论文解读(SGDA)《Semi-supervised Domain Adaptation in Graph Transfer Learning》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Semi-supervised Domain Adaptation in Graph Transfer Learning
论文作者:
论文来源:2024 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1-摘要
作为图转移学习的一个特殊情况,图上的无监督域自适应的目的是将知识从标签丰富的源图转移到未标记的目标图。然而,具有拓扑结构和属性的图通常具有相当大的跨域差异,而且在许多现实场景中,源图中只标记了一个节点的子集。由于严重的领域转移和标签稀缺,这给图转移学习带来了关键的挑战。为了解决这些挑战,我们提出了一种被称为半监督图域自适应(SGDA)的方法。为了处理域移位,我们在每个源节点上添加自适应移位参数,以对抗的方式进行训练,对齐节点嵌入的跨域分布,从而将在标记源节点上训练的节点分类器转移到目标节点。此外,为了解决标签稀缺问题,我们提出了在未标记节点上的伪标记,通过基于节点与类中心的相对位置测量节点的后验影响,改进了对目标图的分类。最后,在一系列公开可访问的数据集上进行的大量实验验证了我们提出的SGDA在不同实验设置下的有效性。
2-介绍
节点分类的半监督域自适应框架必须解决两个基本问题:
问题1:如何克服一个重要的域位交叉图给出域不变预测?源图和目标图之间的域转移大致分为以下两个视图中:图的拓扑结构和节点属性。例如,不同的图可能具有不同的链接密度和子结构模式,而来自不同来源的手工节点属性可能单独有显著的偏差。这比传统数据带来了更多可观的领域转移。
问题2:如何减轻分类器的标签稀缺,以给出准确的标签鉴别预测?
由于目标图是完全未标记的,现有的工作只执行域对齐,而没有考虑到整体分布可能会很好地对齐,但类级分布可能不能很好地匹配分类器。更糟糕的是,源图只有一部分节点标签可用,阻碍了有效的分类器学习。因此,利用图的拓扑结构来提高分类器对未标记节点的鉴别能力是至关重要的。
贡献:
-
- 为了消除域位移交叉图,我们在源图编码上引入了域位移参数的概念,并提出了一个对抗性变换模块来学习域不变节点嵌入;
- 为了缓解标签的稀缺性,我们提出了一种新的伪标记方法,利用后验评分来监督未标记节点的训练,提高了模型在目标图上的识别能力;
- 在各种图形传输学习基准数据集上的大量实验证明了我们的SGDA优于最先进的方法。
3-方法
模型框架
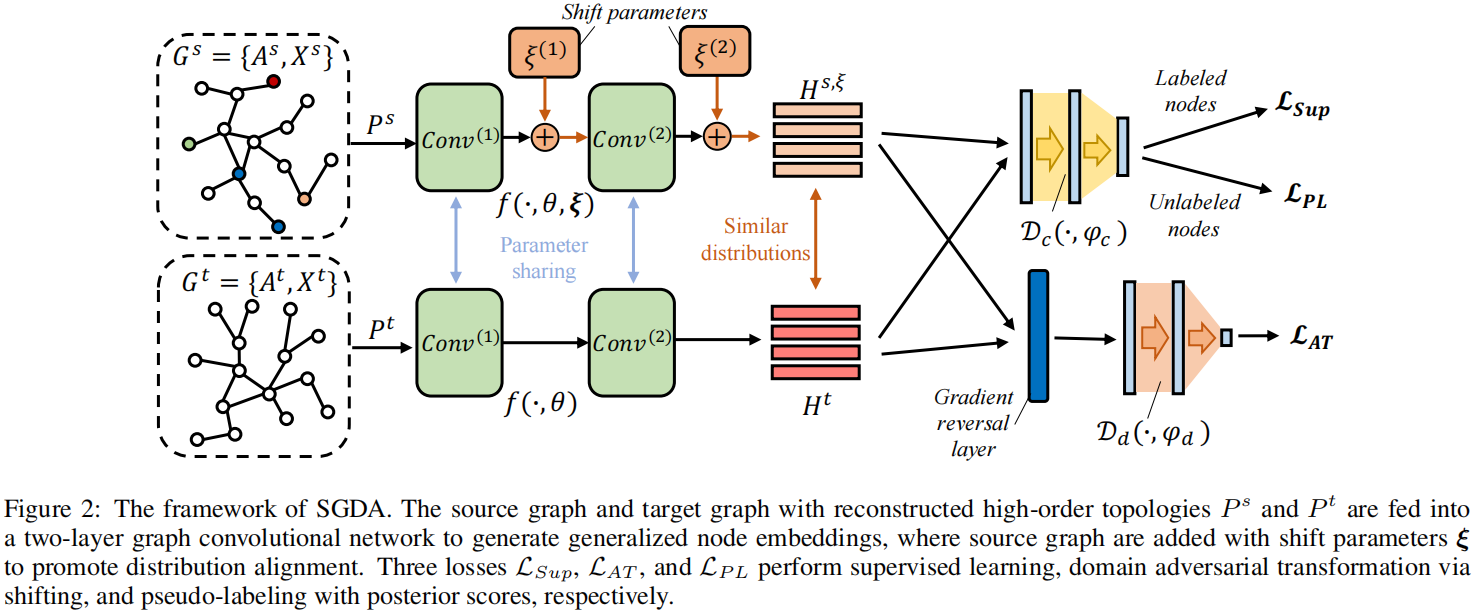
主要模块:
- 节点嵌入泛化。充分探索两个图中的高阶结构化信息,以学习广义节点表示;
- 对抗性转换。为了消除源图和目标图之间严重的域差异,我们在源图中引入自适应分布的位移参数,对域鉴别器以对抗的方式进行训练。因此,源图配备了目标分布。
- 使用后验评分的伪标记。为了缓解标签稀缺,我们提出了所有未标记节点跨域的伪标记损失,通过根据节点与类质心的相对位置自适应测量节点的影响,改进了对目标图的分类。
3.1 节点嵌入泛化
考虑到模型需要进行跨域转移,且分类任务中的标签数量有限,学习广义节点嵌入对于这种域自适应过程至关重要。鉴于此,我们计算了节点间的正点态互信息,以充分探索高阶无标记图拓扑信息,并使用图卷积网络将节点编码为广义低维嵌入。
给定图 $G=\{A, X\}$ ,在邻接矩阵 $A$ 上使用随机游走获得共现频率矩阵 $F \in \mathbb{R}^{N \times N}$,$F_{i j}$ 计算了节点 $n_j$ 出现在节点 $n_i$ 的上下文次数。
节点间的正互信息为:
$\begin{array}{c}\mathbb{P}_{i j}=\frac{F_{i j}}{\sum_{i, j} F_{i j}}, \mathbb{P}_{i}=\frac{\sum_{j} F_{i j}}{\sum_{i, j} F_{i j}}, \mathbb{P}_{j}=\frac{\sum_{i} F_{i j}}{\sum_{i, j} F_{i j}}, \\P_{i j}=\max \left\{\log \left(\frac{\mathbb{P}_{i j}}{\mathbb{P}_{i} \times \mathbb{P}_{j}}\right), 0\right\},\end{array} \quad(1)$
$P_{ij}$ 是 $n_i$ 和 $n_j$ 之间的正互信息,它反映了节点之间的高阶拓扑接近性,因为它假设如果两个节点有高频共现,则 $P_{ij}$ 应该大于预期独立的 $P_i$ 、$P_j$ 。
使用 $P_{ij}$ 作为新的邻接矩阵,得到节点表示:
$\begin{aligned}H^{(l)} & =\operatorname{Conv}^{(l)}\left(P, H^{(l-1)}\right) \\ & =\sigma\left(D^{-\frac{1}{2}} \widetilde{P} D^{-\frac{1}{2}} H^{(l-1)} W^{(l)}\right)\end{aligned} \quad(2)$
3.2 通过偏移实现对抗转换
大多数方法试图通过优化特征编码器本身来匹配嵌入空间分布。然而,具有非欧几里得拓扑结构的图通常比传统数据具有更大的输入差异。仅使用编码器中的参数(例如,gnn)可能不足以精细地改变分布。通过在输入空间上添加可训练参数(如传输、扰动)来执行转换已被证明可以有效地将一个分布转移到另一个分布。需要注意的是,我们提出了一个对抗性变换模块,其目的是在源图上添加移位参数来修改其分布,并使用对抗性学习来训练图编码器和移位参数来对齐跨域分布。
$H^{s,(l)}=\left\{\begin{array}{ll}\operatorname{Conv}^{(l)}\left(P^{s}, X^{s}\right)+\xi^{(l)} & l=1 \\\operatorname{Conv}^{(l)}\left(P^{s}, H^{s,(l-1)}\right)+\xi^{(l)} & 1<l \leq L\end{array}\right. \quad(3)$
对抗目标:
$\begin{array}{c}\underset{\theta, \boldsymbol{\xi}}{\text{max}} \left\{\min _{\phi_{d}}\left\{\mathcal{L}_{A T}\left(H^{s, \xi}, H^{t} ; \phi_{d}\right)\right\}\right\} \\\text { s.t., }\left\|\xi^{(l)}\right\|_{F} \leq \epsilon, \forall \xi^{(l)} \in \boldsymbol{\xi} .\end{array} \quad(4)$
$\begin{aligned}\mathcal{L}_{A T}= & -\mathbb{E}_{h_{i}^{s, \xi} \sim \mathcal{H}^{s, \xi}}\left[\log \left(\mathcal{D}_{d}\left(h_{i}^{s, \xi}, \phi_{d}\right)\right)\right] -\mathbb{E}_{h_{j}^{t} \sim \mathcal{H}^{t}}\left[\log \left(1-\mathcal{D}_{d}\left(h_{j}^{t}, \phi_{d}\right)\right)\right]\end{aligned} \quad(5)$
3.3 带有后验评分的伪标记
源域节点监督损失:
$\mathcal{L}_{\text {Sup }}=-\frac{1}{\left|\mathcal{V}^{s, l}\right|} \sum_{n_{i} \in \mathcal{V}^{s, l}} \sum_{k=1}^{C} y_{i, k} \log \left(p_{i, k}^{s}\right) \quad(6)$
对源域和目标域所有没有标签的节点计算伪标签:
我们假设图上靠近其伪标签簇的结构质心的节点更有可能被正确分类,而靠近簇边界的伪标签的节点则不太可靠。在此基础上,我们将前节点的伪标签视为更高质量的自监督信号,旨在提高这些节点嵌入的识别能力。因此,我们引入一个后验得分来定义 $n_i$ 如何接近其在第4.1节中计算的重构邻接矩阵P上的伪标签簇的结构质心:
$w_{i}=\sum_{j=1}^{N}\left(P_{i j} * P_{\mathcal{C}_{\widehat{y}_{i}}, j}-\frac{1}{C-1} \sum_{k=1, k \neq \widehat{y}_{i}}^{C} P_{i j} * P_{\mathcal{C}_{k}, j}\right) \quad(7)$
其中,$P_{\mathcal{C}_{\widehat{y}_{i}}, j}=\frac{1}{\left|\mathcal{C}_{\widehat{y}_{i}}\right|} \sum_{x \in \mathcal{C}_{\widehat{y}_{i}}} P_{x, j}$
然后,使用 余弦退火将 $w_i$ 扩展到固定的尺度:
$\widehat{w}_{i}=\alpha+\frac{1}{2}(\beta-\alpha)\left(1+\cos \left(\frac{\operatorname{Rank}\left(w_{i}\right)}{|\mathcal{V}|} \pi\right)\right) \quad(8)$
伪标签损失:
$\mathcal{L}_{P L}=-\frac{1}{|\mathcal{V}|} \sum_{n_{i} \in \mathcal{V}} \widehat{w}_{i} \sum_{k=1}^{C} \widehat{y}_{i, k} \log \left(p_{i, k}\right)+\sum_{k=1}^{C} \widehat{p}_{k} \log \widehat{p}_{k} \quad(9)$
3.4 训练目标
训练目标:
$\begin{array}{c}\underset{\theta, \boldsymbol{\xi}, \phi_{c}}{\text{min}}\left\{\mathcal{L}_{S u p}+\lambda_{1} \mathcal{L}_{P L}+\lambda_{2} \max _{\phi_{d}}\left\{-\mathcal{L}_{A T}\right\}\right\}, \\\text { s.t., }\left\|\xi^{(l)}\right\|_{F} \leq \epsilon, \forall \xi^{(l)} \in \boldsymbol{\xi}\end{array} \quad(10)$
4-实验
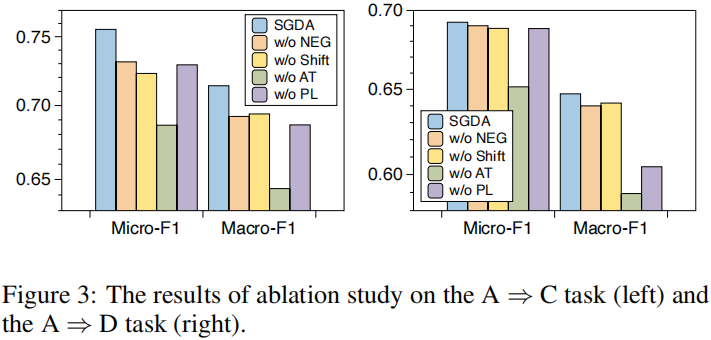
4.1 消融实验
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/18123655

