的页面渲染。
-
页面渲染:浏览器根据解析得到的 DOM 结构和样式信息,进行页面布局和渲染,最终将页面内容显示在用户界面上。
-
显示页面:一旦页面渲染完成,用户就可以看到并与网页进行交互,浏览器会继续监听用户的操作并处理相应的事件。
15、http和https的区别?websocket和http的区别?
-
HTTP:
- HTTP 是一种用于在网络上传输超文本的协议,通常用于在 Web 浏览器和 Web 服务器之间传输页面数据。
- HTTP 数据以明文形式传输,不进行加密操作,因此容易被中间人窃听或篡改。
- HTTP 默认使用80端口进行通信。
-
HTTPS:
- HTTPS 是在 HTTP 基础上加入了 SSL/TLS 加密传输层的协议,用于确保数据在传输过程中的安全性和完整性。
- HTTPS 通过 SSL/TLS 协议对数据进行加密,以防止数据在传输过程中被窃取或篡改。
- HTTPS 数据传输过程中使用443端口进行通信。
- 使用 HTTPS 的网站会通过 SSL 证书验证网站身份,并确保数据传输过程是加密的。
总的来说,HTTP 和 HTTPS 的主要区别在于数据传输的安全性。HTTPS 提供了加密和认证机制,确保用户与网站之间传输的数据是安全的,而 HTTP 则是明文传输,存在被窃听和篡改的风险。因此,在涉及到用户隐私信息或敏感数据传输时,建议使用 HTTPS,以确保数据安全。
-
HTTP:
- HTTP 是一种无状态的应用层协议,用于在客户端和服务器之间传输和交换数据。
- 每次客户端发送请求到服务器时,都需要建立一个新的连接,并由服务器返回响应后立即关闭连接。
- HTTP 是基于请求-响应模式工作的,即客户端发送请求,服务器返回响应,然后连接关闭。
- HTTP 遵循同源策略,限制了跨域请求,导致可能需要使用跨域资源共享(CORS)来进行跨域通信。
-
WebSocket:
- WebSocket 是一种全双工、双向通信协议,能够在单个 TCP 连接上实现持久化的连接,允许客户端和服务器之间进行实时数据交换。
- 与 HTTP 不同,WebSocket 连接建立后,可以保持打开状态,双方随时都可以发送数据,而不需要每次请求都重新建立连接。
- WebSocket 不遵循同源策略的限制,允许跨域通信,提供更大的灵活性。
综上所述,WebSocket 与 HTTP 在通信方式、连接方式和跨域通信方面存在明显的区别。WebSocket 更适合需要实时交互和持久连接的场景,而 HTTP 适用于传统的请求-响应模式。在需要实时数据传输且不受同源策略限制时,WebSocket 是更好的选择。
16、强缓存和协商缓存的区别?
-
强缓存(Cache-Control 和 Expires):
- 强缓存是指浏览器在发起请求前,先检查本地的缓存数据是否过期。如果没有过期,浏览器直接使用本地缓存,不发起请求到服务器。常用的强缓存相关的 HTTP 头有
Cache-Control和Expires。 Cache-Control是 HTTP/1.1 中定义的一个通用头部字段,可以控制缓存策略的行为。常见的属性有max-age(缓存过期时间)和no-cache(不使用强缓存)。Expires是 HTTP/1.0 中的头部字段,表示资源的过期时间。但它的可靠性不如Cache-Control高。
- 强缓存是指浏览器在发起请求前,先检查本地的缓存数据是否过期。如果没有过期,浏览器直接使用本地缓存,不发起请求到服务器。常用的强缓存相关的 HTTP 头有
-
协商缓存(Last-Modified 和 ETag):
- 协商缓存是指浏览器在发起请求时,会携带上一次请求返回的一些信息(如 Last-Modified 时间戳或 ETag 标识符)到服务器,由服务器根据这些信息来判断是否需要返回新的资源。
- 当浏览器发送请求时,服务器会检查请求头中是否包含
If-Modified-Since(Last-Modified)或If-None-Match(ETag),如果匹配,服务器返回 304 Not Modified,浏览器可以继续使用本地缓存。
-
区别:
- 强缓存是由浏览器在本地缓存中直接判断是否命中缓存;而协商缓存则是需要与服务器通信来确定是否可以使用缓存。
- 强缓存适用于资源不经常变动的场景,可以显著减少请求次数;而协商缓存适用于资源变动较频繁或者需要准确判断资源是否改变的情况。
- 强缓存优先级高于协商缓存,浏览器会先判断是否命中强缓存,如果命中则直接使用;否则再进行协商缓存。
17、vue和react的区别?
-
设计理念和语法:
-
数据流和组件化:
- Vue实现了双向数据绑定,使得数据流更加直观和易于理解。Vue的组件可以通过props参数进行父子组件之间的数据传递。
- React则采用单向数据流的方式,数据从父组件流向子组件,子组件不能直接修改父组件的数据。React的组件化设计通过props和state来管理组件的状态和行为。
-
性能优化:
- Vue通过虚拟DOM技术和异步渲染等优化手段,实现了快速的页面渲染和响应。Vue的性能在中小型应用程序中表现良好。
- React也利用虚拟DOM和多线程渲染等技术手段,实现了高效的页面渲染和响应。React在处理大型应用程序和数据流时表现出色。
-
模板:
- Vue 使用模板语法(如
{{ }})来声明视图和数据的绑定关系,这使得模板更加直观且易于理解。而 React 使用 JSX,一种混合 JavaScript 和 HTML 的语法,使得组件的结构和逻辑更加紧密地集成在一起。
- Vue 使用模板语法(如
-
状态管理:
- 在 React 中,通常会使用 Redux 或者 Context API 来进行状态管理,这使得全局状态的管理更加灵活。Vue 则提供了 Vuex 这样的状态管理工具,同样能够很好地解决状态共享和管理的问题。
-
组件通信:
- 在 Vue 中,父子组件之间通过 props 和事件机制来进行通信。而在 React 中,父子组件之间也是通过 props 来传递数据,但是通常是通过回调函数实现子组件向父组件传递数据。
18、vue2和vue3的区别?
-
项目架构:Vue 2.0通常使用webpack或vue-cli进行项目搭建和打包,而Vue 3.0更推荐使用Vite这款新型前端构建工具,基于ES Modules标准,提高了开发速度和简化开发过程。Vue 3.0倾向于使用组合式API + TypeScript的方式进行架构设计和实现,提供更灵活的组件开发和复用,同时增加严格的类型校验,提高代码质量和可维护性。
-
数据响应式系统:Vue 3.0在数据响应式系统方面有所改进,能够监听所有对象和数组的变化,而Vue 2.0只能监听到数组的一个变化。
-
双向数据绑定:Vue 3.0支持对对象的双向数据绑定,而Vue 2.0不支持。
-
组合式API:Vue 3.0引入了组合式API,允许以更灵活的方式组织和复用代码逻辑。
-
首屏优化:Vue 3.0的生命周期钩子与Vue 2.0不同,如创建组件时的onMount和更新时的onUpdate。
-
传参方式:Vue 3.0允许通过setter方法的第二个参数进行传参,提供更灵活的参数处理方式。
-
插槽使用:Vue 3.0中,插槽的使用方式和优先级与Vue 2.0有所不同,例如v-for的优先级在Vue 3.0中更高。
-
微钢缝处理:Vue 3.0在处理微钢缝时,将其视为微钢服内部的一个判断,不会与Vue 2.0的处理方式冲突。
-
根节点要求:Vue 2.0中必须要有根标签,而Vue 3.0可以没有根标签,多个根标签会被默认包裹在一个fragement虚拟标签中,有利于减少内存消耗。
19、vue2和vue3双向绑定的区别?
-
Vue2 使用
v-model进行双向数据绑定,而 Vue3 引入了v-bind和v-on指令的更简洁语法@bind和@update:property。 -
Vue2 使用
Object.defineProperty(),而 Vue3 使用 Proxies。Proxy 提供了更多功能,并且在处理数组和嵌套对象时更加高效。 -
Vue3 引入了
ref和reactiveAPI 来处理响应式数据。ref用于创建简单的响应式引用,而reactive用于创建复杂的响应式对象。
14、flex:1是哪几个属性的结合?
flex-grow: 1, flex-shrink: 1, flex-basis: 0 的合并写法。
flex-grow属性规定项目的放大比例,默认值为0,即如果存在剩余空间,也不放大。如果所有项目的flex-grow属性都为1,则它们将等分剩余空间,如果一个项目的flex-grow属性值为2,其它为1,则前者占据的剩余空间将比其他项多一倍。flex-shrink属性规定了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小;如果一个项目的flex-shrink属性值为0,其他项目都为1,则空间不足时,前者不缩小。flex-basis属性用于设置项目在主轴方向上的初始尺寸。默认值为auto,即项目的本来大小。另外,可以设置具体长度或百分比等样式。
15、为什么margin-top不是相对于父元素?
子元素顶部紧贴父元素,并且margin-top好像转移给了父元素,让父元素产生上外边距。这其实是一个典型的外边距合并问题,但是并非 所有的浏览器都会产生这种情况,一般标准浏览器都会出现此现象,而IE6和IE7在此状态下不会出现外边距合并现象。上外边距合并出现的条件:
1.父元素的上边距与子元素的上边距之间没有border。
2.父元素的上边距与子元素的上边距之间没有非空内容。
3.父元素的上边距与子元素的上边距之间没有padding。
3.父元素和子元素中没有设置定位属性(除static和relative)、overflow(除visible)和display:inline-block等。
4.父元素或者资源都没有浮动。
16、BFC
BFC(Block Formatting Context)格式化上下文,是Web页面中盒模型布局的CSS渲染模式,指一个独立的渲染区域或者说是一个隔离的独立容器。
BFC 即 Block Formatting Contexts (块级格式化上下文),属于普通流。
可以把 BFC 理解为一个封闭的大箱子,箱子内部的元素无论如何翻江倒海,都不会影响到外部。
二、形成BFC的条件
1、浮动元素,float 除 none 以外的值;
2、绝对定位元素,position(absolute,fixed);
3、display 为以下其中之一的值 inline-block,table-cell,table-caption、flex;
4、overflow 除了 visible 以外的值(hidden,auto,scroll);
5、body 根元素
三、BFC的特性
1.内部的Box会在垂直方向上一个接一个的放置。
2.垂直方向上的距离由margin决定
3.bfc的区域不会与float的元素区域重叠。
4.计算bfc的高度时,浮动元素也参与计算
5.bfc就是页面上的一个独立容器,容器里面的子元素不会影响外面元素。
17、浮动
浮动是因为使用了float:left或float:right或两者都是有了而产生的浮动。
清除浮动的方式:
1. 父级div定义height
2. 父级div定义overflow:hidden
3. 父级div定义overflow:auto。
4. 结尾处加空div标签clear:both
5. 结尾处加br标签clear:both
6. 父级div定义伪类:after、before
7. 父级div也浮动,需要定义宽度。
8. 父级div定义display:table。
18、前端使用过gizp压缩吗,怎么配置,原理是什么
-
配置服务器:首先,你需要在服务器上启用Gzip压缩。对于Apache服务器,可以通过修改配置文件(如.htaccess文件或httpd.conf文件)来启用Gzip压缩。对于Nginx服务器,可以在配置文件中的http块中添加Gzip配置项。
-
压缩文件类型:你可以配置Gzip压缩仅对指定的文件类型生效,如HTML、CSS、JS、JSON等。通常,文本文件类型适合进行Gzip压缩,而二进制文件类型(如图片)则不适合。
-
压缩级别:你可以设置压缩的级别,一般有0-9级别可选。级别越高,压缩比越大,但同时也会增加压缩时间。
-
客户端请求:当浏览器发送请求时,它会在请求头中添加"Accept-Encoding"字段,指定它支持的压缩格式。服务器在响应时会检查该字段,并决定是否使用Gzip压缩。
gzip压缩的原理是通过一种无损压缩算法来减小文件的体积,从而减少传输时间和网络带宽。该算法通过查找文件中的重复数据,并用更短的表示方式来代替这些重复数据,从而实现压缩。具体来说,gzip压缩算法主要包括以下几个步骤:
-
重复数据的查找:gzip算法会扫描文件,找出重复出现的数据块。
-
构建哈希表:对于找到的重复数据块,gzip会构建一个哈希表,用于快速查找重复数据块。
-
动态编码:gzip使用动态霍夫曼编码(Dynamic Huffman Coding)来对数据进行编码,将重复数据块替换为更短的编码,从而实现压缩。
-
生成压缩文件:经过编码后,gzip会生成一个压缩文件,其中包含原始数据和编码表。
当浏览器接收到经过gzip压缩的文件时,会先解压缩文件,然后再进行渲染。由于压缩后的文件体积更小,因此可以减少网络传输时间,加快网页加载速度。
总的来说,gzip压缩通过查找重复数据并用更短的表示方式来代替这些重复数据,从而实现文件的压缩。这样可以减小文件大小,减少网络传输时间,提高网页加载速度。
19、请求方式都有哪些,假如post请求最大支持2M,那么上传一个3M的文件应该怎么做最合适?
- GET:从服务器获取数据。
- POST:向服务器提交数据。
- PUT:更新服务器上的资源。
- DELETE:删除服务器上的资源。
- PATCH:部分更新服务器上的资源。
- HEAD:类似于GET请求,但只返回响应头信息而不返回实际内容。
- OPTIONS:获取服务器支持的请求方法。
如果POST请求最大支持2M,上传一个3M的文件最合适的做法是使用multipart/form-data 格式将文件分块上传。可以将文件分割成多个小块,每个小块都小于2M,然后依次上传这些小块。服务器端接收到所有小块后再将它们合并成完整的文件。
另一种方法是使用64字符串,然后将64字符串作为POST请求的参数进行上传。这样虽然会增加数据量,但可以绕过文件大小限制。服务器端接收到64字符串后再将其解码还原成文件。
21、了解HTTP/2的特点、优势以及与HTTP/1.x的区别,以及如何在前端项目中优化使用HTTP/2协议。
特点和优势:
- 二进制传输:HTTP/2采用二进制格式传输数据,相较于HTTP/1.x的文本格式,二进制格式更加高效。
- 多路复用:HTTP/2支持多路复用,可以在同一个连接上同时传输多个请求和响应,避免了HTTP/1.x中的队头阻塞问题。
- 头部压缩:HTTP/2使用HPACK算法对头部信息进行压缩,减少了数据传输的大小,提高了性能。
- 服务器推送:HTTP/2支持服务器主动推送资源给客户端,减少了客户端请求的延迟。
- 优化连接管理:HTTP/2使用了多个技术,如连接复用、流控制、优先级等,来优化连接管理,提高性能。
与HTTP/1.x的区别:
- 连接复用:HTTP/2支持多路复用,可以在同一个连接上传输多个请求和响应,而HTTP/1.x每次请求都需要建立新的连接。
- 头部压缩:HTTP/2使用HPACK算法对头部信息进行压缩,减少了数据传输的大小,而HTTP/1.x每次请求都需要携带完整的头部信息。
- 服务器推送:HTTP/2支持服务器推送资源给客户端,减少了客户端请求的延迟,而HTTP/1.x需要客户端发起请求才能获取资源。
- 优化性能:HTTP/2的设计目标是提高性能和效率,通过多路复用、头部压缩等技术优化了数据传输效率,而HTTP/1.x存在队头阻塞等性能问题。
在前端项目中优化使用HTTP/2协议的方法:
- 使用HTTPS:HTTP/2必须在HTTPS协议上使用,因此确保网站启用了HTTPS。
- 合并文件:利用HTTP/2的多路复用特性,可以不再依赖文件合并来减少请求数量,但仍可通过合并文件来减少请求次数。
- 优化资源加载顺序:利用HTTP/2的优先级特性,可以明确指定资源加载的优先级,提高页面加载速度。
- 减少请求次数:尽量减少不必要的请求,合理使用缓存和资源压缩,以减少数据传输量。
- 使用服务器推送:合理利用服务器推送功能,将可能需要的资源提前推送给客户端,减少客户端请求的延迟。
22、require和import的区别?
第一、两者的加载方式不同,require 是在运行时加载,而 import 是在编译时加载
第二、规范不同,require 是 CommonJS/AMD 规范,import 是 ESMAScript6+规范
第三、require 特点:社区方案,提供了服务器/浏览器的模块加载方案。非语言层面的标准。只能在运行时确定模块的依赖关系及输入/输出的变量,无法进行静态优化。import 特点:语言规格层面支持模块功能。支持编译时静态分析,便于 JS 引入宏和类型检验。动态绑定。
第四、使用方式不同。require可以在代码中以函数形式动态引用模块,根据条件动态加载;import需要静态引用,通常在文件的最开始处,不能在条件语句或函数作用域中使用。
第五、模块缓存不同。使用require引入的模块会被缓存,多次引用同一个模块会返回相同的导出对象,避免重复执行模块代码;import会在内存中创建一个只读的引用,多次导入同一个模块不会重复执行该模块的代码。
第六、导入内容不同。require可以引用模块中的任意成员,包括通过module.exports导出的内容;import只能导入模块中通过export关键字明确导出的成员。
第七、性能不同。require在运行时才引入模块的属性,性能相对较低;import在编译时引入模块的属性,性能稍高。
第八、入与导出关系不同。import需要与导出有一一映射关系,类似于解构赋值;require导入的值被修改时,源对象不会被改变,相当于深拷贝;import导入的对象值被改变时,源对象也会被改变,相当于浅拷贝
23、哈希和history的区别
- 实现原理不同。哈希模式通过监听`hashchange`事件来响应URL中#符号后的变化,而不需要用户重新加载页面;历史模式则通过调用`history.pushState`或`history.replaceState`方法并监听`popstate`事件来实现,这会导致浏览器历史记录的变化,但不会立即向服务器发送请求。
- 浏览器兼容性不同。哈希模式兼容性较好,支持较老版本的浏览器;历史模式则需要较新的浏览器支持,通常从IE10开始。
- 用户体验不同。哈希模式在URL中显示#符号,不会影响页面的实际加载和渲染;历史模式在URL中不显示#符号,并且在浏览器后退按钮中显示的是历史记录,而不是实际的URL。
- 数据共享不同。哈希模式不会影响页面的实际加载和渲染,因此适用于单页面应用;历史模式会影响页面的实际加载和渲染,适用于多页面应用。
- 服务器交互不同。哈希模式不会导致浏览器向服务器发送请求,因此不会影响后端服务器的响应;历史模式会导致浏览器向服务器发送请求,因此可能会影响后端服务器的响应。
24、nodejs的事件循环
https://vue3js.cn/interview/NodeJS/event_loop.html#%E4%B8%80%E3%80%81%E6%98%AF%E4%BB%80%E4%B9%88
25、js事件循环
JavaScript的事件循环是一种异步编程的机制,它允许程序在执行I/O操作时不会阻塞主线程。事件循环由浏览器内部的"任务队列"管理,主要包括宏任务(Macro Task)和微任务(Micro Task)。
宏任务包括:
-
整体的脚本(script)
-
setTimeout
-
setInterval
-
I/O操作
-
setImmediate(只在IE中有效)
微任务包括:
-
process.nextTick(Node.js中有效)
-
Promise
-
Object.observe(已废弃)
-
MutationObserver
26、自定义一个hooks(详细)(vue和react)
27、判断类型的方式有哪些?
1、typeof 操作符:用来检测数据的类型,返回的是一个表示类型的字符串。
2、instanceof 操作符:用来检测对象是否为指定的构造函数的实例。
3、Object.prototype.toString 方法:可以返回对象的准确类型。
4、Array.isArray() 方法:用来判断一个变量是否为数组。
(一)typeof和instanceof区别
-
返回值不同:
typeof返回的是一个字符串,表示变量的数据类型,可能的返回值有number、string、boolean、function、undefined、object。instanceof返回的是一个布尔值,true或false,用来判断一个对象是否属于某个类的实例。
-
操作数数量不同:
typeof只需要一个操作数,即要检查的变量或表达式。instanceof需要两个操作数,左边是对象,右边是构造函数。
-
作用不同:
typeof主要用于检测数据类型,可以判断所有变量的类型,但对于丰富的对象实例,只能返回object(除function外),不能得到真实的数据类型。instanceof主要用于判断对象之间的关联性,通过检查对象的原型链来判断一个对象是否是某个类的实例。
-
底层逻辑不同:
typeof根据数据在存储单元中的类型标签来判断数据的类型。instanceof则是根据函数的prototype属性值是否存在于对象的原型链上来判断数据的类型。
-
使用场景:
typeof适用于基础数据类型的检测,但在处理对象时,除了函数类型外,其他类型的对象都会被视为object。instanceof更适合用于判断引用数据类型,特别是当需要确定一个对象是否属于某个特定类的实例时。
28、前端工程化?
前端工程化是指通过使用工具、流程和最佳实践来提高前端开发的效率、质量和可维护性的过程。它包括一系列的工具和方法,旨在简化前端开发流程、提高团队协作效率和优化项目的性能。前端工程化通常涵盖以下主要方面:
-
模块化开发: 使用模块化开发的方式,如 CommonJS、AMD、ES6 模块等,以便更好地组织代码、提高可维护性,并通过模块打包工具将模块打包成可在浏览器中运行的文件。
-
构建工具: 使用构建工具(如Webpack、Rollup、Parcel等)来自动化地完成代码的压缩、打包、转译、代码分割以及资源管理等任务,以提高开发效率和最终的性能。
-
版本控制: 使用版本控制系统(如 Git)来追踪代码的变化,进行团队协作开发,并能够轻松地进行代码回滚和合并。
-
自动化测试: 编写自动化测试用例(如单元测试、集成测试、端到端测试),并使用测试框架(如Jest、Mocha、Cypress等)来自动化执行这些测试,以确保代码的质量和稳定性。
-
持续集成和持续部署(CI/CD): 使用CI/CD工具(如Jenkins、Travis CI、CircleCI等)来自动化构建、测试和部署过程,以实现频繁、可靠地发布应用程序。
-
代码规范和静态分析: 使用代码规范工具(如ESLint、Prettier、Stylelint等)对代码进行格式化和静态分析,以提高代码的可读性、一致性和质量。
-
性能优化: 通过优化资源加载、代码分割、缓存策略、图片压缩等方式,提高应用程序的性能和用户体验。
在我的项目中,我使用了以下前端工程化工具和技术:
1. Webpack:用于模块化打包和构建项目,管理静态资源。
2. Babel:用于将 ES6+ 的代码转换成兼容各种浏览器的 ES5 代码。
3. ESLint:用于代码规范检查,帮助团队统一代码风格。
4. Prettier:用于代码格式化,保持代码风格一致性。
5. Husky + lint-staged:用于在 git 提交前进行代码规范检查。
6. PostCSS:用于处理 CSS,如自动添加浏览器前缀、压缩等。
7. Stylelint:用于 CSS/Sass/SCSS/Less 的规范检查。
8. Jest:用于单元测试和集成测试。
29、webpack?
Webpack是一个模块打包工具,主要用于处理和管理前端资源,它能够分析模块间的依赖关系,将源代码及其依赖项打包成适合在浏览器中使用的静态资源。Webpack的核心概念包括:
- Entry:入口点,Webpack 构建过程的起点,指定了哪些文件作为项目的入口。
- Output:输出配置,定义了打包后文件的输出路径和命名规则。
- Loader:模块转换器,用于将各种类型的文件转换为Webpack能够处理的有效模块,例如将TypeScript编译成JavaScript,或将SCSS编译成CSS。
- Plugin:扩展插件,用于在Webpack的构建生命周期中执行各种任务,如优化打包结果、注入环境变量等。
Webpack的主要功能包括:
- 代码转换:将TypeScript、ES6等现代JavaScript语法转换为浏览器兼容的代码。
- 文件优化:压缩JavaScript、CSS、HTML代码,合并和压缩图片等静态资源。
- 代码分割:将代码拆分为多个块,实现按需加载,提高首屏加载性能。
- 模块合并:将多个模块合并成一个或多个文件,便于管理和加载。
- 自动刷新:监听源代码变化,自动重新构建并刷新浏览器。
- 代码校验:在代码提交前进行语法和单元测试检查。
- 自动发布:自动构建上线代码并传输给发布系统。
-
Webpack 的基本概念:
- 问:请简要介绍一下Webpack是什么?
- 答:Webpack是一个现代的前端模块打包工具,它可以将各种模块(如JavaScript、CSS、图片等)打包成静态资源文件,用于浏览器加载。
-
Webpack 的核心原理:
- 问:请解释一下Webpack的工作原理是什么?
- 答:Webpack将项目中的各种静态资源视为模块,通过一个称为“依赖图”的数据结构来构建这些模块之间的依赖关系,并最终将它们打包成输出文件。
-
Webpack 的常见配置:
- 问:如何配置Webpack的入口文件和输出文件?
- 答:在Webpack配置文件中,可以通过配置
entry选项指定入口文件的路径,通过配置output选项指定输出文件的路径和文件名。
-
Webpack 的优化策略:
- 问:你对Webpack的性能优化有哪些了解?
- 答:Webpack的性能优化可包括代码拆分、懒加载、缓存优化、使用Tree Shaking消除无用代码、使用Webpack插件(如MiniCssExtractPlugin、UglifyJsPlugin)等方式来提高构建性能和优化输出文件大小。
-
Loader和Plugin的作用:
- 问:Webpack中的Loader和Plugin有什么作用?可以举例说明吗?
- 答:Loader用于处理各种类型的文件,如转换ES6语法、处理CSS预处理器等;Plugin则用于执行各种构建任务,如代码压缩、打包优化、资源管理等。例如,sass-loader用于处理Sass文件,而HtmlWebpackPlugin用于生成HTML文件并将打包后的脚本自动引入到HTML中。
-
30、webpack和vite的区别
1、 开发模式不同
Webpack在开发模式下依然会对所有模块进行打包操作,虽然提供了热更新,但大型项目中依然可能会出现启动和编译缓慢的问题;而Vite则采用了基于ES Module的开发服务器,只有在需要时才会编译对应的模块,大幅度提升了开发环境的响应速度。
2、打包效率不同
Webpack在打包时,会把所有的模块打包成一个bundle,这会导致初次加载速度较慢;而Vite则利用了浏览器对ES Module的原生支持,只打包和缓存实际改动的模块,从而极大提高了打包效率。
3、插件生态不同
Webpack的插件生态非常丰富,有大量社区和官方插件可以选择,覆盖了前端开发的各个方面;而Vite的插件生态尽管在不断发展,但相比Webpack来说还显得较为稀少。
4、配置复杂度不同
Webpack的配置相对复杂,对新手不够友好;而Vite在设计上更注重开箱即用,大部分场景下用户无需自己写配置文件。
5、热更新机制不同
Webpack的热更新需要整个模块链重新打包和替换,对于大型项目可能会有延迟;Vite的热更新则只会针对改动的模块进行更新,提高了更新速度。
30、rollup打包流程和webpack打包流程的差异。
- Rollup打包流程:
- Rollup是一种以模块为中心的打包工具,它主要用于打包JavaScript模块。
- Rollup将JavaScript模块按照ES模块标准进行静态分析,并且会去除未使用的代码(tree shaking),以减少打包后文件的体积。
- Rollup不支持像Webpack一样的代码分割(code splitting)功能,因此在项目中需要手动处理模块的分割和异步加载。
- Webpack打包流程:
- Webpack是一种功能强大的打包工具,支持打包JavaScript、CSS、图片等各种资源文件。
- Webpack基于入口文件和依赖关系图(dependency graph)进行打包,将所有资源模块打包成一个或多个bundle文件。
- Webpack支持各种插件和加载器(loader),能够处理更多不同类型的文件,如CSS预处理器、图片压缩等。
- Webpack具有更灵活的代码分割和代码加载功能,可以实现按需加载、动态加载等功能,以优化页面加载性能。
总的来说,Rollup更适合打包纯JavaScript模块,并且在体积优化方面表现更好;而Webpack更适合打包多种资源文件,功能更全面且灵活,适用于复杂的前端项目需求。
31、单页面应用和多页面应用区别?
单页面应用(SPA)的特点如下:
用户与应用程序交互时,只有一个页面,所有内容都包含在这个主页面中。
页面内容通过JavaScript动态更新,无需重新加载整个页面。
用户体验好,内容改变时不需要加载整个页面,对服务器压力较小。
前后端分离,前端负责UI和交互逻辑,后端负责数据处理和接口提供。
适合需要频繁交互和动态更新的Web应用。
单页面应用的缺点包括:
首次加载时间较长,因为所有必要的代码(HTML、JavaScript和CSS)都通过单个页面的加载。
SEO难度较大,因为搜索引擎爬虫不易获取到通过JavaScript动态加载的页面内容。
多页面应用(MPA)的特点如下:
每个页面都需要从服务器重新加载相关资源(html、js、css等)。
每个页面都是独立的,需要整页资源刷新。
利于SEO,因为每个页面都包含完整的HTML内容,方便搜索引擎进行排名。更容易扩展和进行数据分析。
多页面应用的缺点包括:
开发成本高,服务器端压力大,用户体验相对较差。
综上所述,单页面应用和多页面应用各有优势和不足。单页面应用提供更好的用户体验和前后端分离的架构,而多页面应用则更适合SEO和服务器端的压力较小。在选择时,需要根据具体的应用场景和需求来决定使用哪种类型的Web应用程序
32、什么是JavaScript中的柯里化(Currying)和偏函数应用(Partial Application)?它们在JavaScript中有哪些应用场景?
柯里化(Currying)和偏函数应用(Partial Application)是函数式编程中的两个重要概念,它们在JavaScript中也有应用场景
柯里化(Currying)是一种将一个多参数的函数转换为一系列单参数函数的转换技术。它的基本思想是将一个多参数的函数转换成一个或多个单参数的函数,使得每个单参数的函数都返回一个新的函数,这个新的函数接受下一个参数并返回一个新的函数,以此类推,直到所有参数都被传递为止。
偏函数应用(Partial Application)是一种将一个多参数的函数应用到一个或多个参数上的技术。它的基本思想是将一个多参数的函数转换成一个单参数的函数,使得这个单参数的函数接受一个固定的值并返回一个新的函数,这个新的函数接受剩下的参数并返回结果。
本文来自博客园,作者:冰中焱,转载请注明原文链接:https://www.cnblogs.com/Blod/p/17665472.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号