论文解读(UDA-GCN)《Unsupervised Domain Adaptive Graph Convolutional Networks》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Unsupervised Domain Adaptive Graph Convolutional Networks
论文作者:
论文来源:2020 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1-摘要
图卷积网络(GCNs)在许多与图相关的分析任务中都取得了令人印象深刻的成功。然而,大多数 GCN 只在一个域(图)中工作,无法将知识从其他域(图)转移,因为图表示学习和域适应方面的挑战。在本文中,我们提出了一种新的方法,无监督的域自适应图卷积网络(UDAGCN),为图的域自适应学习。为了实现有效的图表示学习,我们首先开发了一个对偶图卷积网络组件,它联合利用局部和全局一致性进行特征聚合。进一步利用注意机制为不同图中的每个节点生成统一的表示。促进图之间的知识转移,我们提出一个领域自适应学习模块优化三个不同的损失函数,即源分类器损失,域分类器损失,和目标分类器损失作为一个整体,因此我们的模型可以区分类标签在源域,样本来自不同的领域,类标签从目标领域。在节点分类任务中的真实数据集上的实验结果验证了该方法的性能,与目前最先进的图神经网络算法相比。
2-介绍
2.1 无监督节点分类域适应
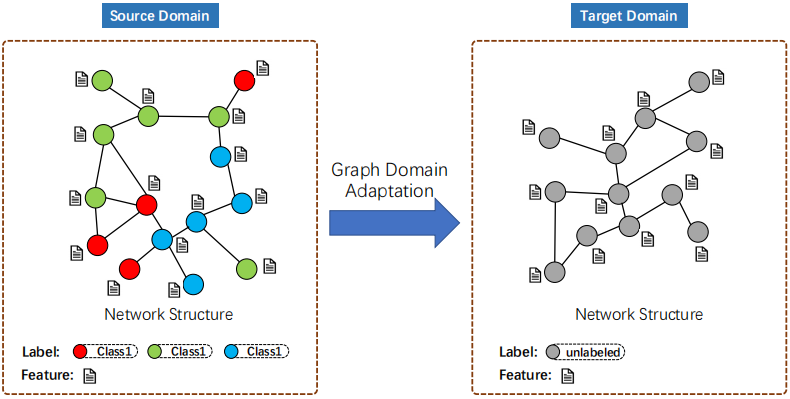
给定一个具有完全标记节点的源网络和一个没有任何标记数据的目标网络,无监督图域自适应的目标是利用源网络中丰富的标记信息,帮助为目标网络建立一个准确的节点分类器。
2.2 思考
现有无监督域适应方法为什么不适合在 Graph 数据上?
首先,这些领域适应方法通常是为 NLP 和 CV 领域的任务设计的, 其样本(图像、序列)是独立同分布的,对旋转不变形要求很低。然而,对于网格数据,其中节点与表示它们的关系的边连接,由于被称为图同构的现象,需要具有旋转不变性的模型。因此,现有的方法不能建模网络结构信息,这是节点分类的核心。
其次,大多数现有的领域自适应模型以有监督的方式学习判别表示,其中损失函数的值只与每个单个样本在其特征空间中的绝对位置相关联。另外,用于节点分类的网络表示通常是通过保持所有节点对的相对位置,以无监督的方式学习表示,从而增加了优化的难度。
2.3 现有工作
CDNE 算法通过最小化最大平均差异(MMD)损失来学习跨网络学习任务的可转移节点嵌入。但是,它不能联合建模网络结构和节点属性,这限制了其建模能力。为了利用网络结构进行跨网络节点分类,AdaGCN 使用图卷积网络作为特征提取器来学习节点表示,并利用对抗性学习策略来学习域不变节点表示。虽然联合利用 GCN 和对抗性学习来提高图形结构数据的跨域节点分类性能似乎是合理的。
缺点
- 数据结构层面:现有方法(GCN)只考虑了直接邻居(局部一致性)进行知识聚合,全局一致性没有得到充分的研究。在实践中,全局一致性关系是至关重要的。例如,在一个真实的社会网络中,每个人都是几个社区的成员,可以受到她/他的社区的影响,从地方一致性关系(如家庭、朋友)到全球一致性关系(如社会、民族国家)。因此,还应该利用全局一致性关系来获得协作图学习的节点的全面表示。
- 表示学习层面:如上所述,不能忽视全局一致性关系。因此,在我们的场景中,如何结合局部关系和全局关系来捕获节点的全面表示是至关重要的。理想情况下,这应该在端到端学习框架内完成。
- 领域适应层面:现有方法通过域标签减小域差异,并使用源标签训练分类器,但是忽略了目标域的语义信息。因此,应考虑源域信息、域信息和目标域信息的协同学习,以学习域不变性和语义表示。
2.4 本文
解决思路
- 数据结构层面:利用每个图的局部和全局一致性关系来帮助节点嵌入模块的训练。
- 表示层面:提出了一种基于互图的注意机制,将局部关系和全局关系结合起来,形成每个域的综合节点表示。
- 领域适应层面:提出一种领域自适应学习方法来联合利用源信息、域信息和目标信息,从而有效地学习域不变性和语义表示,以减少跨域节点分类的域差异。
贡献
- 本文提出了一种新的无监督图域自适应问题,并提出了一种有效的图卷积网络算法来解决它;
- 提出了一种新的方法,将局部和全局一致性与注意机制相结合,以学习网络有效节点嵌入;
- 设计了一种利用具有不同损失函数的源信息和目标信息的新方法,从而可以有效地学习域不变表示和语义表示,以减少跨域节点分类的域差异;
- 真实数据集上 SOTA 性能;
3-方法
3.1 模型框架
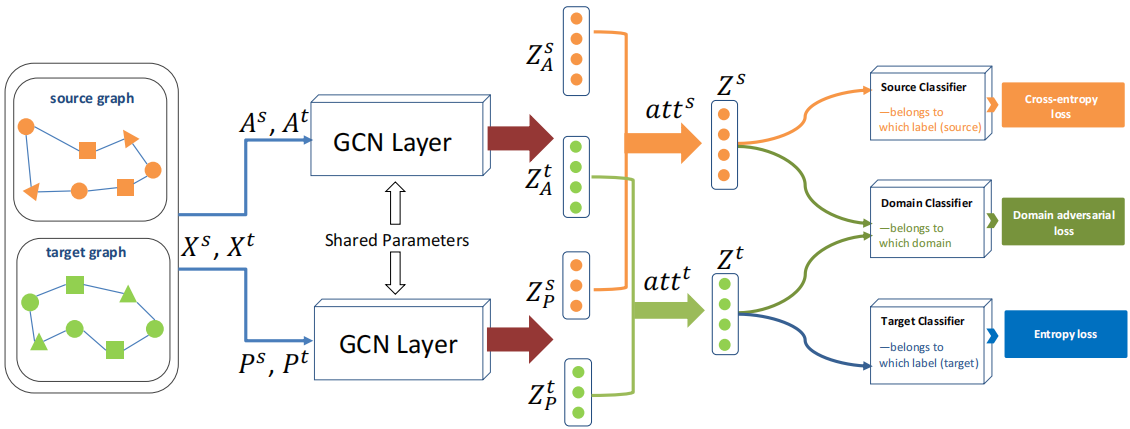
3.2 节点嵌入模块
捕获局部一致性:
$\operatorname{Conv}_{A}^{(i)}(X)=Z^{(i)}=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{\frac{1}{2}} Z^{(i-1)} W^{(i)}\right) \quad\quad(1)$
捕获全局一致性:
频率矩阵 $F$:
$p\left(s(t+1)=x_{j} \mid s(t)=x_{i}\right)=A_{i, j} / \sum_{j} A_{i, j} \quad\quad(2)$
点向互信息矩阵(PPMI):
$p_{i, j}=\frac{F_{i, j}}{\sum_{i, j} F_{i, j}} \quad \quad(3)$
$p_{i, *}=\frac{\sum_{j} F_{i, j}}{\sum_{i, j} F_{i, j}} \quad \quad(4)$
$p_{*, j}=\frac{\sum_{i} F_{i, j}}{\sum_{i, j} F_{i, j}} \quad \quad(5)$
$P_{i, j}=\max \left\{\log \left(\frac{p_{i, j}}{p_{i, *} p_{*, j}}\right), 0\right\} \quad \quad(6)$
全局关系消息传递:
$\operatorname{Conv}_{P}^{(i)}(X)=Z^{(i)}=\sigma\left(D^{-\frac{1}{2}} P D^{-\frac{1}{2}} Z^{(i-1)} W^{(i)}\right) \quad \quad(7)$
Note:应用基于这种节点-上下文矩阵 $P$ 的扩散可以确保全局一致性。
3.3 图间注意力
使用原始输入 $X^{s}$ 和 $X^{t}$ 作为注意机制的关键。然后对每个域输出($Z_{A}^{s}$、$Z_{P}^{s}$、$Z_{A}^{t}$、$Z_{P}^{t}$)进行注意,每个域分别计算两个注意系数 $a t t^{s}$ 和 $a t t^{t}$:
$a t t_{A}^{k}=f\left(Z_{A}^{k}, J X^{k}\right) \quad\quad(8)$
$a t t_{P}^{k}=f\left(Z_{P}^{k}, J X^{k}\right) \quad\quad(9)$
Note,$J$ 是一个共享的权重矩阵;
然后,进一步规范化权重 $a t t_k$。
$a t t_{A}^{k} =\frac{\exp \left(a t t_{A}^{k}\right)}{\exp \left(a t t_{A}^{k}+a t t_{P}^{k}\right)} \quad\quad(10)$
$a t t_{P}^{k} =\frac{\exp \left(a t t_{P}^{k}\right)}{\exp \left(a t t_{A}^{k}+a t t_{P}^{k}\right)} \quad\quad(11)$
在实现注意加权后,得到最终的输出 $Z^{s}$ 和 $Z^{t}$:
$Z^{s}=a t t_{A}^{s} Z_{A}^{s}+a t t_{P}^{s} Z_{P}^{s} \quad\quad(12)$
$Z^{t}=a t t_{A}^{t} Z_{A}^{t}+a t t_{P}^{t} Z_{P}^{t} \quad\quad(13)$
3.4 跨域节点分类中的域自适应学习
总体目标如下:
$\mathcal{L}\left(Z^{s}, Y^{s}, Z^{t}\right)=\mathcal{L}_{S}\left(Z^{s}, Y^{s}\right)+\gamma_{1} \mathcal{L}_{D A}\left(Z^{s}, Z^{t}\right)+\gamma_{2} \mathcal{L}_{T}\left(Z^{t}\right) \quad\quad(14)$
源分类器损失:
$\mathcal{L}_{S}\left(f_{s}\left(Z^{s}\right), Y^{s}\right)=-\frac{1}{N_{s}} \sum_{i=1}^{N_{s}} y_{i} \log \left(\hat{y}_{i}\right) \quad\quad(15)$
域分类器损失:
$\mathcal{L}_{D A}=-\frac{1}{N^{s}+N^{t}} \sum_{i=1}^{N^{s}+N^{t}} m_{i} \log \left(\hat{m}_{i}\right)+\left(1-m_{i}\right) \log \left(1-\hat{m}_{i}\right) \quad\quad(16)$
目标分类器损失:
$\mathcal{L}_{T}\left(f_{t}\left(Z^{t}\right)\right)=-\frac{1}{N^{t}} \sum_{i=1}^{N^{t}} \hat{y}_{i} \log \left(\hat{y}_{i}\right) \quad\quad(17)$
3.5 算法

报告的是最好的结果
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17702595.html
