论文解读(UGfromer)《Universal Graph Transformer Self-Attention Networks》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Universal Graph Transformer Self-Attention Networks
论文作者:
论文来源:2022 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1-摘要
我们引入了一个基于变压器的GNN模型,称为UGfromer,来学习图表示。特别是,我们提出了两个UGfromer变体,其中第一个变体(2019年9月公布)是在每个输入节点的一组采样邻居上利用变压器,而第二个变体(2021年5月公布)是利用所有输入节点上的变压器。实验结果表明,第一个UGfroster变体在归纳设置和无监督转换设置的基准数据集上达到了最先进的精度;第二个UGfroster变体获得了最先进的归纳文本分类精度。
2-介绍
贡献:
-
- 我们提出了一个基于变压器的GNN模型,称为UGfroster,来学习图表示。特别地,我们考虑了两个模型变体:(i)在每个输入节点的一组采样邻居上利用转换器,以及(ii)在所有输入节点上利用转换器。
- 无监督学习在工业和学术应用中都是必不可少的,在那里扩展无监督GNN模型更适合解决类标签的有限可用性。因此,我们提出了一种无监督的转换学习方法来训练gnn。
- 实验结果表明,第一个UGfroster变体在社会网络和生物信息学数据集上获得了最先进的归纳设置和无监督转换设置的图分类的准确性;第二个UGfroster变体产生了最先进的准确性在基准数据集上的归纳文本分类
3-方法
模型框架
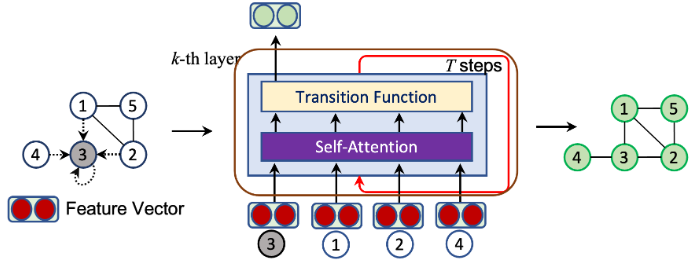
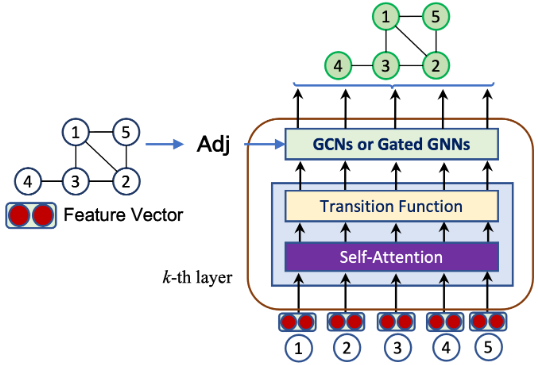
概括:在邻居节点(包括自己)之间计算注意力,而不是所有节点之间计算注意力;
代码:
import math import torch import torch.nn as nn import torch.nn.functional as F from torch.nn import TransformerEncoder, TransformerEncoderLayer from torch.nn import Transformer class TransformerU2GNN(nn.Module): def __init__(self, feature_dim_size, ff_hidden_size, num_classes, num_self_att_layers, dropout, num_encoder_layers): super(TransformerU2GNN, self).__init__() self.feature_dim_size = feature_dim_size # 19 self.ff_hidden_size = ff_hidden_size #1024 self.num_classes = num_classes # 图类别数=2 self.num_self_att_layers = num_self_att_layers #Each U2GNN layer consists of a number of self-attention layers self.num_encoder_layers = num_encoder_layers # Transformer 中的 Encoder 层 self.transformer_encoder_layers = torch.nn.ModuleList() for _ in range(self.num_encoder_layers): encoder_layers = TransformerEncoderLayer(d_model=self.feature_dim_size, nhead=1, dim_feedforward=self.ff_hidden_size, dropout=0.5) self.transformer_encoder_layers.append(TransformerEncoder(encoder_layers, self.num_self_att_layers)) # Linear function self.predictions = torch.nn.ModuleList() self.dropouts = torch.nn.ModuleList() for _ in range(self.num_encoder_layers): self.predictions.append(nn.Linear(self.feature_dim_size, self.num_classes)) self.dropouts.append(nn.Dropout(dropout)) def forward(self, input_x, graph_pool, x_feature): prediction_scores = 0 #torch.Size([31, 17, 19]) input_Tr = F.embedding(input_x, x_feature) #torch.Size([31, 17, 19]) for layer_idx in range(self.num_encoder_layers): output_Tr = self.transformer_encoder_layers[layer_idx](input_Tr) #torch.Size([31, 17, 19]) output_Tr = torch.split(output_Tr, split_size_or_sections=1, dim=1) #tuple(17) output_Tr = output_Tr[0] #torch.Size([31, 1, 19]) output_Tr = torch.squeeze(output_Tr, dim=1) #torch.Size([31, 19]) input_Tr = F.embedding(input_x, output_Tr) #torch.Size([31, 17, 19]) #sum pooling graph_embeddings = torch.spmm(graph_pool, output_Tr) #torch.Size([2, 31]) graph_embeddings = self.dropouts[layer_idx](graph_embeddings) # Produce the final scores prediction_scores += self.predictions[layer_idx](graph_embeddings) return prediction_scores
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/18129463
